





Recap of the 66th IT Press Tour in Silicon Valley, CA
With 8 organizations: Globus, Helikai, InfoScale, The Lustre Collective, Novodisq, Scale Computing, VergeIO and Zettalane Systems
By Philippe Nicolas | February 5, 2026 at 2:30 pmThe 66th edition of The IT Press Tour took place in Silicon Valley, California, last week. Recognized as a press event reference, it invites media to meet and engage in in-depth discussions with various enterprises and organizations on IT infrastructure, cloud computing, networking, cybersecurity, data management and storage, big data and analytics, and the broader integration of AI across these domains. Eight companies joined that edition, listed here in alphabetical order: Globus, Helikai, InfoScale, The Lustre Collective, Novodisq, Scale Computing, VergeIO and Zettalane Systems.![]()
Globus
Globus is a nonprofit research IT platform run by the University of Chicago, focused on improving the efficiency and impact of data-driven research through sustainable software. Over nearly 30 years, it has evolved from early distributed and grid computing projects into a mature software-as-a-service platform that supports research data management, computation, and collaboration at scale. Globus technologies have contributed to major scientific achievements and global research infrastructure, including large international collaborations and grid computing efforts linked to Nobel-recognized research.
The platform is designed specifically for the research community, which has needs that differ from those of traditional enterprise IT. Research workflows must balance strong security with open science, support collaboration across institutions and borders, and integrate diverse, domain-specific tools. Researchers typically work across heterogeneous environments that include on-premise compute and storage, high-performance research networks, and shared national or international computing resources. This creates demand for unified, secure, and reliable data and compute services that work seamlessly across systems.
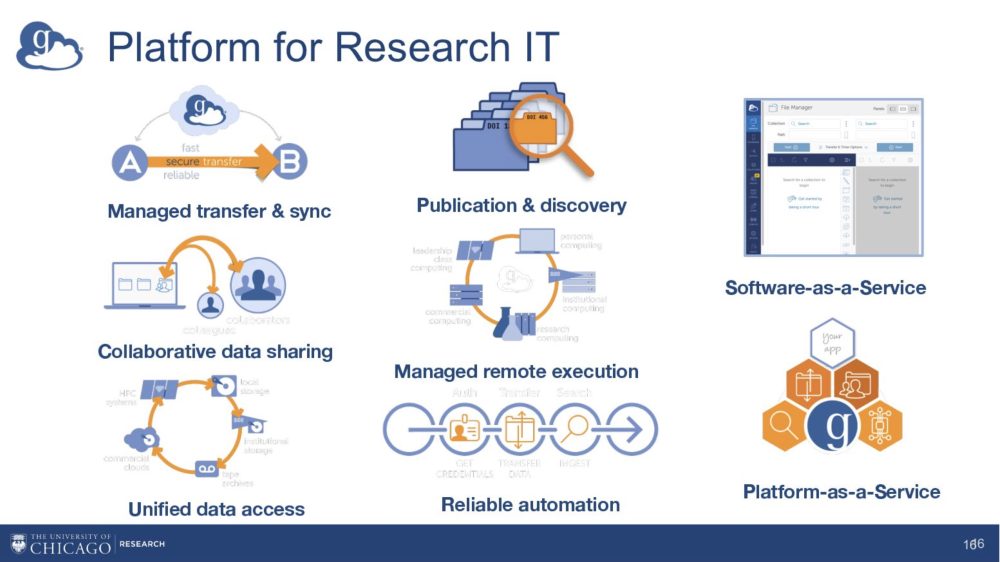
Globus addresses these challenges with a comprehensive research IT platform covering the full data and compute lifecycle. Core capabilities include managed data transfer and synchronization, secure data sharing, unified access to multiple storage systems, data publication and discovery services, remote compute execution, workflow automation, and metadata indexing for search and reuse. Its hybrid architecture combines cloud-hosted services with lightweight local agents, enabling federated access across laptops, laboratories, campus infrastructure, cloud storage, and high-performance computing facilities. Key features include reliable “fire-and-forget” transfers, secure tunneling across protected networks, fine-grained access controls, and federated authentication.
Globus also supports protected and regulated data, provides automation through tools such as Globus Flows, and enables scalable distributed computing via Globus Compute. Widely adopted worldwide, the platform serves thousands of institutions and users and transfers large volumes of data daily. It operates under a freemium model, offering free access for nonprofit research and paid tiers for advanced features, compliance needs, and commercial use.
Click to enlarge
Helikai
Helikai is a mission-driven AI company focused on accelerating enterprise transformation through specialized AI agents that automate clearly defined workflows and deliver measurable business value. Its “micro AI” philosophy emphasizes purpose-built agents designed for specific tasks, offering predictable cost, scope, and timelines with enterprise-grade accuracy. By avoiding broad, general-purpose AI models, Helikai aims to reduce hallucinations, improve reliability, and enable rapid, practical deployment in real-world business environments.
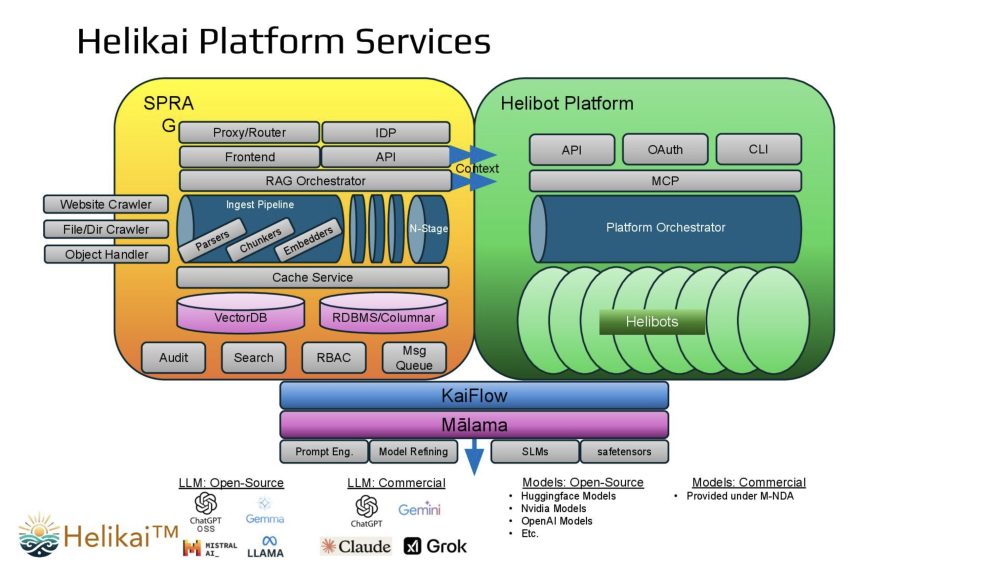
The Helikai platform is composed of several integrated components. Helibots are prebuilt AI agents tailored to specific workflows across enterprise IT, healthcare, media and entertainment, legal, and data infrastructure. SPRAG (Secure Private Retrieval Augmented Generation) connects large language models with private enterprise data in secure on-premises or isolated cloud environments, delivering grounded, traceable, and compliant outputs. KaiFlow provides a human-in-the-loop orchestration layer that embeds oversight, audit trails, and decision checkpoints into automated processes, while Mālama optimizes performance and resource efficiency to support scalable AI operations.
Customer engagement begins with AI workshops that assess organizational readiness using frameworks such as the MITRE AI Maturity Model. These sessions identify high-impact, low-risk automation opportunities and guide agent selection. Agents are trained on proprietary customer data, integrated with existing enterprise systems, validated against KPIs, and continuously refined as data and models evolve. Helikai supports flexible deployment models—including on-premises, private cloud, hybrid, and SaaS—while maintaining strict data isolation and security controls to address enterprise compliance and governance concerns.
Use cases span multiple industries. In enterprise IT and operations, agents automate document processing, ERP workflows, semantic search, onboarding, IT service desk functions, analytics, and revenue optimization. In healthcare and life sciences, they support data capture, literature analysis, clinical documentation, trial matching, and predictive population health insights. Media and entertainment applications include content creation, translation, dubbing, metadata tagging, colorization, and automated workflows. Overall, Helikai positions itself as an enterprise-grade agentic AI platform that integrates tightly with corporate systems, enabling organizations to build proprietary AI capabilities, automate complex processes, and achieve faster, more reliable outcomes with strong security, governance, and human oversight.
Click to enlarge
InfoScale
InfoScale is an enterprise software platform designed to deliver real-time operational resilience across applications, data, and infrastructure in hybrid, multi-cloud, and on-premises environments. Building on technology heritage from Veritas and its evolution through Symantec, Arctera, and now Cloud Software Group, InfoScale positions itself as a foundational resilience layer for mission-critical systems in industries such as finance, healthcare, telecom, energy, and insurance. The company reports broad enterprise adoption, significant reductions in downtime, and measurable operational efficiency gains.
InfoScale addresses the growing complexity and risk of modern IT operations, driven by hybrid architectures, rising cyber threats, AI-intensive workloads, and decreasing tolerance for service disruption. Enterprises manage thousands of interdependent applications and infrastructure components, where outages, ransomware, human error, maintenance events, or cloud failures can have serious financial and operational consequences. Traditional availability, backup, and recovery tools are often siloed and reactive, leading to fragmented resilience strategies and operational blind spots.
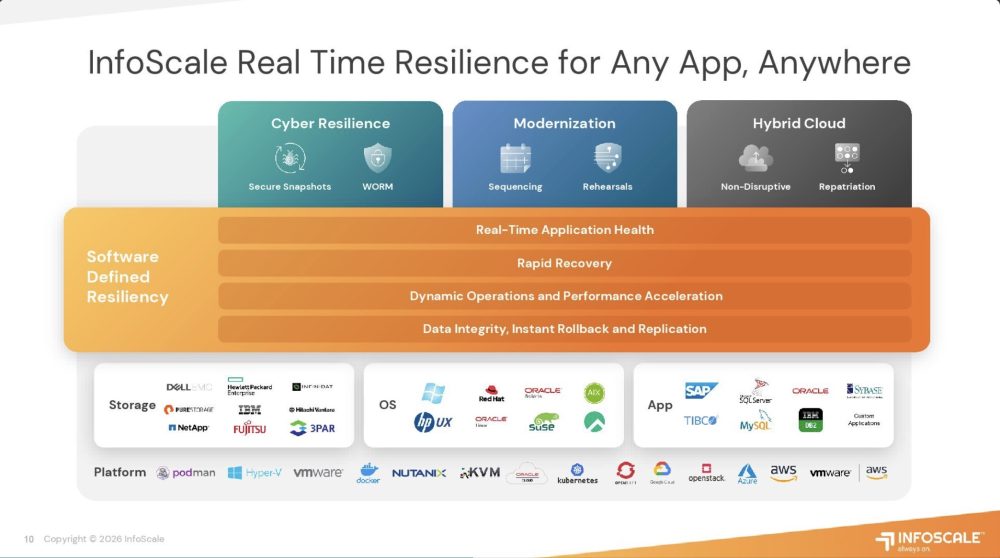
The platform’s core approach is “software-defined resiliency,” which unifies application-aware clustering, storage resiliency, orchestration, failover, replication, snapshots, and automation into a single full-stack solution. InfoScale delivers real-time application health monitoring, fast recovery, data integrity protection, secure snapshots, and workload mobility across clouds, supporting near-zero RPO and RTO across heterogeneous operating systems, storage platforms, and cloud environments. By understanding and orchestrating dependencies across applications, data, and infrastructure, the platform enables automated failover, disaster recovery, and cyber resilience at enterprise scale.
InfoScale also emphasizes operational intelligence, allowing organizations to simulate failures, test recovery plans, detect anomalies, and coordinate recovery workflows across complex environments. Its roadmap includes predictive failure analytics, intelligent workload optimization, automated recovery design, fault simulation, AI-driven contextual alerting, and proactive ransomware detection, aiming to shift resilience from reactive response to predictive and autonomous operations.
Overall, InfoScale positions itself as a comprehensive enterprise resilience engine that unifies application, data, and infrastructure management to reduce downtime, mitigate cyber risk, modernize IT operations, and ensure continuous business operations in increasingly complex digital environments.
Click to enlarge
The Lustre Collective
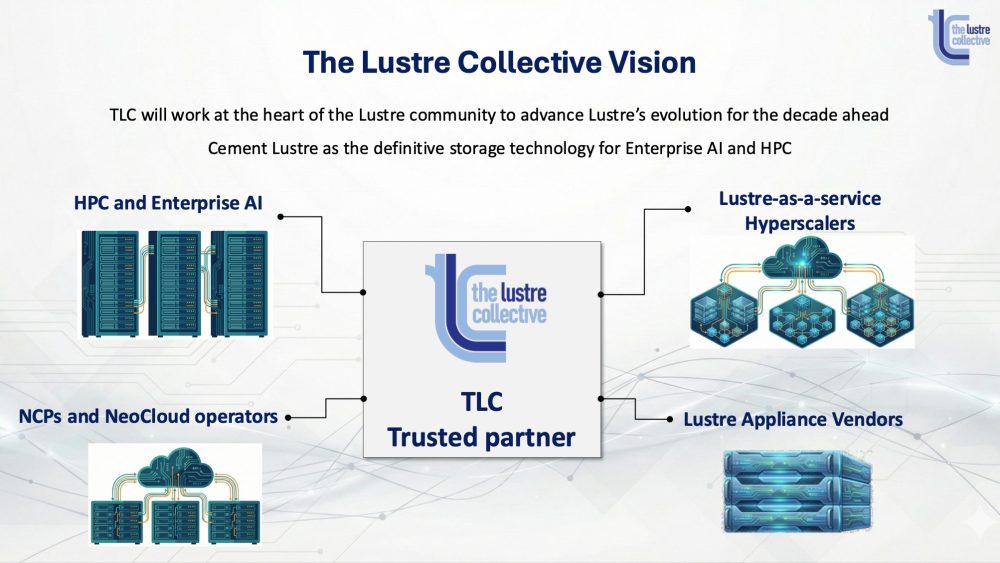
The Lustre Collective (TLC) is an independent organization formed to ensure the long-term innovation, stability, and relevance of the Lustre parallel file system, a foundational storage technology for high-performance computing (HPC), enterprise AI, and large-scale data infrastructure. Launched publicly at Supercomputing 2025, TLC was founded by principal Lustre community leaders and original developers who have driven Lustre’s architecture and releases for more than 25 years. Its mission is to provide neutral, expert stewardship focused exclusively on Lustre’s future evolution.
Lustre is a proven, open-source, vendor-neutral filesystem that powers a majority of the world’s most demanding systems. It is used by over 60% of the Top 100 HPC systems and supports leading exascale supercomputers and large commercial AI platforms operated by national laboratories, hyperscalers, and GPU-centric AI providers. Lustre’s durability stems from its symmetric bandwidth, linear scalability, POSIX compliance, and ability to operate reliably at extreme scale for both HPC simulation and AI/ML workloads.
TLC was created to address structural challenges in the Lustre ecosystem. While many vendors actively contribute to Lustre, development priorities are often fragmented or commercially driven. TLC positions itself as an independent, cross-community partner that coordinates long-term architectural direction, accelerates critical roadmap items, and contributes improvements openly. Unlike traditional startups, TLC is not focused on product licensing or exit strategies; instead, it reinvests revenue into engineering expertise, community collaboration, and sustained innovation.
From a technical perspective, modern Lustre delivers industry-leading performance and flexibility. It supports tens of terabytes per second of throughput, hundreds of millions of IOPS, tens of thousands of clients, and massive GPU clusters. The architecture enables fully parallel data and metadata paths, flexible use of HDD and NVMe storage, client-side NVMe caching, multi-rail RDMA networking, and protocol re-export through NFS, SMB, and S3 gateways. Security features include strong authentication, encryption, and fine-grained multi-tenant isolation.
TLC’s roadmap priorities include improving resilience, usability, and cloud readiness. Near-term efforts focus on erasure-coded files, undelete functionality, fault-tolerant management services, client-side compression, GPU peer-to-peer RDMA, and faster recovery. Longer-term goals include enhanced metadata redundancy, better quality-of-service controls, expanded multi-tenancy, and modernized monitoring and management tools. TLC monetizes through consulting, production support, feature development, training, and deployment services, positioning itself as a trusted partner to ensure Lustre remains the definitive data foundation for exascale HPC and enterprise AI in the decades ahead.
Click to enlarge
Novodisq
Novodisq is a New Zealand–based hardware and systems company focused on re-engineering data infrastructure to address growing constraints around power, space, and data sovereignty. Founded in 2018, the company aims to become a backbone for sovereign, AI-ready data lakes by delivering ultra-dense, ultra-efficient storage and compute platforms optimized for long-lived, data-heavy workloads. Novodisq positions its technology as a response to rapid global data growth – estimated at 20–30% annually – at a time when data-center power availability, cooling capacity, and physical space are increasingly limited.
The company targets the “warm data” layer, which represents the majority of enterprise and AI data that must remain online and accessible but does not require high-performance flash storage. Traditional approaches to this tier rely on power-hungry spinning disks or expensive hyperscaler services that scale poorly under power and sovereignty constraints. As AI workloads expand, data ingestion bottlenecks and inefficient storage economics increasingly leave GPU clusters underutilized. At the same time, governments and enterprises are demanding greater control over where data is stored and processed, driving interest in sovereign, on-premises infrastructure.
Novodisq’s solution is a vertically integrated, hardware-first architecture optimized for density, efficiency, and control. Its flagship product, Novoblade, is a 2U blade system that combines high-density storage and compute in a single chassis. Each blade delivers up to roughly 576 TB, and a fully populated 2U system scales to about 11.5 PB while consuming up to 90–95% less power than traditional HDD- or flash-based storage systems. The design prioritizes watts-per-petabyte efficiency, enabling deployments in power-constrained data centers, regional facilities, and edge environments.
A key differentiator is Novodisq’s decision to design its own SSDs, firmware, and system architecture rather than relying on off-the-shelf components. The platform uses low-power SoCs and FPGA-based acceleration to offload RAID, checksumming, encryption, and data processing from CPUs, improving efficiency and long-term reliability. Hardware is optimized for write-once, read-sometimes data with a targeted lifespan of up to ten years.
Alongside Novoblade, Novoforge provides a smaller development and pilot platform for testing workloads, validating software stacks, and experimenting with FPGA-accelerated processing. Use cases include genomics and medical imaging, backup and restore staging, CCTV and video systems, Kubernetes and microservices clusters, and private cloud deployments requiring strict data sovereignty. Overall, Novodisq positions itself as a power-efficient, high-density alternative to legacy storage vendors and hyperscalers, enabling sovereign, AI-ready data infrastructure in an increasingly constrained world.
Click to enlarge

Scale Computing
Scale Computing presents itself as a specialized edge computing and networking software company focused on simplifying IT operations, increasing resilience, and enabling the deployment of distributed applications across hybrid environments. Following its acquisition by Acumera, the combined organization aims to deliver an integrated edge platform that spans compute, networking, security, and orchestration, accelerating Scale Computing’s long-standing vision of resilient, easy-to-manage infrastructure at the edge.
The company defines the “edge” broadly as mission-critical workloads running outside centralized data centers or public clouds, including retail locations, factories, remote facilities, ships, and branch offices. Key drivers for edge adoption include cost control, latency-sensitive workloads such as AI inference, regulatory and data residency requirements, and the need for reliable operations in environments with limited or intermittent connectivity. Scale Computing emphasizes that the main challenge for enterprises is not deploying edge infrastructure itself, but operating it at scale—managing deployment, updates, monitoring, and recovery across hundreds or thousands of distributed sites.
Scale Computing’s platform is built around several core components. SC//HyperCore is a hyperconverged infrastructure stack that combines compute, storage, and virtualization with self-healing automation and built-in data protection. SC//Fleet Manager provides centralized, cloud-based orchestration for multi-site visibility, zero-touch provisioning, and application lifecycle management. The SC//Reliant Platform delivers edge computing as a service for large distributed enterprises, while SC//AcuVigil adds managed networking and security capabilities such as SD-WAN, firewalling, compliance monitoring, and endpoint observability. Together, these elements unify infrastructure, application deployment, and network management into a single edge-focused platform.
The Acumera acquisition strengthens Scale Computing’s networking and managed services portfolio, complementing its virtualization roots and enabling a full-stack edge solution. The company reports strong growth driven by demand for VMware alternatives following Broadcom’s acquisition and pricing changes. Key customers include channel partners, SMB and midmarket organizations, as well as large global enterprises and retailers. Use cases span retail, logistics, government, and industrial environments, including POS systems, video surveillance, IoT analytics, and AI-powered edge applications. Overall, Scale Computing positions itself as a purpose-built edge infrastructure platform that allows organizations to run critical workloads reliably, securely, and cost-effectively across distributed environments with minimal operational overhead.
Click to enlarge
VergeIO
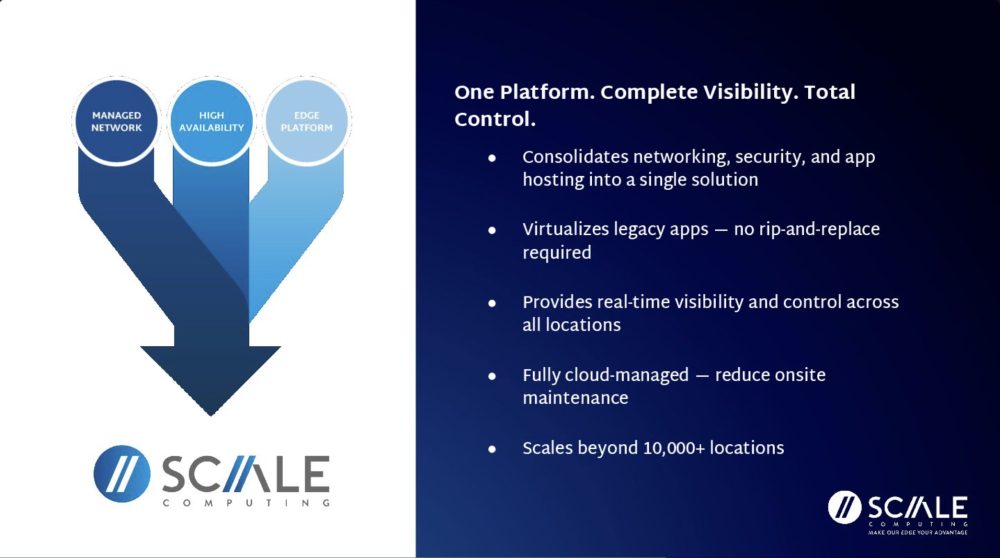
VergeIO is the developer of VergeOS, a private cloud operating system designed to replace traditional multi-layer virtualization stacks with a single, unified software platform. Founded in 2012, VergeIO positions VergeOS as a fundamentally different approach to private cloud infrastructure – collapsing compute, storage, networking, automation, resiliency, and management into one codebase rather than integrating multiple independent products. This architecture is intended to reduce complexity, improve performance, and significantly lower both capital and operational costs compared with legacy platforms such as VMware- or Nutanix-based stacks.
At the core of VergeOS is a single-kernel architecture built on KVM/QEMU with proprietary extensions. Instead of running separate hypervisor, storage, networking, and management layers, VergeOS integrates all services directly into the operating system, eliminating translation layers, duplicated metadata, and operational silos. VergeIO emphasizes that the entire VergeOS codebase is roughly 400,000 lines of code, compared with tens of millions in traditional stacks, enabling higher efficiency, simpler lifecycle management, and strong performance even on older hardware.
Key components include VergeFS, an integrated storage system with global inline deduplication across disk, memory, and data movement; VergeFabric, a built-in software-defined networking layer providing native Layer 2 and Layer 3 services, routing, micro-segmentation, and security without external controllers; and ioClone-based snapshots, which create full, independent, immutable copies with no performance penalty. VergeOS supports live VM migration across nodes and storage tiers, mixed hardware generations, and heterogeneous CPU environments within a single cluster.
For resiliency, VergeOS includes ioGuardian, a kernel-level local protection mechanism that maintains application availability during severe failures by dynamically retrieving only required data blocks from a protection node. Combined with ioReplicate, a WAN-optimized replication engine that transfers only unique deduplicated data, VergeOS enables near-zero RPO/RTO and rapid disaster recovery. Disaster recovery is further simplified through native Virtual Data Centers (VDCs), which capture complete environments—including VMs, networking, storage, and policies – in a single consistent snapshot.
VergeOS is licensed per physical server with all features included, regardless of cores, memory, or storage capacity. Combined with support for existing hardware such as VxRail, Nutanix, and commodity x86 servers, this model enables infrastructure modernization, VMware exit strategies, and reported cost reductions of 50–80%.
Click to enlarge
Zettalane Systems
Zettalane Systems is a cloud-native storage company focused on delivering high-performance file and block storage at significantly lower cost than traditional public cloud offerings. Founded by storage veteran Supramani “Sam” Sammandam, the company builds on deep experience in software-defined storage, ZFS, and NVMe to rethink how storage should be consumed in modern cloud environments. Zettalane’s goal is to provide simple, scalable, and developer-friendly storage while achieving up to 70% cost savings by leveraging object storage and ephemeral NVMe resources.
Zettalane targets the limitations of managed cloud storage services, which are often expensive, difficult to scale, and constrained by throughput caps. Its approach exploits the massive bandwidth and durability of cloud object storage while exposing familiar file and block interfaces such as NFS, SMB, iSCSI, and NVMe-oF. The platform is designed to run entirely within customer VPCs with no call-home requirement, addressing security and data sovereignty concerns.
The company offers two main products. MayaNAS is a high-throughput network file system for AI/ML, media, analytics, and backup workloads. It uses a hybrid ZFS architecture where metadata and small I/O reside on local NVMe using ZFS “special vdevs,” while large sequential data blocks are written directly to object storage. This eliminates data tiering and enables both high IOPS and extreme throughput in a single filesystem. A key innovation, objbacker.io, integrates object storage directly into ZFS without FUSE, enabling highly parallel I/O using cloud-native APIs. Benchmarks show multi-GB/s throughput in active-active HA configurations.
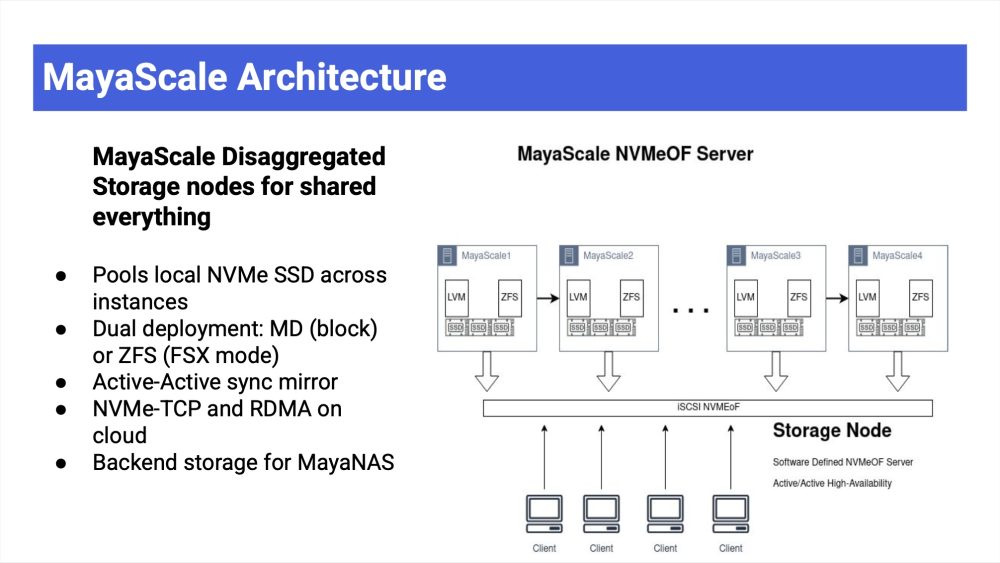
MayaScale targets low-latency workloads using local NVMe SSDs and NVMe-over-Fabrics. It supports both block and file modes for databases, analytics, Kubernetes, and FSx-like use cases. MayaScale uses server-side RAID-1 mirroring in active-active configurations, avoiding client-side replication overhead and delivering up to 2.3 million IOPS with sub-millisecond latency, with future RDMA support planned.
Zettalane emphasizes automation and ease of use through fully Terraform-based deployments, consistent multi-cloud behavior across AWS, Azure, and GCP, and rapid provisioning for ephemeral workloads. Its pricing model is consumption-based, charged per vCPU with no per-capacity or per-IOPS fees, and solutions are delivered through major cloud marketplaces. Overall, Zettalane positions itself as a modern storage platform that bridges low-cost object storage with high-performance NAS and block storage while minimizing operational complexity.
Click to enlarge
The 67th edition of The IT Press Tour will take place in Sofia, Bulgaria, March 31 and April 1st, 2026.



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

