







YanRong Excels in MLPerf Storage v2.0 Benchmark
Achieves leading results with fast storage for AI training and inference
This is a Press Release edited by StorageNewsletter.com on September 11, 2025 at 2:00 pmIn the latest MLPerf Storage v2.0, a 3-node YanRong all-flash F9000X cluster – the minimum viable scale for distributed storage – set a new global performance record in the UNet3D test, achieving 513GB/s of bandwidth on commodity hardware.![]() YanRong Tech is proud to participate in the MLPerf Storage v2.0 benchmark suite – an industry-standard evaluation designed to assess storage system performance for machine learning (ML) workloads in an architecture-neutral, representative, and reproducible way. Building on our strong showing in last year’s MLPerf Storage v1.0, the v2.0 results once again validate YanRong’s ability to accelerate large-scale AI workloads and drive optimal GPU utilization.
YanRong Tech is proud to participate in the MLPerf Storage v2.0 benchmark suite – an industry-standard evaluation designed to assess storage system performance for machine learning (ML) workloads in an architecture-neutral, representative, and reproducible way. Building on our strong showing in last year’s MLPerf Storage v1.0, the v2.0 results once again validate YanRong’s ability to accelerate large-scale AI workloads and drive optimal GPU utilization.

MLPerf Storage v2.0 Benchmark Shows Rapid Innovation in Support of Larger-scale Training Systems
Continuing from the v1.0 benchmark suite, the MLPerf Storage v2.0 suite measures storage performance in a diverse set of ML training scenarios, including 3D-Unet, ResNet50, and CosmoFlow. It emulates the storage demands across several scenarios and system configurations covering a range of accelerators, models, and workloads.
The benchmark focuses the test on a given storage system’s ability to keep pace, as it requires the simulated accelerators to maintain a required level of utilization. Results from v2.0 show that storage systems performance continues to improve rapidly, with tested systems serving roughly twice the number of accelerators than in the v1.0 benchmark round.
Additionally, the v2.0 benchmark adds new tests that replicate real-world checkpointing for AI training systems. The benchmark results provide essential information for stakeholders who need to configure the frequency of checkpoints to optimize for high performance – particularly at scale.
YanRong’s Results Demonstrate World-Leading Performance in Minimum-Scale Storage Cluster
At the heart of YanRong’s achievement is YRCloudFile, a high-performance distributed parallel file system specifically designed to meet the demanding I/O needs of AI model training, inference, and HPC environments. Powered by YRCloudFile, our F9000X all-flash storage appliance delivers exceptional bandwidth, ultra-low latency, and linear scalability.
benchmark, each F9000X storage node was equipped with the latest Intel Xeon 5th Generation Scalable Processors, utilizing domestically manufactured PCIe 5.0 NVMe SSDs, along with 4 NVIDIA ConnectX-7 400Gbps InfiniBand network cards. Network topology of the test environment is shown below:
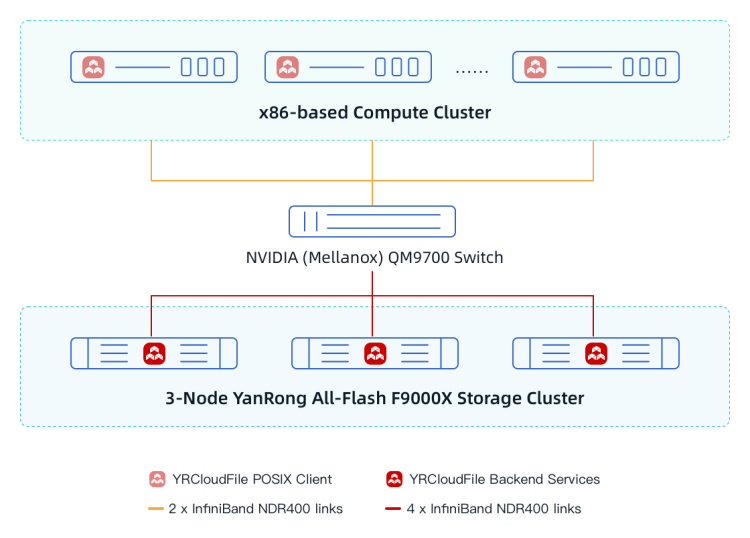
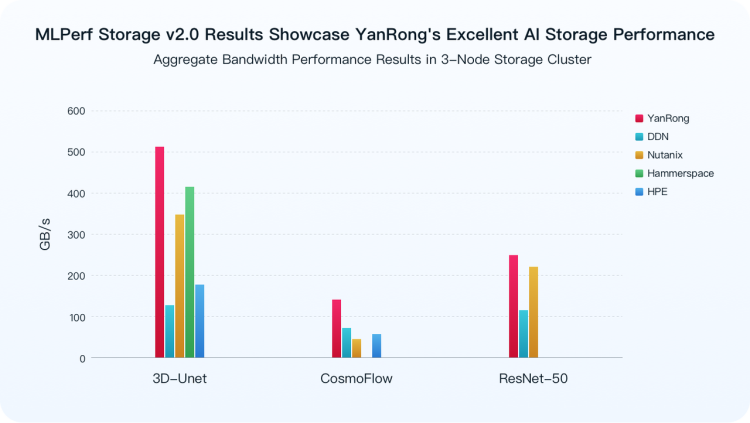
Here are some standout results from the benchmark tests, showcasing how YanRong storage performed across different environments:
- 3D-Unet
- Single client: 87 GB/s aggregate throughput driven by 30 H100 accelerators
- 8 clients: 513 GB/s aggregate throughput driven by 176 H100 accelerators
- CosmoFlow
- Single client: 38 GB/s aggregate throughput driven by 68 H100 accelerators
- 9 clients: 137 GB/s aggregate throughput driven by 243 H100 accelerators
- ResNet50
- Single client: 42 GB/s aggregate throughput driven by 220 H100 accelerators
- 9 clients: 259 GB/s aggregate throughput driven by 1404 H100 accelerators

