






Scaling PostgreSQL to Power 800 Million ChatGPT Users
Confirming the role of this database engine in today's IT world
By Philippe Nicolas | January 28, 2026 at 2:00 pmBlog written by Bohan Zhang, member of the technical staff, Storadera published Jan. 22, 2026
Our efforts to advance our production infrastructure to sustain this growth revealed a new insight: PostgreSQL can be scaled to reliably support much larger read-heavy workloads than many previously thought possible. The system (initially created by a team of scientists at University of California, Berkeley) has enabled us to support massive global traffic with a single primary Azure PostgreSQL flexible server instance and nearly 50 read replicas spread over multiple regions globally. This is the story of how we’ve scaled PostgreSQL at OpenAI to support millions of queries per second for 800 million users through rigorous optimizations and solid engineering; we’ll also cover key takeaways we learned along the way.
It may sound surprising that a single-primary architecture can meet the demands of OpenAI’s scale; however, making this work in practice isn’t simple. We’ve seen several SEVs caused by Postgres overload, and they often follow the same pattern: an upstream issue causes a sudden spike in database load, such as widespread cache misses from a caching-layer failure, a surge of expensive multi-way joins saturating CPU, or a write storm from a new feature launch. As resource utilization climbs, query latency rises and requests begin to time out. Retries then further amplify the load, triggering a vicious cycle with the potential to degrade the entire ChatGPT and API services.
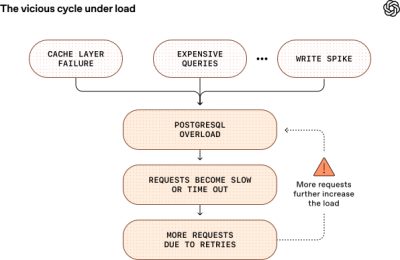
Although PostgreSQL scales well for our read-heavy workloads, we still encounter challenges during periods of high write traffic. This is largely due to PostgreSQL’s multiversion concurrency control (MVCC) implementation, which makes it less efficient for write-heavy workloads. For example, when a query updates a tuple or even a single field, the entire row is copied to create a new version. Under heavy write loads, this results in significant write amplification. It also increases read amplification, since queries must scan through multiple tuple versions (dead tuples) to retrieve the latest one. MVCC introduces additional challenges such as table and index bloat, increased index maintenance overhead, and complex autovacuum tuning. (You can find a deep-dive on these issues in a blog I wrote with Prof. Andy Pavlo at Carnegie Mellon University called The Part of PostgreSQL We Hate the Most.
Even as our infrastructure has evolved, PostgreSQL has remained unsharded, with a single primary instance serving all writes. The primary rationale is that sharding existing application workloads would be highly complex and time-consuming, requiring changes to hundreds of application endpoints and potentially taking months or even years. Since our workloads are primarily read-heavy, and we’ve implemented extensive optimizations, the current architecture still provides ample headroom to support continued traffic growth. While we’re not ruling out sharding PostgreSQL in the future, it’s not a near-term priority given the sufficient runway we have for current and future growth.
In the following sections, we’ll dive into the challenges we faced and the extensive optimizations we implemented to address them and prevent future outages, pushing PostgreSQL to its limits and scaling it to millions of queries per second (QPS).
To mitigate primary failures, we run the primary in HA mode with a hot standby, a continuously synchronized replica that is always ready to take over serving traffic. If the primary goes down or needs to be taken offline for maintenance, we can quickly promote the standby to minimize downtime. The Azure PostgreSQL team has done significant work to ensure these failovers remain safe and reliable even under very high load. To handle read replica failures, we deploy multiple replicas in each region with sufficient capacity headroom, ensuring that a single replica failure doesn’t lead to a regional outage.
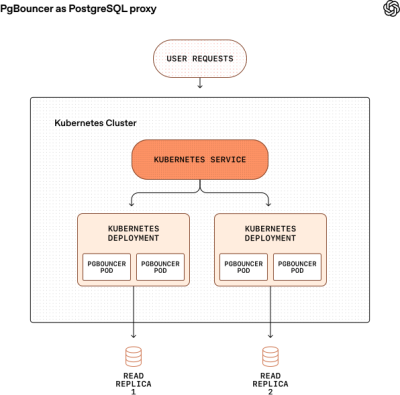 Each read replica has its own Kubernetes deployment running multiple PgBouncer pods. We run multiple Kubernetes deployments behind the same Kubernetes Service, which load-balances traffic across pods.
Each read replica has its own Kubernetes deployment running multiple PgBouncer pods. We run multiple Kubernetes deployments behind the same Kubernetes Service, which load-balances traffic across pods.
This scaling works while still minimizing latency and improving reliability. We consistently deliver low double-digit millisecond p99 client-side latency and five-nines availability in production. And over the past 12 months, we’ve had only one SEV-0 PostgreSQL incident (it occurred during the viral launch of ChatGPT ImageGen, when write traffic suddenly surged by more than 10x as over 100 million new users signed up within a week.)
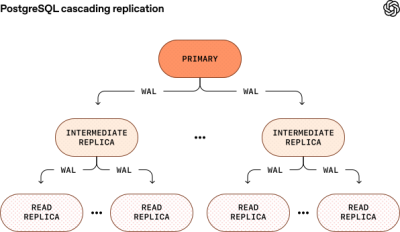
While we’re happy with how far PostgreSQL has taken us, we continue to push its limits to ensure we have sufficient runway for future growth. We’ve already migrated the shardable write-heavy workloads to our sharded systems like CosmosDB. The remaining write-heavy workloads are more challenging to shard – we’re actively migrating those as well to further offload writes from the PostgreSQL primary. We’re also working with Azure to enable cascading replication so we can safely scale to significantly more read replicas.
Looking ahead, we’ll continue to explore additional approaches to further scale, including sharded PostgreSQL or alternative distributed systems, as our infrastructure demands continue to grow.



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter


