





Hammerspace Announces MLPerf v2.0 Benchmark Results, Demonstrates Tier 0 Advantages
Confirming a different approach that protects storage investment
By Philippe Nicolas | August 14, 2025 at 2:01 pm This is blog post available on Hammerspace web site written by Dan Duperron, 8/5/2025.
This is blog post available on Hammerspace web site written by Dan Duperron, 8/5/2025.
Hammerspace Announces MLPerf v2.0 Benchmark Results, Demonstrates the Simplicity, Performance, and Efficiency of Tier 0
Tech industry benchmarks are interesting things. Some seem designed mostly for winners to brag to their industry buddies and the press. Like a drag race, where straight-line speed in the quarter mile is all that counts. Those are fun but not really useful, because nobody lives exactly ¼ mile from the grocery store down a straight, flat, empty road.
The benchmarks that are useful to AI and infrastructure architects are the ones that simulate real-world workloads. A little highway driving, some low speed around town stuff, trailer towing, etc. This is why we like the MLCommons MLPerf Storage benchmark suite and are actively involved in efforts to expand and improve it. MLPerf Storage simulates a variety of realistic AI/ML workloads. The results provide relevant data points for organizations evaluating storage architectures for AI.
Let’s review the results, then I’ll explain how they were achieved and why they matter.
Results Summary
For this round, we ran the 3D U-Net benchmark with simulated H100 GPUs.
Note: Previous submissions and alternative benchmark configurations can be found in ML-Perf for Storage Benchmark Results technical brief.
3D U-Net emulates a medical image segmentation workload. It’s the most bandwidth-intensive of the MLPerf Storage benchmarks, highlighting parallel I/O throughput as well as memory and CPU efficiency. Three configurations were tested, with one, three, and five Tier 0 nodes respectively. The table and graph below summarize the results.
|
Tier 0 Node Quantity
|
H100 GPUs Supported
|
Total Throughput
|
Mean GPU Utilization
|
Coefficient of Variation
|
|
1
|
28
|
85.6 GB/s
|
94.7%
|
0.14%
|
|
3
|
84
|
253.1 GB/s
|
95.0%
|
0.13%
|
|
5
|
140
|
420.8 GB/s
|
96.4%
|
0.08%
|
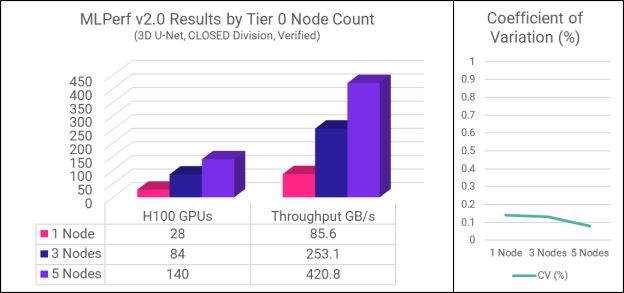
Notice that both the number of GPUs supported and throughput scale linearly as the number of Tier 0 nodes increases. This demonstrates the full capabilities of the best case where the primary dataset can reside 100% on the host. As the scale of the cluster grows, peak performance will be dependent on the configuration of the system and the percentage of locally-resident data, but aggregate performance will continue to scale. This is an area for further exploration by our performance test team.
Mean GPU utilization indicates the percentage of time the GPUs are being kept busy vs. waiting. To ‘pass’ the MLPerf Storage benchmark, all GPUs must be kept at 90% or higher utilization. Higher is better, since the goal is to minimize GPU idle time.
Coefficient of variation (CV) is a measure of the difference in the results between multiple runs of the same test. The MLPerf Storage benchmark requires that each test be run multiple times, and that the results fall within a small range. This ensures that results are truly reproducible. The very low CV shown by the Hammerspace results indicates that system performance was very stable and predictable.
Competitive Comparison – Simplicity and Efficiency Are Key
To ensure meaningful and fair comparisons, the following discussion includes only vendors who performed the 3D U-Net H100 test using on premises shared file configurations. This graph shows the best result submitted by each vendor in terms of the number of GPUs supported:
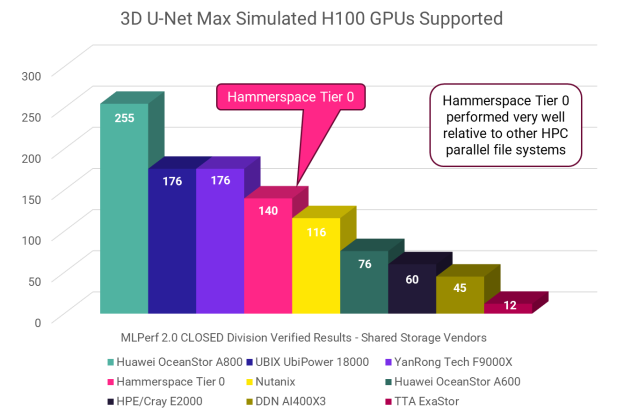
As you can see, Hammerspace Tier 0 delivered an excellent result, besting most of the household names on this test. But there is another way to look at this data that’s incredibly revealing and relevant – through the lens of efficiency.
Datacenters everywhere are short on power, cooling, and often rack space. AI, with its power-hungry GPU servers, has magnified the problem. Every Watt dedicated to storage infrastructure is one that’s not available for GPUs. In short, efficiency matters.
Actual power dissipation information is not available for the MLPerf Storage submissions, but we can use rack U as a proxy, assuming the more rack U a solution requires, the more power it will use.
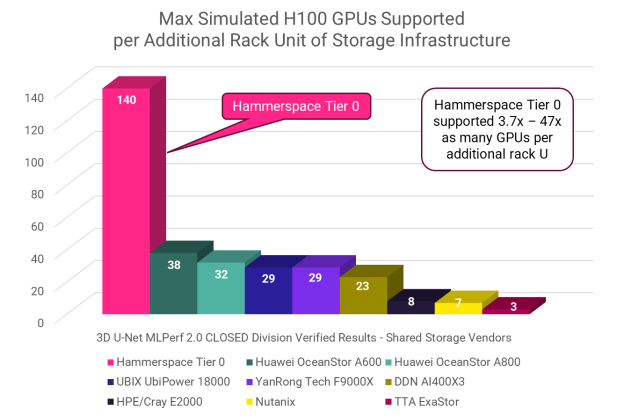
When you look at the number of GPUs supported per additional rack U of storage infrastructure, Hammerspace Tier 0 stands head and shoulders above the rest, with a result 3.7x that of the next most efficient system.
In a real-world situation, GPU servers (represented here by benchmark clients) run AI workloads. “Additional rack U of storage infrastructure” refers to the additional space taken by the storage solution, over and above the compute servers/benchmark clients.
Because Tier 0 aggregates local NVMe storage across the GPU servers in a cluster, the only additional hardware needed for our benchmark run was a single 1U metadata server, known in Hammerspace as an Anvil. In production installations it’s typical to run two Anvils for high availability, but even then Hammerspace would be 85% more efficient than the next best entry.
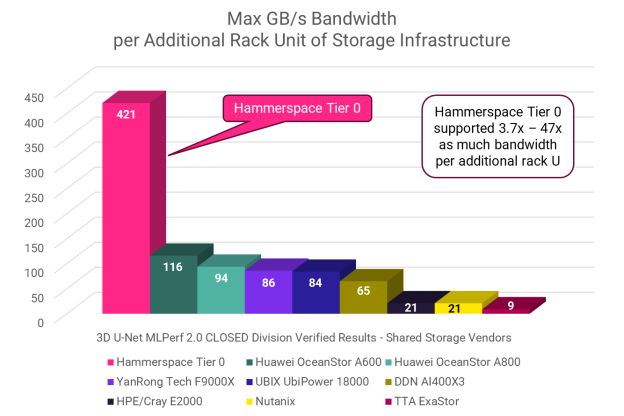
Looking at max GB/s bandwidth reveals a similar story: Hammerspace Tier 0 is 3.7x as efficient as the next nearest entry.
Benchmark Configuration
Here’s a diagram of the test configuration:
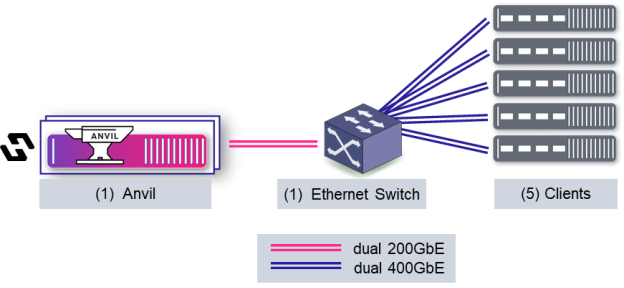
Clients run the benchmark code. With Tier 0, they also house the NVMe drives – 10 ScaleFlux CSD5000 drives per client, in this case. The Anvil is responsible for metadata operations and cluster coordination tasks – no data flows through it. Clients mount the shared file system via parallel NFS (pNFS) v4.2, accessing the storage directly after receiving a layout from the Anvil.
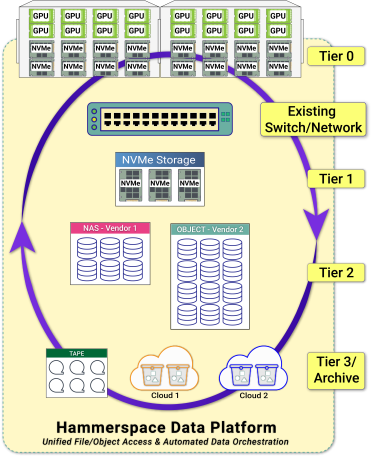
The benchmark configuration is a bit artificial in its limited scope. Typically, Tier 0 is just one of many tiers of shared, persistent storage in a more comprehensive Hammerspace infrastructure that may include network-attached Tier 1 NVMe, object storage, and more across multiple sites and clouds.
Why Tier 0 Matters for Enterprise AI
As enterprises contemplate AI initiatives, initial costs loom large. Computing and storage resources must be acquired and large amounts of data from across the organization must be identified, cleaned, and organized. Anything that can make it simpler to get started is valuable. That’s why with MLPerf v2.0 Hammerspace focused on our Tier 0 implementation.
Hammerspace Tier 0 activates the NVMe storage already present across a cluster of GPU servers, bringing it into a shared, global namespace. Data placement and protection are automated using Hammerspace’s extensive data orchestration capabilities. Tier 0 even works in the cloud when it makes more sense to rent vs. buy.
For the critical initial phases of data wrangling, Hammerspace’s assimilation capability eliminates the need to copy huge amounts of data into a net new repository before refining it. Assimilation brings existing NAS volumes into Hammerspace by scanning their metadata. The data itself stays in place. Once the relevant data is identified and prepared, it can be dynamically orchestrated onto high-performance storage like Tier 0 for processing, with results ultimately archived to a lower-cost tier.
Benefits of Tier 0 for Enterprise AI
The benefits of Hammerspace Tier 0 for Enterprise AI include:
Simplicity:
- Get started with the storage and network infrastructure that’s already in place
- No agent software to install
- No special networking, just Ethernet
Performance:
- Tier 0 storage is up to 10x faster than networked storage
- Tier 0 increases performance both on premises and in the cloud
- Increased GPU utilization, faster checkpoints, reduced inferencing times
Efficiency:
- Less external shared storage needed
- Less power, rack space, and networking vs. external shared storage
- Faster time to value – activate Tier 0 in hours, not days or weeks
Conclusion
Hammerspace is proud of our involvement in MLCommons and the MLPerf Storage benchmark program, and we’re proud of our results. But we’re not standing still. We’ve already made additional improvements that deliver even better results – but that’s a topic for a future blog.



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter


