






Overcoming the SSD Shortage with Vast
Leveraging the famous Solidigm white paper
By Philippe Nicolas | December 31, 2025 at 2:00 pmFrom gaming rigs to HPC centers, a global shortage of NAND flash capacity is impacting everyone who buys high-speed storage hardware. Pair this with additional supply chain issues around memory chips overall, and it looks like a pretty dire picture, indeed. AI giveth new capabilities, and AI taketh all available chip-manufacturing capacity.
If there’s a silver lining, however, it’s this: Shortages are a great forcing function to reconsider how we’ve been doing things and whether “just buy more” was ever really a viable strategy. In fact, when it comes to solid-state drives in the AI era, specifically, there’s a strong argument to be made that efficiency is always the best strategy.
And it’s a strategy that Vast Data is particularly suited to help you execute.
Back in September, in fact, one of our major hardware suppliers, Solidigm, published a whitepaper detailing (like, in great detail) the efficiencies of running Vast on Solidigm SSDs. They found that the combination can cut TCO for an exabyte of storage by nearly 60% compared with storing the same data on hard disks, and compressed the hardware footprint from 52 racks to 5 racks.
We supplemented the whitepaper with a blog post that addresses the findings at a higher level, some highlights from which are here:
- Solidigm’s 122-layer QLC NAND flash provides unprecedented storage density. This allows for a massive reduction in the physical footprint of storage systems
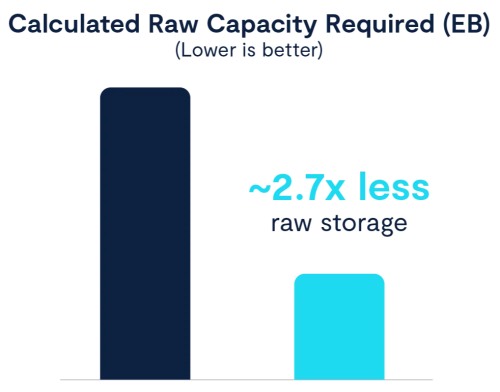
- Vast’s advanced Similarity data reduction technique goes far beyond standard compression to find and eliminate redundancy at a granular level, meaning you need nearly 3x less raw storage capacity compared to HDD solutions. This level of granular data reduction can only be practical on flash because spinning media depends on sequential data for speed. When duplicate data is removed, many sequential reads look like random IO, which flash drives excel at, but HDDs struggle with
- Locally decodable codes provide an extremely efficient and resilient form of data protection, further enhancing cost-effectiveness by reducing wasted overhead
 More broadly, though, the Vast DataStore is just built for efficiency. Global namespace? Check. Block, file, and object storage on a single platform? Check. Automatic and real-time deduplication, similarity reduction, and compression across all of it? Check.
More broadly, though, the Vast DataStore is just built for efficiency. Global namespace? Check. Block, file, and object storage on a single platform? Check. Automatic and real-time deduplication, similarity reduction, and compression across all of it? Check.
Our customers are happy to share their stories of revamping their storage architectures with Vast, and this quote from Lola VFX founder Edson Williams sums up a lot of what we hear “After we evaluated all our options, we chose Vast because of the scalability, the performance, and the value. We immediately started to see the impact of Vast. With their global namespace, we’ve been able to essentially make all our data accessible anywhere it is needed. And then the 2:1 reduction rate has allowed us to store more data than we had first thought. So, the return on investment was faster than we had even guessed. Initially, we were anticipating 24 to 36 months, and it’s going to be closer to 15 to 18 months before the Vast system pays for itself in increased productivity.”
If you’re running a data center, condensing your storage footprint delivers immediate results. Fewer racks means more room for GPUs. Fewer disks means more power for GPUs. Lower TCO means more budget for GPUs. This, combined with top-of-the-line performance, is a big reason why so many of today’s leading AI clouds utilize Vast – and why so many of their customers ask for Vast by name.
If you’re running AI workloads in the cloud, storing data on Vast means you can choose cloud providers based on who’s delivering the best compute platform for your needs at any given time. Or, in the worst case, who even has available compute capacity. As part of our recently announced partnership with Google Cloud, for example, we demonstrated a configuration linking two compute clusters – one TPU-based cluster in the United States and one GPU-based cluster in Japan – with a single Vast DataSpace instance. The result: seamless, near real-time access to the same data in both locations while running inference workloads.
Vast has also powered data access for some of the world’s largest AI training runs, and our own analysis showed that many could actually use far less storage bandwidth without risking checkpoint failure. That means even large AI labs could safely reinvest some training infrastructure from storage to GPUs, and achieve the same results.
The global economy brought the lemons. Vast has the juicer, the water, and the sugar ready to go.



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

