






Managing Archive Avalanche
By analyst Fred Moore, president, Horison
This is a Press Release edited by StorageNewsletter.com on October 5, 2018 at 2:17 pm This article was written this year by Fred Moore, president, Horison, Inc.
This article was written this year by Fred Moore, president, Horison, Inc.
Abstract
Relentless digital data growth is inevitable as data has become critical to all aspects of human life over the course of the past 30 years.
Newly created worldwide digital data is expected to grow at 30% or more annually through 2025 mandating the emergence of an ever smarter and more secure long-term storage infrastructure. Data retention requirements vary widely, but archival data is rapidly piling up. Digital archiving is now a required discipline to comply with government regulations for storing financial, customer, legal and patient information. As businesses, governments, societies, and individuals worldwide increase their dependence on data, archiving and data preservation become highly critical.
Most data typically reach archival status in 90 days or less, and archival data is accumulating at over 50% compounded annually. Many data types are being stored indefinitely anticipating that eventually its potential value might be unlocked.
Industry surveys indicate nearly 60% of businesses plan to retain data in some digital format 50 years or more and a growing amount of data, much for historical preservation, will never be modified or deleted. For most organizations, facing terabytes, petabytes and even EBs of archive data for the first time can force the redesign of their entire storage strategy and infrastructure. Archiving is now a required storage discipline and is quickly becoming a critical ‘Best Practice’. It’s time to develop your game plan.
What is Archival Data?
Simply stated: archival data is data that is infrequently used and seldom if ever changes – but potentially has significant value and needs to be securely stored and accessible indefinitely. Data archiving is the set of processes and management of archival data over time to ensure its long-term preservation, accessibility and security. A key benefit of data archiving is that it reduces the cost of primary storage and also reduces the volume of data that must be backed up. Removing infrequently accessed data from the backup data set improves backup and restore performance and frees up a lot of storage capacity. Do it!
Key point: Archives are no longer a repository for low-value data. Effectively managing the fast- growing digital archive is attainable and now requires a multi-faceted strategy.
Did You Know – Backup and Archive Are Very Different Processes?
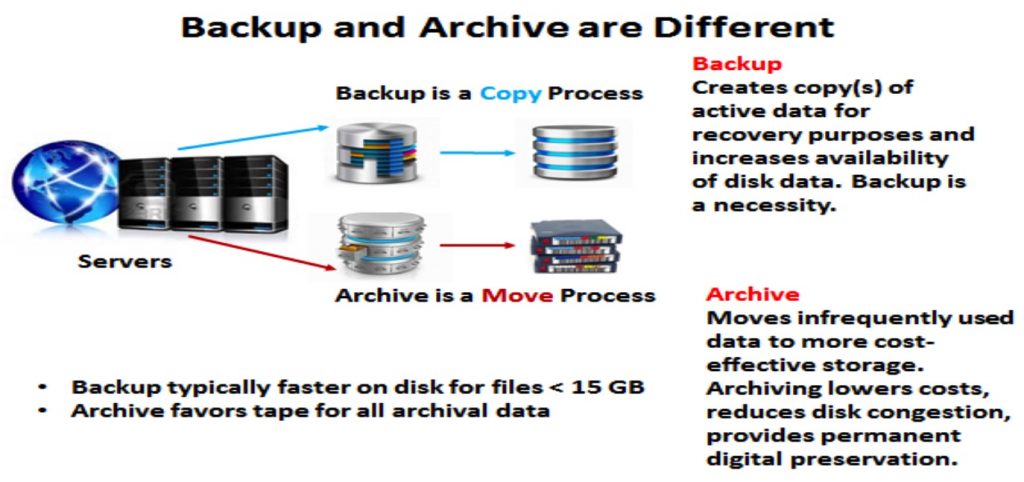
Many people continue to confuse the backup and archive processes – some even think it’s the same thing. Backup is the process of making copies of data which may be used to restore the original copy if the original copy is damaged, corrupted, or after a data loss event.
Archiving is the process of moving data that is no longer actively used, but is required to be retained, to a new location for long-term storage. Some archives treat archive data as read-only to protect it from modification, while other data archiving products treat data as read and write capable. Data archiving is most suitable for data that must be retained for historical, future data mining and regulatory requirements.
Archiving Reduces Pressure on the Backup Window
Studies indicate that as much as 85% of an organization’s data is historically valuable, rarely accessed and cannot be deleted and as much as 60% of that data typically resides on disk drives. There’s no point in repeatedly backing up unchanged data – especially if it’s seldom accessed – as this lengthens the backup cycle. Archiving can remove much of the low activity and unchanged data from the backup set to speed up the backup process and free up storage capacity in the process.
Though disk backup processes using compression or deduplication can help, the growing length of backup windows remains a major data center issue and is under constant pressure as data growth rates exceed 30% annually and many data centers now operate in 7x24x365 mode.
Key points: Backup and archive are not the same. Backup occurs on your time – recovery occurs on company time. Archiving moves the original data to more cost-effective location for long-term storage.
How Much Data is Archival?
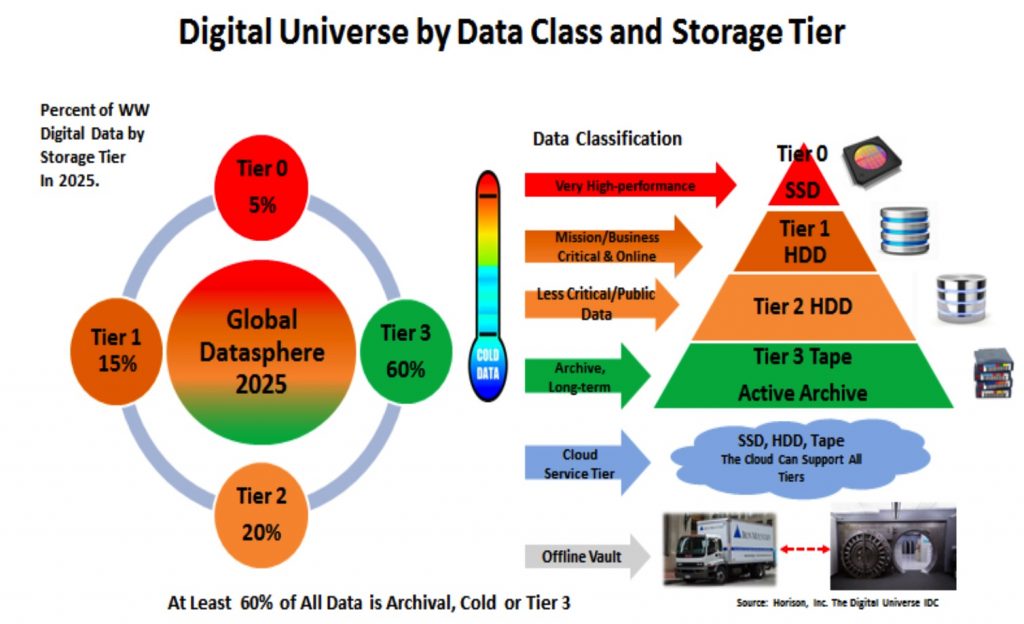
IDC’s most recent digital universe report projects by 2025 the Global Datasphere will total as much as 163ZB though most of this data will be transient (short-lived) and not result in any net storage requirements. By 2025, using standard industry-wide data classification averages, it is anticipated that most all digital data should optimally be stored on tier 0 SSD (5%), tier 1 and tier 2 HDDs (35%) and tier 3 tape or an active archive (60%). Note: tier 3 is referred to as the tape tier or archive tier.
Basic Steps for Building a Long-term, Secure
and Scalable Archive Strategy
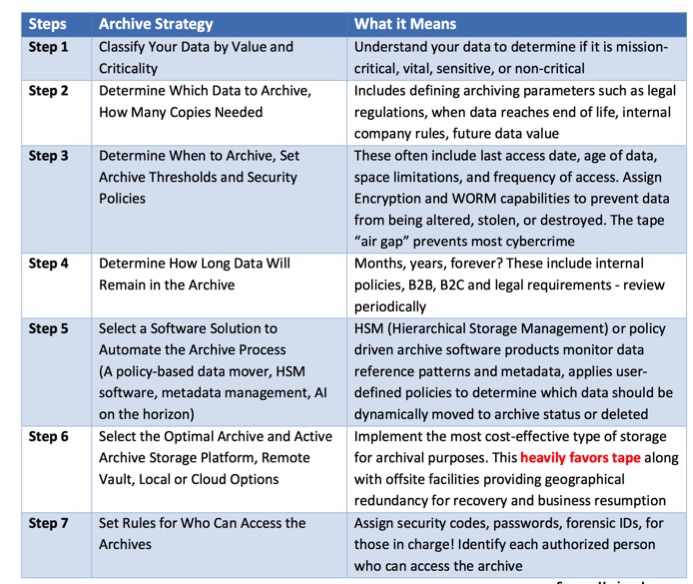
Are you prepared to manage the avalanche of archival and permanent data that lies ahead? Data archiving is a relatively simple process to understand, and can be successfully implemented given the more effective, advanced hardware and software that is available today. New solutions are steadily appearing and will include AI. AI will go mainstream in the enterprise, transforming business with intuitive, out-of-the-box AI experiences and provide a huge assist to the entire data management discipline in the not-too-distant future.
The basic steps listed below provide realistic guidelines to build a sustainable archive capability. You may choose to add additional steps to the process based on specific business needs. Most plans make provisions for more than one copy of archived data. Of course, if you don’t want to deal with the growing amount of archival data, a cloud provider can be a viable option. Remember to keep it simple.
As many businesses are painfully discovering, coping with rapid accumulation of archival data cannot be cost effectively achieved with a strategy of continually adding capacity with more costly disk drives. From a capital expense perspective, the cost of acquiring disk drives and keeping them functional can easily spiral out of control. From an operational expense perspective, the deployment of additional disk arrays increases spending (TCO) on administration, data management, floor space and energy compared to more efficient tape solutions as the data repository increases in size. Unlike disk, tape scales capacity by adding more media, not more drives, making tape a more cost-effective and scalable archival solution.
Key point: Data archiving is a comparatively simple process to understand but can become a challenge to implement without a plan. It’s time to get started before the pandemonium arrives.
Data Classification by Value and Criticality
All data is not created equal and classifying data value is a key process for effective data management and to protect data throughout its lifetime. Though you may define as many levels as you want, four de- facto standard levels of classifying data are commonly used: mission-critical data, vital data, sensitive data and non-critical data. Data classification also aligns data with the optimal storage tiers and services based on the changing value of data over time. Defining policies to map application requirements to storage tiers has been labor intensive but will greatly benefit from AI (Artificial Intelligence) in the near future. De-facto standard data classification guidelines are in the chart below.

Determine When Data Should Be Archived
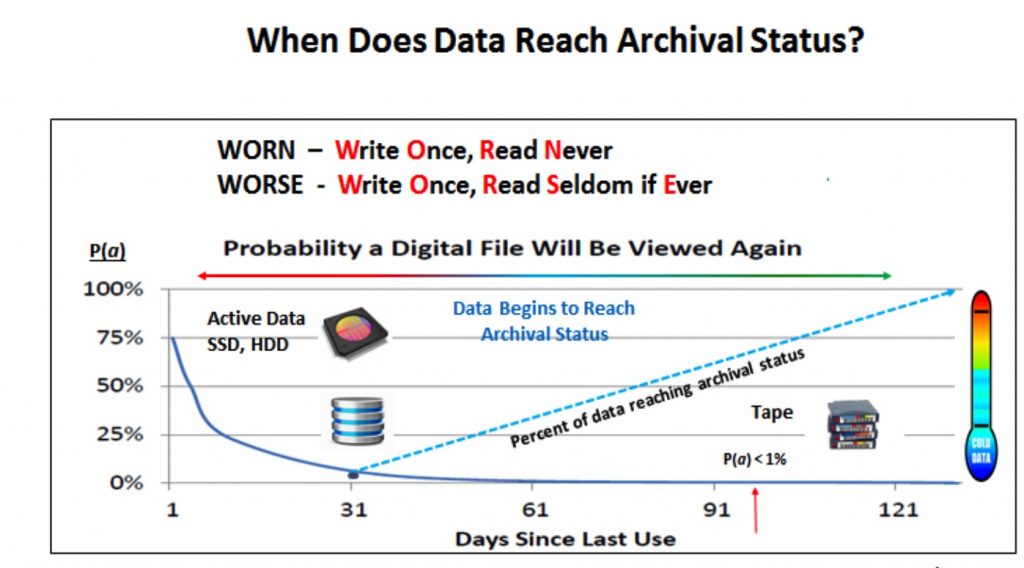
Establish the criteria for what types of data and when to archive based on internal policies, customer and business partner requirements, and compliance data. As most data ages since its creation, the probability of reuse declines. Many files begin to reach archival status after the file has aged for a month or more, and whenever the PA (probability of access) falls below 1%, often after three months. See chart below.
Software Solutions to Activate the Archive Process
Archives are best managed by HSM data-mover or similar type software. The HSM management system monitors access and usage patterns and makes user-defined, policy or metadata-based decisions as to which data should be moved to archival status and which data should stay on primary storage. HSM can help to identify candidate data for inclusion in a deep or active archive and can identify temporary data that can be deleted once its useful life has expired. Several HSM software products also provide backup and recovery functions. AI will likely be added to these solutions to make even better and less labor-intensive decisions in the future.
Examples of HSM and Archive Software Vendor
- DFHSM, Tivoli Storage Mgr. (IBM Spectrum Protect), HPSS – IBM
- StorNext – Quantum
- SAM-QFS – Oracle
- DMF – SGI
- DiskXtender End of Life, Replaced by Seven10 Storfirst – EMC/Dell
NetBackup Storage Migrator – Veritas (Symantec) - HPE Storage Software – HPE
- CA-Disk – CA
- Simpana – CommVault
- Dternity – Fujifilm
- Versity Storage Manager – Versity
Key point: Several effective archival software solutions are available to determine when data reaches archival status, where it should be stored, and how long it should be kept.
Online, Offline and Cloud Storage
Data archives can take a number of different forms. Some systems may intentionally use online storage, which places archive data onto disk systems where it is readily accessible. Other archival systems use offline storage (no electrical connection) in which archive data is normally stored on tape rather than being kept online. Storing archival data on tape in the cloud represents a significant growth opportunity for tape providers and a much lower cost, more secure archive alternative than disk for cloud providers; a win-win. Because tape media can be removed and stored offline, tape-based archives consume far less power than disk systems and offer the added benefit of cybercrime protection with its ‘air gap’. Amazon Glacier and Microsoft Azure are examples of large-scale cloud storage services designed for data archiving and backup that use tape.
Digital Archives Embrace Object Storage
Archiving was the initial enterprise use case for object storage providing scalable, long-term data preservation. Object storage is popular with cloud providers and enables IT managers to organize archival content with its associated metadata into containers to easily allow retention of massive amounts of unstructured data. In July, 2017 IBM Spectrum ArchiveEnterprise Edition V1.2.4 which uses LTFS, announced a connection with OpenStack Swift to enable the movement of cold (archive) data from object storage to more economical tape and cloud storage for long-term retention. LTFS now provides a back-end connector for open source SwiftHLM (Swift High Latency Media), a high-latency storage back end that makes it easier to perform bulk operations using tape within a Swift data ring.
Comparing Disk or Tape for Archiving
Disk can be used for archival storage however it is an expensive option. A disk drive can consume from 7W to 21W of electrical power every second to keep them spinning and even more energy is needed to cool them. The TCO advantage for tape is expected to become even more compelling with future technology developments. Cloud storage uses disk and tape and is relatively inexpensive, but cloud data retrieval/transfer costs can soar as the amount of data transferred increases. The chart below compares key archival considerations for tape compared to disk to implement an optimized archive infrastructure.

