







IT Press Tour 68: Paradigm4
Developing flexFS, an alternative high performance file storage with S3 back-ends
By Philippe Nicolas | June 16, 2026 at 2:01 pmWe had the opportunity to meet Paradigm4 for the 1st time during the recent 68th edition of The IT Press Tour held last week in Boston, MA.![]() Marilyn Matz, CEO, Paradigm4, introduced the company with Gary Planthaber, CTO, Andy Cosgrove, CRO, and David Freund, technical sales partner for flexFS. It worth noticing that the company has been co-founded by Michael Stonebraker, professor at MIT, is also famous to have initiated Ingres, Postgres, C-Store, Tamr or VoltDB among other things.
Marilyn Matz, CEO, Paradigm4, introduced the company with Gary Planthaber, CTO, Andy Cosgrove, CRO, and David Freund, technical sales partner for flexFS. It worth noticing that the company has been co-founded by Michael Stonebraker, professor at MIT, is also famous to have initiated Ingres, Postgres, C-Store, Tamr or VoltDB among other things.
Originated in life sciences analytics, the company built flexFS internally after failing to find an affordable POSIX file system capable of delivering tens to hundreds of GB/s in the cloud: JuiceFS, ObjectiveFS, S3FS, Goofys, S3Backer, AWS EFS and FSx for Lustre were all evaluated, but open-source options lacked throughput and full POSIX support while commercial offerings (Lustre, DDN, Weka, FSx) priced themselves out for genomics-budget customers. flexFS, now at v1.9 with a free Community Edition offering 5TB against the user’s own S3 bucket, was eventually productized and spun out to address industries beyond life sciences as it appears to be very generic. The thesis is that the typical AI stack has cracks in its foundation: most workloads speak POSIX while object storage offers the economics, leaving a gap that taxes every workload through GPU idle time, slow pipelines and over-provisioned file systems.
Click to enlarge

