






Recap of the 64th IT Press Tour in New-York, NY, USA
With 7 companies: Arcitecta, AuriStor, CTera, ExaGrid, HYCU, Shade.inc and TextQL
By Philippe Nicolas | November 13, 2025 at 2:00 pmThe 64th edition of The IT Press Tour was recently organized at big apple, we mean New-York city, NY. The event served as a productive platform for the press group and participating organizations to engage in in-depth discussions on IT infrastructure, cloud computing, networking, cybersecurity, data management and storage, big data and analytics, and the broader integration of AI across these domains. Seven companies joined that edition, listed here in alphabetical order: Arcitecta, AuriStor, CTera, ExaGrid, HYCU, Shade.inc and TextQL.
![]()
Arcitecta
Arcitecta’s presentation showcases Mediaflux as a comprehensive, unified data management platform designed to address the rapidly growing scale, complexity, and fragmentation of modern data environments. The company outlines its strategic direction, recent customer successes, and the evolution of Mediaflux as a converged system that integrates orchestration, storage, metadata, access, and AI readiness into a single fabric.
Mediaflux enables organizations to ingest, manage, move, analyze, and preserve data across on-prem systems, cloud platforms, and globally distributed sites. Its architecture features a powerful policy engine that automates data lifecycle management – from active storage through long-term archival – and supports multi-protocol access including NFS, SMB, S3, and SFTP. The platform is fully vendor-agnostic, giving customers the freedom to mix storage hardware from NetApp, Dell, IBM, cloud object stores, and tape without lock-in.
Key advanced capabilities include compute-to-data workflows, a world-class metadata engine, and Livewire WAN acceleration, which enables data transfers at up to 95% of link capacity. Mediaflux also incorporates a next-generation vector-aware metadata database (XODB) that supports semantic search, AI pipelines, RAG models, and virtual data hierarchies. Together, these capabilities allow Mediaflux to function as an AI-ready data fabric that gives applications and researchers a unified, intelligence-rich view of all enterprise data.
Customer case studies reinforce these strengths. Princeton’s TigerData program uses Mediaflux to manage 200PB of research data while building a 100-year preservation model that spans multiple tiers of storage, from high-performance compute environments to tape-based archives. Dana-Farber Cancer Institute leverages Mediaflux to unify siloed systems, automate archiving, migrate to cloud and tape, and streamline researcher workflows. TU Dresden and IWM demonstrate improvements in collaboration, discoverability, automation, cost reduction, and long-term preservation.
Arcitecta also highlights Datakamer, a growing community focused on data management best practices, with future events planned globally. The roadmap includes expanded vector database capabilities, deployment automation tools, DAMS upgrades, and enhanced stability.
Overall, Mediaflux is presented as a future-proof, AI-ready, end-to-end platform built to simplify data management, eliminate silos, accelerate collaboration, and help organizations keep pace with exponential data growth.
Click to enlarge

Auristor
AuriStor, founded in 2007, is a technology-first, fully remote company that develops AuriStorFS, a next-generation, high-security, high-performance distributed file system descended from AFS and OpenAFS. After the free OpenAFS ecosystem proved unsustainable, the team pivoted to a closed-garden model, leading to major performance, reliability, and security advancements. Their first major commercial success came in 2016, when a global financial institution licensed AuriStorFS to eliminate costly outages—eventually deploying it worldwide and across multi-cloud environments.
AuriStor licenses software only; it does not host storage. Every deployment is unique, spanning finance, defense, research universities, HEP labs, and government agencies. The company maintains deep partnerships with Red Hat, SUSE/Cray, Microsoft, LINBIT, TuxCare, and others, and supports a wide range of Linux distributions, macOS, Solaris, and specialty HPC operating systems.
AuriStorFS preserves the /afs namespace and enables seamless migration from legacy AFS environments without flag days, maintaining decades-old data. Its pricing model is unusual: costs are based on servers and protection entities—not data volume, raw storage, or CPU cores—and includes a perpetual-use license.
Since 2022, AuriStor has produced more than 40 patch releases, adding support for new platforms, enhancing compatibility with Linux’s in-tree kafs module, and delivering improvements in RX RPC networking, call termination, and large-scale fileserver shutdown. These changes massively reduce latency, increase throughput (up to 450% improvement on 10+ Gbit links), and enable rapid restart of fileservers with millions of volumes.
Major enhancements include a Volume Feature Framework enabling per-volume capabilities, expanded volume dump formats, OverlayFS whiteout support, and advanced selective acknowledgements for RX. AuriStor also invests heavily in keeping pace with rapid Linux kernel changes, splitting components into GPL and non-GPL modules to remain compatible.
AuriStorFS excels at global, secure, replicated content distribution; cross-platform home/project directories; open-science collaboration; and large distributed compute farms. It is less suited for VM images or databases until future byte-range locking features are added. Use cases include SLAC’s global research workflows, USGS’s real-time hazard data distribution, and massive multinational software-distribution infrastructures scaling to 175,000+ clients, 80+ cells, and millions of volumes.
Looking forward, AuriStor is advancing RX congestion control, Unicode directory support, deeper container-orchestration integration, and boot-from-AFS capabilities—positioning AuriStorFS for HPC, hybrid cloud, and next-generation distributed computing.
Click to enlarge

CTERA
CTERA’s presentation outlines its vision for transforming enterprise data from fragmented, unstructured chaos into an intelligent, AI-ready asset through a unified, secure, globally distributed data fabric. As a leader in hybrid cloud and distributed file systems, CTERA serves large enterprises and government agencies with a software-defined platform that connects edge sites, data centers, and clouds without compromising performance or security.
The company highlights strong growth metrics – 35% annual growth, 125% net retention, and a 90% partner-driven model—alongside industry leadership recognized by GigaOm, Frost & Sullivan, and Coldago. IT leaders’ top 2025 priorities – cybersecurity, AI strategy, and data growth – frame the need for CTERA’s approach.
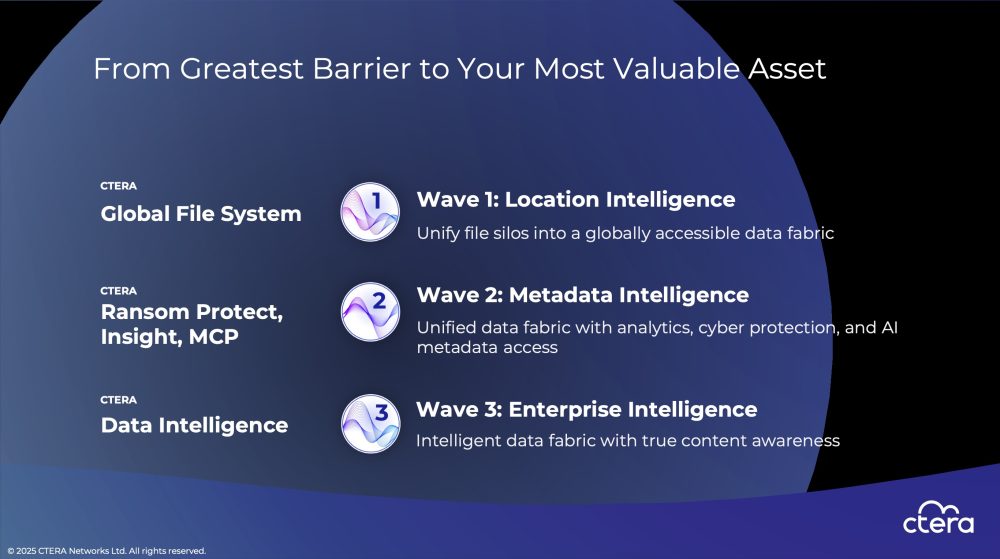
CTERA explains a three-wave innovation journey:
- Wave 1: Location Intelligence unifies silos across cloud, data center, and edge through a global namespace and object-native backend, enabling scalable hybrid cloud storage, high-performance cached edge access, and seamless NAS migration. Hybrid storage adoption is driven by efficiency, resiliency, productivity, and AI requirements.
- Wave 2: Metadata Intelligence turns this unified fabric into a secure data lake. Metadata analytics drive operational insight, automation, and cyberstorage capabilities. Immutable snapshots, block-level anomaly detection, and activity monitoring protect against ransomware. Newly launched products include Ransom Protect (AI-based anomaly detection), Insight (360° operational visibility), and MCP (LLM-powered natural-language file interaction).
- Wave 3: Enterprise Intelligence elevates the data lake into a strategic AI asset. CTERA stresses that GenAI success depends on high-quality, curated data—not simply vectorizing everything. The platform enables timely ingestion, metadata enrichment, unified formats, filtering, and secure vectorization. With a semantic retrieval layer and permission-aware controls, organizations can create “virtual employees”—AI agents operating safely on curated enterprise data.
Use cases span public sector, financial services, healthcare, retail, industrial design, and federal defense. Case studies show CTERA enabling edge processing for naval fleets and real-time global collaboration for creative agencies. A medical law firm demonstrates how CTERA’s MCP and intelligence layer accelerate document analysis with trustworthy AI.
CTERA positions its intelligent data fabric as the foundation for secure, scalable AI adoption—transforming distributed data into an enterprise’s most valuable asset.
Click to enlarge
ExaGrid
ExaGrid presents itself as the largest independent vendor dedicated exclusively to backup storage, with 17+ years in the market, over 4,800 global customers, and strong financial performance—19 consecutive cash-positive quarters, no debt, and double-digit growth. The company holds the industry’s highest Net Promoter Score (+81) and has earned more backup-storage awards than any competitor. Its appliances are certified in 132 countries and widely deployed across government, healthcare, finance, retail, manufacturing, and enterprise IT.
ExaGrid’s message centers on its Tiered Backup Storage architecture, the only approach purpose-built for backup workloads. Unlike standard disk or inline-deduplication appliances, ExaGrid separates a high-performance landing zone (for fast ingest, fast restores, and instant VM boots) from a deduplicated, non-network-facing repository tier, creating an immutable, air-gapped backup environment. This design eliminates the performance penalties of inline dedupe, avoids rehydration during restores, and ensures a fixed-length backup window via scale-out expansion.
The market is shifting as backup software vendors (Veeam, Rubrik, Commvault, Cohesity/NetBackup) decouple storage and encourage customers to choose their own hardware, opening opportunities for ExaGrid. Customers typically reevaluate backup storage during capacity expansions, hardware refreshes, app changes, cost reduction efforts, SLA failures, or broken backup/recovery workflows.
ExaGrid emphasizes four requirement pillars: Backup & Recovery (fast ingest, data integrity, resilience, and rapid VM/database restores), Business Continuity (redundancy, security, DR), Cost of Ownership (deduplication savings, no forklift upgrades, low power/cooling, price protection), and Proactive Support (assigned L2 engineers, in-theater support, monitoring).
Security is a major differentiator. The repository tier is immutable, isolated, and protected by delayed deletes, encryption, RBAC, 2FA, TLS, and AI-powered Retention Time-Lock. ExaGrid meets DORA, GDPR, NIS2, and Common Criteria requirements. The architecture provides strong ransomware recovery, alerting on deletions and dedupe-ratio anomalies.
ExaGrid integrates deeply with leading backup applications, delivering accelerated ingest, improved dedupe ratios (up to 15:1), faster synthetic fulls, global deduplication, and 6PB full backup support in a single system. Advanced DR options span secondary data centers, colocation sites, and cloud providers (AWS, Azure) with 50:1 WAN bandwidth efficiency.
Recent announcements include support for MongoDB Ops Manager, Rubrik archive tier, TDE-encrypted SQL dedupe, and upcoming AI-powered RTL enhancements. An all-SSD appliance line arrives in late 2025, with Cohesity support in 2026.
ExaGrid positions itself as the performance-leader and security-leader in backup storage—purpose-built, cost-efficient, and resilient against ransomware, with unmatched support and scalability.
Click to enlarge

HYCU
HYCU’s presentation focuses on delivering resilient recovery across SaaS, cloud, hybrid, and emerging AI workloads. With more than 4,600 organizations protected in 78 countries, HYCU highlights major advances since the previous briefing: expansion into 25+ new hypervisors, SaaS apps, and cloud services; new integrations such as DD Boost for SaaS, deeper Dell ecosystem support, and sovereign, malware-resistant data protection for more than 90 integrations.
The company frames modern resiliency challenges through rising user error, automation mistakes, insider threats, cyberattacks, and supply-chain compromises. HYCU’s 2025 State of SaaS Resilience Report shows SaaS adoption rising sharply while security incidents are widespread, with GitHub, Jira, iManage, and other platforms exposing major data-loss gaps. Mission-critical data increasingly lives in SaaS, yet most backup vendors protect only a handful of apps and rely on fragmented consoles and vendor-controlled storage.