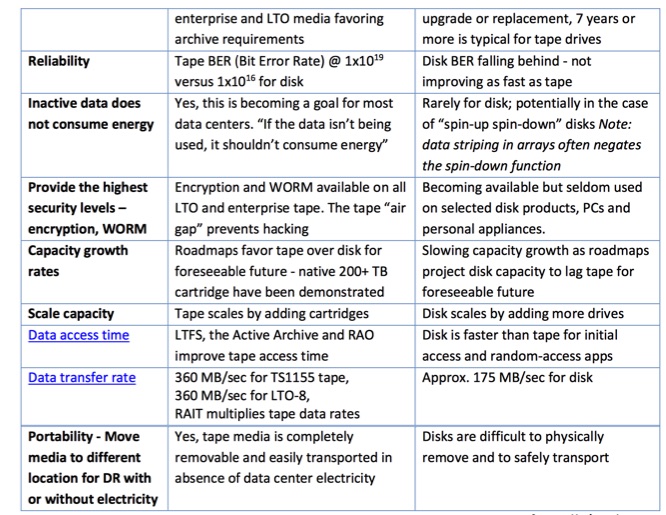
Key point: The tape industry continues to innovate and deliver compelling new features with lower economics and the highest reliability levels. This has established tape as the optimal tier 3 choice for archiving as well as playing a larger role for backup, business resumption and DR.
Storage Intensive Applications Reawakening the Archives
At the beginning of this century, large businesses generated roughly 90% of the world’s digital data. Today an estimated 75-80% of all digital data is generated by individuals – not by large businesses – however most of this data will eventually wind up back in a large data center, service provider or a cloud provider data center. Organizations are quickly learning the value of analyzing vast amounts of previously untapped archival data. For example, big data uses analytics and data mining for very large and complex data sets continually increasing the value of previously untouched archival data while adding pressure to improve the management and security capability of the archive. Various industry studies indicate less than 10% of all stored digital data has actually been analyzed (it may have an occasional reference) and that over 40% of all stored data hasn’t been accessed at all in the past 6-12 months.
Presenting an ever-moving challenge, the limits of archives are reaching the order of petabytes, exabytes and will approach zettabytes of data in the foreseeable future. The applications listed below all create significant volumes of data that become archival as it ages.
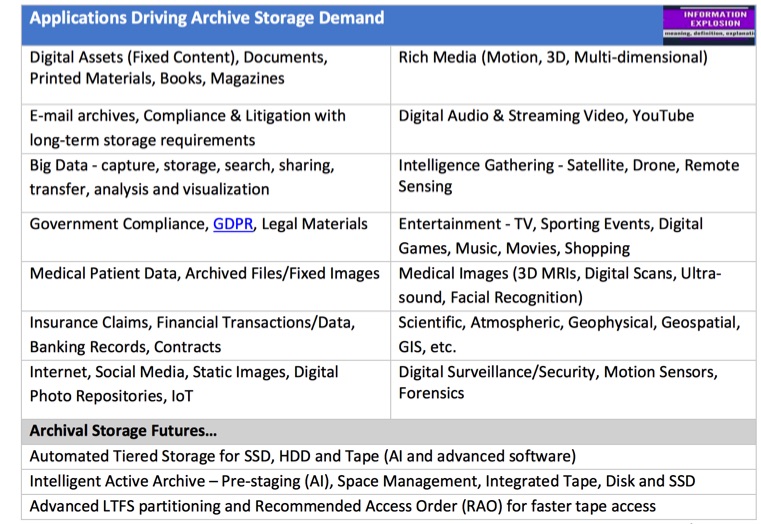
For many data types, the lifetime for data preservation has become ‘infinite’ and will constantly stress the limits of the archive infrastructure as much data will never be deleted. The size of preserving digital archives are now reaching the order of petascale, exascale) and will approach zettascale capacities in the foreseeable future requiring highly scalable storage systems.
Key point: With tape now having a TCO of 1/6th to 1/15th of disk for archival storage, and with reliability having surpassed disk drives, the pendulum has shifted to tape to address much of the tier 3 demand.
Active Archive Combines Disk and Tape for Even Better Performance
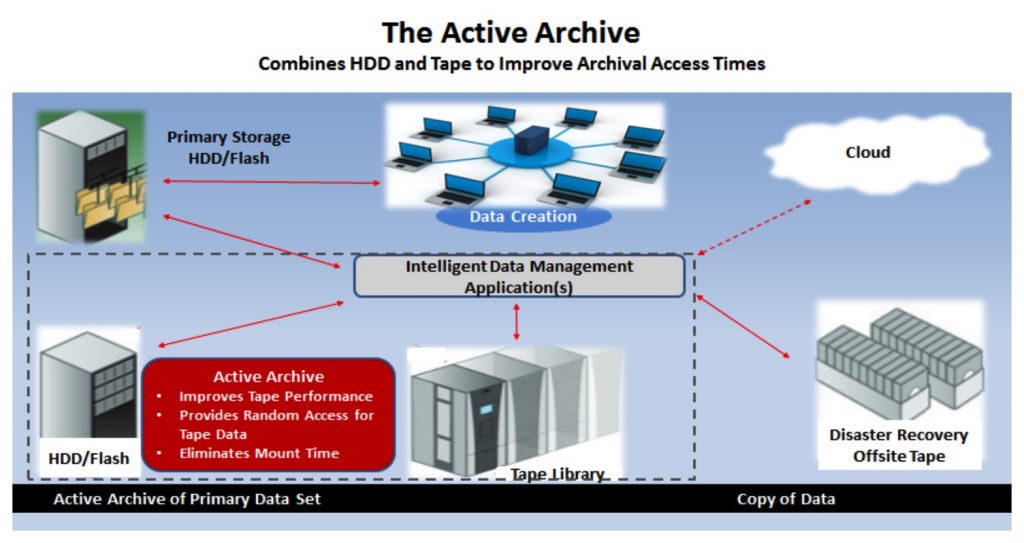
The Active Archive provides a persistent online view of archival data by integrating one or more storage technologies (SSD, disk, tape and cloud storage) behind a file system that gives users a seamless means to manage their archive data in a single virtualized storage pool. Disk serves as a cache buffer for the archival data on tape and provides higher IO/s and random access to more active data in the large tape archive. Using LTFS, a data mover software solution and a disk array or NAS in front of a tape library creates an Active Archive. The Active Archive with LTFS and tape partitioning have barely scratched the surface of their potential and has yet to introduce AI to its functionality. Expect an increasing number of ISVs (ISVs) to exploit LTFS in the future in conjunction with implementing Active Archive solutions. The Active Archive concept is supported by the Active Archive Alliance. See Active Archive conceptual view below.
Conclusion
A strategy to move low-activity, but potentially valuable data to the optimal storage tier for secure, long-term retention immediately yields significant cost savings with improved security. The bottom line is that your business-value for archiving will include cost containment (free up disk space), risk reduction to ensure regulatory compliance, improved productivity by getting inactive data out of the path of the backup window, more efficient searches and retrieval, and improved storage administrator efficiency.
Archive storage growth and requirements seem to have no limits while tape technology continues to make tremendous strides – what timing! The future role of tape in archival storage cannot be denied and the sizeable cost savings of using tape compared to disk for archival storage promises to become even more compelling in the future. Tape densities will continue to grow, and tape costs will steadily decline, while disk drive performance is expected to remain flat and capacity growth rates have slowed. It really shouldn’t matter which technology is the best for digital archiving, it just happens that the numerous improvements in tape have made it the clear cut optimal choice for data archiving for the foreseeable future. The time has come to address these enormous archive challenges that lie ahead.
Summary
Designing a cost-effective archive is attainable and the components are in place to do so – sooner or later the chances are high that you will be forced to implement a solid and sustainable archival plan. Now is the time to get started.



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