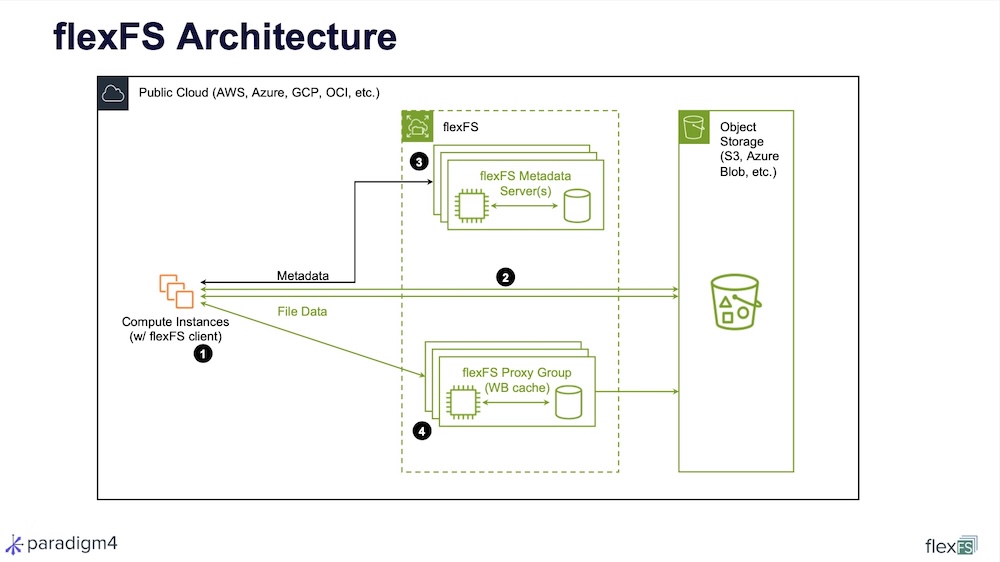
Architecturally, flexFS is positioned as an “object-native parallel filesystem” rather than a lift-and-shift of datacenter parallel storage. Files are sharded into chunks, each assigned an object ID and stored directly in hyperscale object storage (S3, Azure Blob, GCS, OCI), letting the hyperscaler handle parallel access while flexFS’s own persistent low-latency metadata server eliminates object-store metadata latency. An optional Proxy Group acts as a CDN-style write-back cache, supporting fractional caching (e.g., cache the first 100 blocks per file, bypass for larger ranges). Supported configurations span single-region cloud, multi-region/multi-cloud, on-premises, hybrid and converged (storage services co-resident on compute nodes), with Oracle/Paradigm4 jointly demonstrating near-local-NVMe performance on OCI. Operations features include deduplication via hard links with checksum and byte-for-byte validation, a metadata-server-driven optimized find utility, non-disruptive updates (server pauses under 1 second, mount clients auto-update via FUSE session handoff) and a Kubernetes CSI driver with Helm chart. The platform is ISO 27001 certified, delivers 11 nines durability and is positioned as a drop-in replacement for EFS, FSx for Lustre, OCI File Storage, GC Filestore and Azure Files.
Click to enlarge
Enterprise customers include J&J, Bristol Myers Squibb, Amgen, Alnylam, SiteTx and GeneDx. A Top-5 global pharma case study covering September 2022 to March 2026 (43 months) at 1.14PB and over 160 million files reports actual flexFS+S3 spend of $2.53 million versus a modelled AWS provisioned alternative (25% FSx Lustre Persistent_2 SSD at $0.170/GB-mo, 40% EFS Standard Regional at $0.300, 10% EBS gp3, 25% S3 Standard at $0.023) of $5.65 million, cumulative savings of $3.13 million (55%), 2025 full-year savings of $1.44 million (59%), March 2026 monthly run-rate of $110K versus $274K, and approximately $332K of Lustre over-provisioning waste eliminated. The effective rate fell from roughly $90/TB-month at 25 TB in 2022 to $66/TB-month at 1.14 PB in 2026, against flat $307/TB-mo (EFS) and $174/TB-mo (FSx) competitors. Newer workloads include data lakehouse acceleration (TPC-H at scale factor 100 with Spark+Gluten ran in 176s on cached flexFS versus 1,191s on S3, a 6.8x gain), coupled-architecture DBMS modernization (MPP DW, graph, vector, up to 60% TCO reduction with no code changes), AI/ML training and checkpointing (PyTorch, TensorFlow, JAX) and agentic AI workspaces with POSIX scratchpads, byte-range I/O on large PDFs and point-in-time recovery to undo rogue agent deletions.
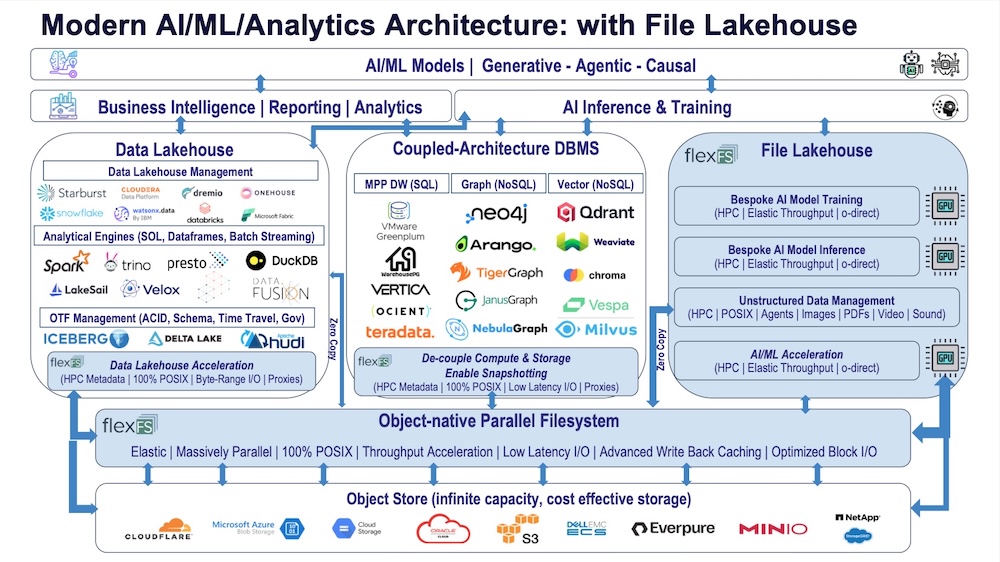
Paradigm4 is canvassing the press tour on whether to formalise a “File Lakehouse” category alongside Data Lakehouse and Coupled-Architecture DBMS in modern AI/ML/analytics reference architectures.
Click to enlarge



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter