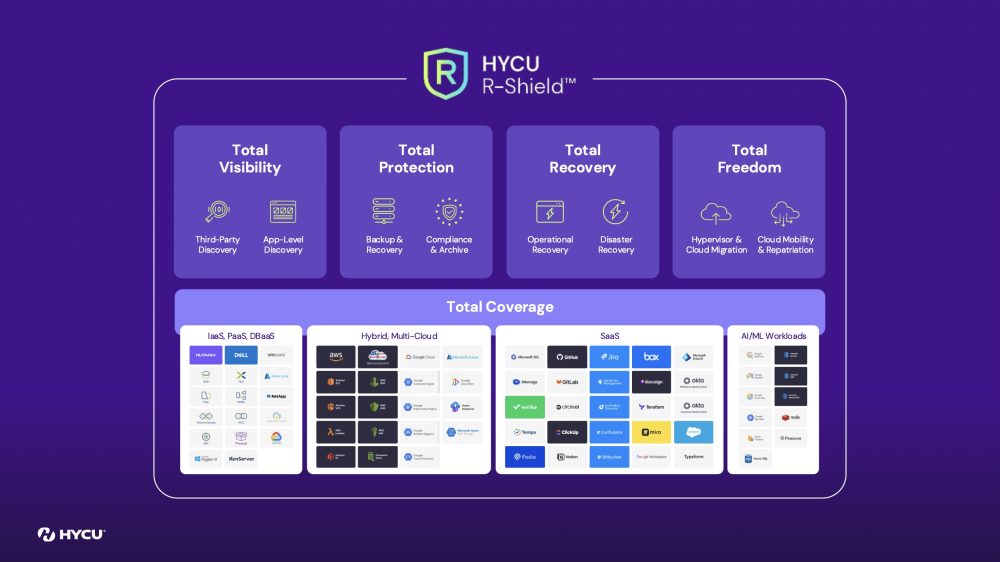
HYCU positions itself as offering the broadest SaaS and cloud workload coverage, delivering Total Coverage across IaaS, PaaS, DBaaS, SaaS, hybrid cloud, and AI/ML workloads. HYCU R-Cloud enables app-aware discovery, granular recovery, DR, offline recovery, cloud mobility, and compliance workflows, all using customer-owned storage—ensuring sovereignty, eliminating vendor lock-in, and enabling immutable, object-locked backups.
A major theme is resiliency for SaaS and AI-powered applications. HYCU introduces SaaS disaster recovery, data seeding, and offline recovery to guarantee access even during prolonged SaaS outages or supply-chain incidents. The platform also tackles cloud-native risks: fragmentation, blind spots (DBaaS, AI/ML pipelines), and soaring object-storage and egress costs. HYCU’s Lakehouse protection provides atomic backups, cross-project recovery, immutability, and coverage for models, vectors, routines, and access policies—addressing the growing importance of cloud data lakes and AI training assets.
The R-Shield cyber-resilience suite adds anomaly detection across hybrid, SaaS, and cloud workloads; high-performance malware scanning performed at the data source (not in vendor planes); intelligent tagging; and full data sovereignty. R-Lock enforces immutable, customer-owned backups that meet 3-2-1-1-0 requirements.
HYCU concludes by emphasizing its extensible, security-first platform; customer choice in storage and architecture; and leadership validated by GigaOm, which positions HYCU R-Cloud as a Leader and Fast Mover in innovation, cross-cloud mobility, and protection of next-generation workloads.
Click to enlarge
Shade.inc
Shade positions itself as the modern storage and workflow platform built for the exploding demands of creative production. As file sizes surge—driven by high-resolution video, global collaboration, and GenAI—creative teams are overwhelmed by slow legacy tools like Dropbox, Box, Google Drive, Frame.io, and LucidLink. Customer quotes highlight severe issues: multi-hour downloads, lost access to decades of footage, storage revocations, account shutdowns, poor Premiere performance, and a fragmented stack that forces creatives to re-upload assets across 5–7 different systems.
The presentation describes a universal pain point: every company has become a creative production company, yet creative directors now spend more time managing files than making content. Teams lack a single source of truth, frequently duplicate uploads, lose track of where files live, and suffer from inconsistent permissions, siloed review processes, and slow transfers—especially across global teams. A typical workflow involves 100+ hours of downloading, re-uploading, re-archiving, and stitching together tools like Frame.io, Air, LucidLink, Dropbox, and physical drives.
