






HCI: Edge Deployments
Leaders HPE, Hitachi Vantara, VMware, Cisco, Dell, Nutanix, Microsoft and Scale Computing
This is a Press Release edited by StorageNewsletter.com on February 6, 2023 at 2:02 pm![]() This report was published on December 21, 2022 by GigaOm and written Alastair Cooke, an independent industry analyst who has been writing about the challenges and changes in the IT industry for over 10 years.
This report was published on December 21, 2022 by GigaOm and written Alastair Cooke, an independent industry analyst who has been writing about the challenges and changes in the IT industry for over 10 years.
GigaOm Radar for Hyperconverged Infrastructure: Edge Deploymentsv3.0
1. Summary
Edge deployments are among the most dispersed HCI environments, with small clusters at many locations and usually without technical staff readily available. One area of differentiation is between near edge and far edge. The near edge is a data center that’s not on-premises, while far-edge locations typically depend on the function. Near-edge deployments could be in co-location or telco data centers spread around the country or around the world. Far-edge environments might be in trucks, retail stores, or oil exploration platforms. The available facilities vary greatly among these locations, and so there is variation as well among solutions.
The usual data center HCI vendors are well represented for near-edge environments, which require rack-mount servers and extensive resources. Just like inan on-premises data center, HCI at the near edge is a general-purpose platform that accommodates multiple applications. The difference is that there tend to be far more edge locations than on-premises data centers and visiting these locations for maintenance is usually impractical, so hands-off management of large numbers of HCI clusters is essential.
The far edge requires hardware that does not rely on the niceties of a data center; power, cooling, and space may all be limited. Far-edge clusters are also more likely to run exclusively custom applications. Often, applications are deployed in containers, with or without Kubernetes, alongside VMs or possibly without any VM-based applications. At the far edge, hands-off management may not be enough; these locations may require hands-off deployment for clusters never visited by IT staff. Finally, far-edge locations may have only intermittent connectivity and must be able to operate for extended periods in disconnected mode. For example, a fishing boat on a two-week expedition might have Internet connectivity only when in port.
The more established server vendors may have some products not included in this report that target the far edge, not relying on their data center-focused HCI to scale down to far-edge requirements. The data center HCI products still operate at the near edge where rack-mount servers are viable and consistency with data center HCI platforms is beneficial. Whether your environment consists of 500 clusters in 500 telco points of presence (PoPs), or 10,000 delivery trucks, edge deployments scale out. Policy-based management of large numbers of clusters is vital. Automation of every aspect of operations and application updates is essential.
This GigaOm Radar report highlights key edge HCI vendors and equips IT decision-makers with the information needed to select the best fit for their business and use case requirements.
2. Market Categories and Deployment Types
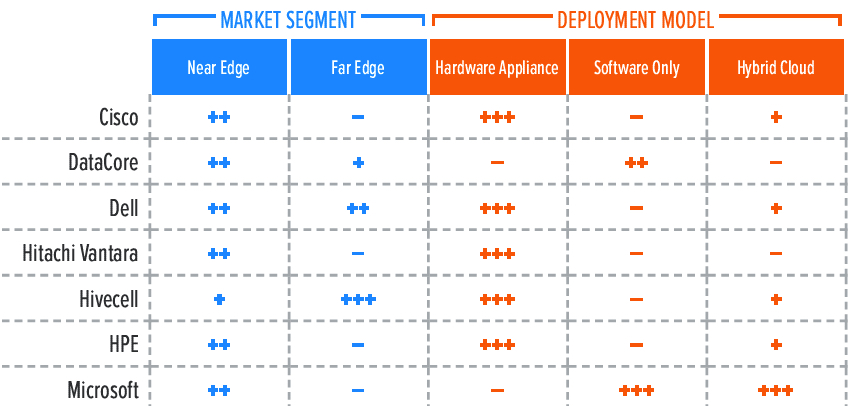
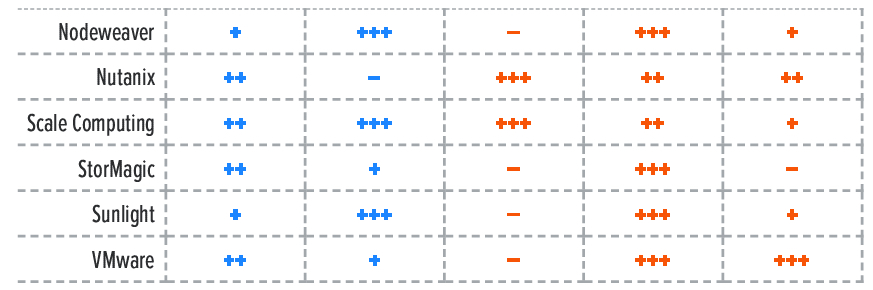
For a better understanding of the market and vendor positioning (Table 1), we assess how well HCI edge solutions are positioned to serve specific market segments and deployment models.
We recognize 2 market segments for solutions in this report:
Near edge: In this category, we assess solutions on their ability to meet the needs of organizations deploying to large numbers of data center locations, such as telco locations, cellular network sites, or large retail branches.
Far edge: Here, offerings are assessed on their ability to be deployed in non-traditional locations for servers. These solutions will support small form factor (SFF) machines and will not require data center services such as server racks, air conditioning, and protected power.
In addition, we recognize 3 deployment models for solutions in this report:
Hardware appliance: These products have HCI software pre-installed on physical servers, with a validated collection of firmware and drivers. The limited hardware choice, compared to software-only HCI, provides a smaller set of components for the vendor to validate for updates. Both hardware and software support are provided by a single vendor.
- Software only: This approach allows customers to assemble their hardware configuration from a compatibility list and install the HCI software. The customer takes more responsibility for the compatibility of firmware and drivers with updates and receives hardware and software support from different vendors. Software-only HCI deployments may reuse existing servers or include servers from different vendors in the deployment.
- Hybrid cloud: These products offer the same HCI platform or management tools as a cloud service with integration to on-premises deployment. Workload portability from on-premises to the cloud service will score higher than cloud-based management.
Table 1. Vendor Positioning
 +++ Exceptional: Outstanding focus and execution
+++ Exceptional: Outstanding focus and execution
++ Capable: Good but with room for improvement
+ Limited: Lacking in execution and use cases
– Not applicable or absent
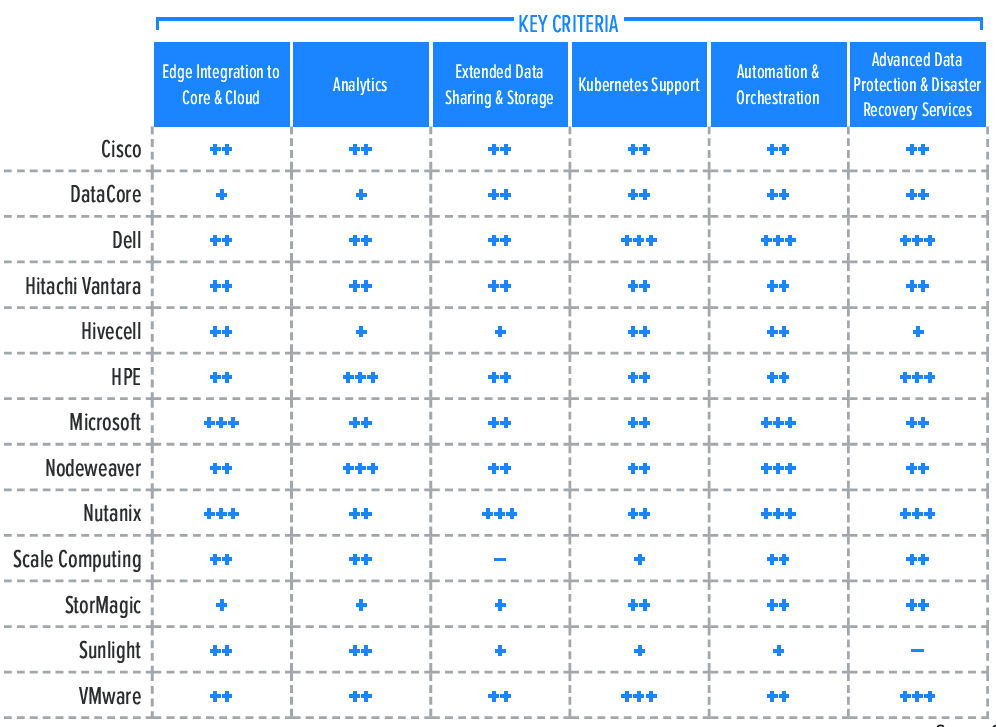
3. Key Criteria Comparison
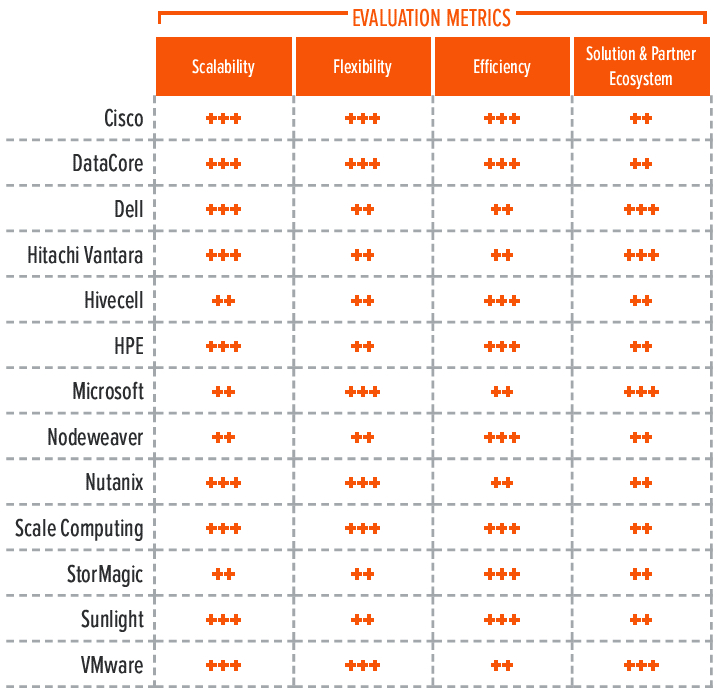
Building on the findings from the GigaOm report Key Criteria for Evaluating Hyperconverged Infrastructure Solutions, Tables 2, 3, and 4 summarize how well each vendor included in this research performs in the areas we consider differentiating and critical for the sector: key criteria, evaluation metrics, and emerging technologies.
Key criteria differentiate solutions based on features and capabilities, outlining the primary criteria to be considered when evaluating edge HCI solutions.
Evaluation metrics provide insight into the impact of each product’s features and capabilities on the organization.
Emerging technologies and trends indicate how well the product or vendor is positioned with regard to technologies and trends likely to become significant within the next 12 to 18 months.
The objective is to give the reader a snapshot of the technical capabilities of available solutions, define the perimeter of the market landscape, and gauge the potential impact on the business.
Table 2. Key Criteria Comparison
 +++ Exceptional: Outstanding focus and execution
+++ Exceptional: Outstanding focus and execution
++ Capable: Good but with room for improvement
+ Limited: Lacking in execution and use cases
– Not applicable or absent
Table 3. Evaluation Metrics Comparison
 +++ Exceptional: Outstanding focus and execution
+++ Exceptional: Outstanding focus and execution
++ Capable: Good but with room for improvement
+ Limited: Lacking in execution and use cases
– Not applicable or absent
Table 4. Emerging Technologies Comparison
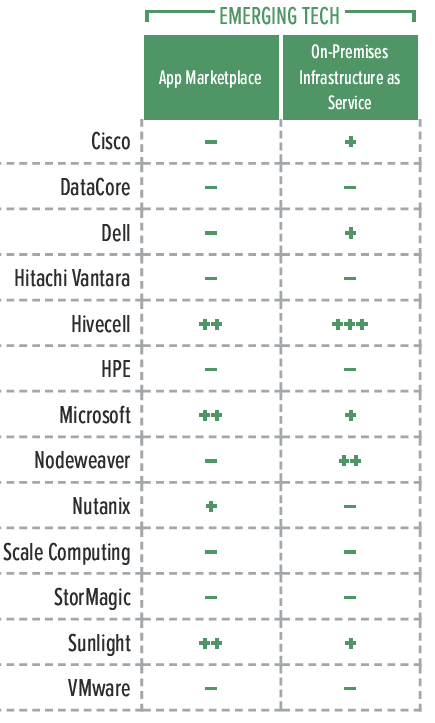 +++ Exceptional: Outstanding focus and execution
+++ Exceptional: Outstanding focus and execution
++ Capable: Good but with room for improvement
+ Limited: Lacking in execution and use cases
– Not applicable or absent
By combining the information provided in the tables above, the reader can develop an understanding of the technical solutions available in the market.
4. GigaOm Radar
This report synthesizes the analysis of key criteria and their impact on evaluation metrics to inform the GigaOm Radar graphic in Figure 1. The resulting chart is a forward-looking perspective on all the vendors in this report based on their products’ technical capabilities and feature sets.
The Radar plots vendor solutions across a series of concentric rings, with those set closer to the center judged to be of higher overall value. The chart characterizes each vendor on two axes-balancing Maturity vs. Innovation and Feature Play vs. Platform Play-while providing an arrow that projects each solution’s evolution over the coming 12 to 18 months.