Best-in-Class Performance in Minimum-Scale Cluster
Designed with rigorous and transparent methodology, the MLPerf Storage benchmark provides a comprehensive assessment of real-world storage capabilities in AI training workloads. It evaluates both single-client and distributed cluster configurations, emphasizing the aggregate bandwidth a storage system can deliver while maintaining high GPU utilization – a critical factor in preventing idle compute cycles and maximizing performance.
In MLPerf Storage v2.0, YanRong’s all-flash F9000X demonstrated best-in-class performance across all three benchmarked models – 3D-Unet, ResNet50, and CosmoFlow – within a minimal three-node distributed cluster on commodity hardware. Notably, it achieved 513 GB/s of aggregate bandwidth in the 3D-Unet test, setting a new global record.
High-Performance Checkpointing for LLM Training
YanRong’s storage system also delivered outstanding results in the newly added Checkpoint workload. In the Llama3-70B scenario, the F9000X sustained 221 GB/s read and 79 GB/s write bandwidth with 8 clients and 64 simulated GPUs.
This level of stable, high-throughput performance enables checkpoint files to be read and written in seconds, ensuring minimal disruption in the event of training interruptions. It lays a strong foundation for reliable recovery and continuity in long-running large language model (LLM) training processes.
The Optimal Choice for AI Workloads
YanRong Storage’s exceptional benchmark results reflect more than just raw performance – they demonstrate our proven ability to support AI training and inference at real-world scale.
This capability stems from our deep expertise in AI storage. Through years of focus on demanding workloads, we’ve developed a nuanced understanding of AI workload behaviors. At the same time, we’ve consistently advanced architectural innovation and executed end-to-end optimizations across the full software and hardware stack, building a robust foundation for high-performance, data-intensive applications.
These strengths position YanRong to lead in the next wave of AI innovation, where model complexity and scale continue to grow and place unprecedented demands on high-performance storage.
As AI evolves, YanRong remains a critical enabler – delivering storage solutions that combine performance, scalability, and efficiency to power the future of AI.



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter