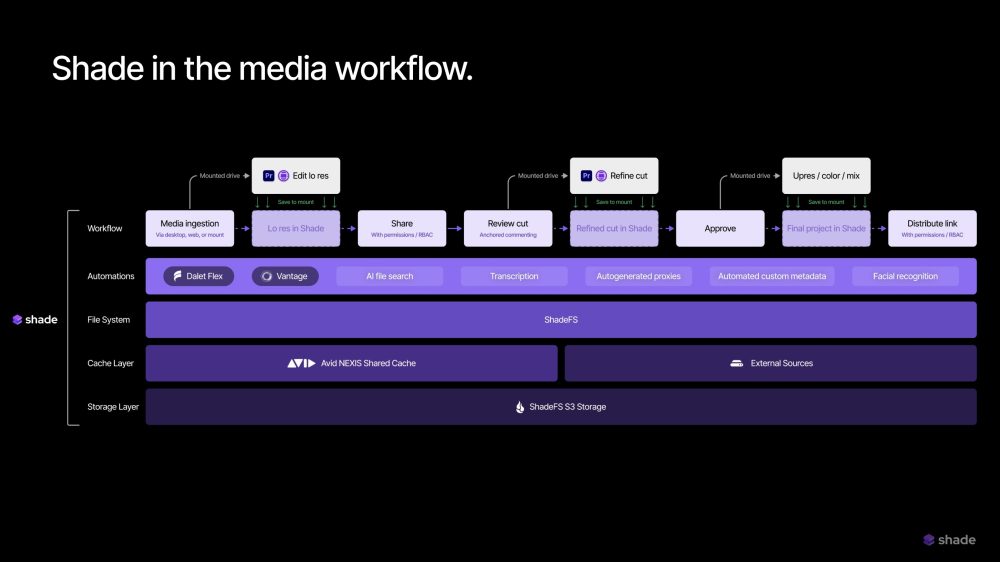
Shade proposes an integrated solution: an intelligent cloud NAS with real-time file streaming, complex previews, built-in review and markup, facial recognition, semantic search, AI autotagging, transcription, transcoding, version control, and custom metadata. The workflow becomes unified: upload once, mount via Shade Drive, edit with streaming performance, share via secure links, and distribute or archive—all from one platform.
The efficiency gains are dramatic. AI autotagging reduces 200 hours of manual logging to a minute; semantic search finds multi-year-old assets in seconds; 4K ProRes files stream instantly; multi-hundred-GB transfers complete immediately instead of requiring physical hard-drive shipments. Shade replaces fragmented stacks and cuts customer costs by 55–70% across SMB, corporate, sports, and media markets. Real customer examples show spend dropping from $80K to $25K, $170K to $70K, and $500K to $150K annually.
Testimonials from Salesforce, Lennar, TEAM, and others underscore faster workflows, accurate AI features, and the value of having one definitive content system. Looking ahead to 2026, Shade plans advanced automations, integrations, Shade Vault, and API-driven workflows that connect creative content with business systems—extending Shade from creative teams to the entire enterprise.
Click to enlarge
TextQL
TestQL provides a comprehensive and automated approach to testing SQL queries, data transformations, and full data pipelines, replacing the manual, inconsistent, and error-prone methods that many organizations still rely on. As data ecosystems expand across warehouses, lakes, real-time systems, and AI workflows, SQL logic becomes increasingly complex and must remain accurate despite constant schema changes, new data sources, and rapid iteration. TestQL brings engineering-grade discipline to SQL by enabling teams to write tests for query logic, expected outputs, edge cases, performance behavior, and data quality rules, and then automate those tests within CI/CD pipelines so issues surface before they reach production.
By introducing consistency and repeatability, TestQL greatly increases trust in analytic outputs, dashboards, AI features, and business reports, reducing the risk of silent data corruption or broken transformations. It accelerates development by removing the need for analysts and engineers to manually re-run queries or validate results each time code changes. Teams gain shared visibility into test results, failures, regressions, and data-quality trends, improving collaboration between data engineering, analytics, operations, and governance groups. TestQL also enhances auditability and compliance by maintaining detailed histories of test configurations, results, version changes, and execution context, making it easier to trace how critical datasets and SQL components evolve over time.
As organizations scale to hundreds or thousands of pipelines, queries, models, and dashboards, manual testing becomes impossible. TestQL meets this challenge by orchestrating broad, automated test coverage that adapts to growing data estates and increasingly complex logic. It supports modern cloud data platforms and provides a unified structure that helps teams detect anomalies, validate assumptions, and ensure outputs remain correct even as business rules, schemas, and workloads shift. In a world where data accuracy directly impacts revenue, decision-making, and AI reliability, TestQL transforms SQL testing into a systematic, proactive, and dependable practice that strengthens the entire data lifecycle.




 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter