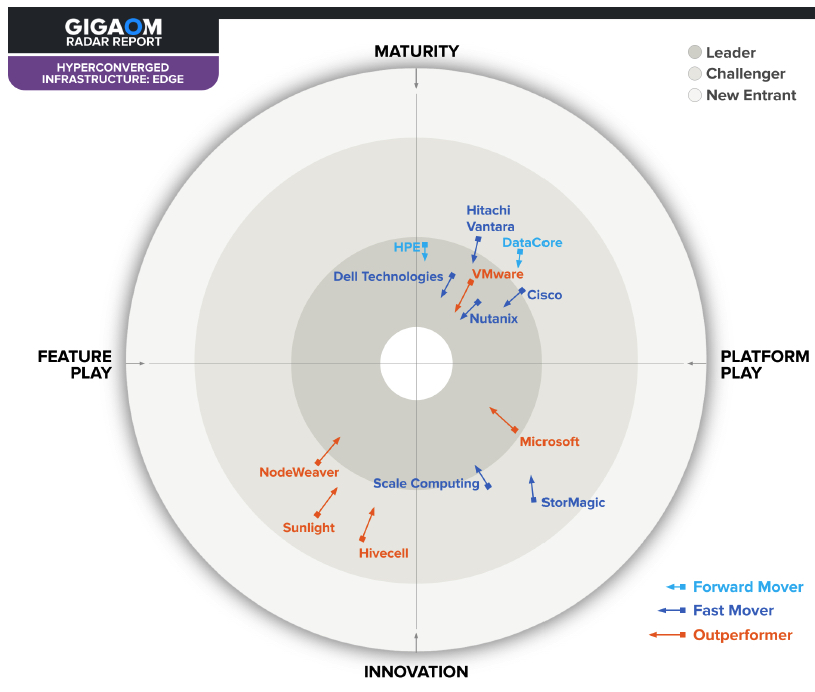
As you can see in the Radar chart in Figure 1, edge HCI is an emerging category with multiple approaches to solving problems. The well-known enterprise server vendors target the near-edge HCI with scaled-down versions of their enterprise HCI. The solutions for near edge look similar to ROBO solutions, although usually with more locations than most ROBO deployments.
Feature Play products that target the far edge-such as Sunlight, Hivecell, and NodeWeaver – are more likely to be newer companies and focus on a mixture of containers and VMs to run the workloads. These companies are highly innovative and often cooperate with one another to bring complete solutions to market. For example, Hivecell has an option to run the Sunlight HCI software on Hivecell hardware.
We expect to see more entrants in this sector as it becomes clear that HCI architectures can help organizations address some limitations of Kubernetes foredge applications.
5. Vendor Insights
Cisco HyperFlex
Firm’s strategy around HCI and, in general, around infrastructure management is based on a holistic management layer provided by Cisco Intersight. The company has committed to accelerating the release cycle of new versions of HyperFlex. Users will eventually be able to get an end-to-end monitoring and management tool that abstracts all infrastructure components, including select non-Cisco hardware, and provides a common UI for provisioning, monitoring, and management of the entire infrastructure. For the moment, however, only Cisco hardware and HyperFlex are supported, and it may still be some years before we see wider hardware and software support.
Using a minimum of 2 nodes, the solution can employ short-depth servers for locations that have communications racks rather than server racks. Fleet deployment, management, and automation are available, and additional cloud services, including a cloud witness for remote two-node clusters, are aimedat simplifying the infrastructure while keeping costs at bay. The existing HyperFlex platforms suit near-edge deployment, and Cisco has other hardware platforms more suited to the far edge and is working on support for more specialized edge hardware for HyperFlex.
HyperFlex uses a vulnerability stress adaptation model for SDS, with support for both compute-only nodes and storage plus compute to enable scaling to suit different workloads. Both compute and storage nodes run IOVisor software, a layout-aware client for HyperFlex storage that allows direct retrieval of data by compute nodes. The vulnerability stress adaptation model implements a log-structured file system, which allows instant storage snapshots without impacting performance. Replication to another HyperFlex cluster can also be enabled in the storage layer; PowerShell commands are provided to automate DR failover. Customers can use either these HyperFlex functions or hypervisor-based capabilities, such as VMware Site Recovery Manager. Similarly, a number of backup vendors support HyperFlex storage integration for data protection, as well as hypervisor layer integration.
Users can create edge-core solutions to replicate data from the edge to the core for backup and DR purposes. And the vendor is investing heavily in the cloud to provide additional integrated services for its customers.
Last but not least, the solution supports both Cisco and third-party Kubernetes solutions on both its native and VMware ESXi hypervisors.
Strengths: The vision apparent in the roadmap around Intersight and HyperFlex is exciting. Cisco’s offering will become more flexible and will provide multiple solutions to customers.
Challenges: Cisco is showing strong acceleration, but execution of its roadmap will continue to be key to bringing additional features and integrations to users. Support for SFF servers will help reach more edge use cases.
DataCore
Its SANsymphony is an SDS product that can be deployed as a virtual storage appliance (VSA) on a hypervisor or the public cloud. SANsymphony offers robust storage virtualization and is able to consume FC, iSCSI, and local storage, presenting virtualized storage volumes to hypervisors or other consumers such as in-guest iSCSI initiators or physical servers. The storage virtualization functionality includes de-dupe, compression, and thin provisioning, as well as automated tiering across the various consumed storage devices. Aggregating DAS from multiple nodes into redundant shared storage was a large initial value proposition for HCI, and SANsymphony expands on this capability by integrating with existing non-HCI storage. An existing SAN can be virtualized behind SANsymphony as an additional tier of storage.
SANsymphony HCI storage uses 2-way mirroring for HA, and it’s possible to establish a third mirror to retain HA during maintenance or after a node failure. It can take snapshots and replicate these to another site for DR. Replication can be integrated with VMware Site Recovery Manager (SRM) for failover automation and testing. SANsymphony can also journal and timestamp every write for CDP, which allows DVR-like point-in-time recovery.
One unusual aspect of the VSA is that the SANsymphony software installs onto a Windows server rather than a Linux machine. As a result, SANsymphony can install in the parent partition on a HyperV server, removing the overhead of a VSA OS. For large-scale deployment, both the initial deployment and ongoing operations can be automated through a REST API, PowerShell, or a command line interface (CLI). DataCore Insight Services provides web-based analytics and alerting, with pre-failure alerting. Most of the automation and alerting is implemented by VAR partners that specialize in integrating products, including DataCore’s, for their customers.
Eliminating the requirement for a SAN to build a highly available virtualization platform is great, but HCI also simplifies and integrates the management of the virtualization, with DataCore leaving all of the management of the virtualization platform to either VMware or Microsoft, and integrating only with the hypervisor storage management layer. The company reports that some SANsymphony customers have highly regulated or locked-down environments. These environments probably need segregation of duties more than a VM-centric HCI platform might easily allow. SANsymphony administration access does not provide or require any VM or network administrative access.
Strengths: SANsymphony is a simple yet complete solution that eases the path to hyperconvergence. The company has been making steady progress withnew features and optimizations.
Challenges: The fleet management for large numbers of SANsymphony deployments at the edge is left to VARs rather than being apart of the company’s platform.
Dell Technologies VxRail
Dell Technologies’ extensive product portfolio gives users plenty of choice in designing their infrastructures for hyperconverged solutions. One solution,VxRail, has been particularly well received and boasts one of the largest ecosystems and numerous certifications for enterprise use cases. Developed in conjunction with VMware, VxRail takes full advantage of the entire VMware Cloud Foundation (VCF) stack with integrated tools to simplify deployments and automate management operations. Dell is a traditional server vendor, so VxRail naturally targets near-edge locations with rackmount server options,although more edge-friendly VD-4000 nodes have been announced for release in 2023. The firm also offers a variety of other products for both near- and far-edge deployment.
Automated updates are key to VxRail’s value, eliminating the manual compatibility validation and testing that customers typically complete to avoid post-upgrade issues. The VxRail team validates a collection of firmware, drivers, and hypervisor updates vs. the VxRail hardware list and packages the validated collection for deployment. Customers can simply deploy the versioned collection of updates to one or more clusters. The deployment process is optimized to minimize the time that individual nodes spend in maintenance mode, which in turn minimizes disruption to VSAN for re-sync activity.
While VxRail is not specifically designed for the edge, users can select nodes from a number of models for various use cases, including ROBO and SMBs. For small sites, particularly edge, the firm offers a single node deployment as a VxRail satellite node.
Dell also provides its own managed service that users can access to create a cloud experience for infrastructures physically installed in their data centers. Kubernetes support is available through VMware Tanzu Kubernetes Grid. Automated full-stack system lifecycle management is a key aspect of this solution and heavily contributes to improving its TCO.
VxRail includes a marketplace of solutions that integrate with a VxRail cluster, such as Dell RecoverPoint for VMs, as well as 3rd-party applications that canbe easily deployed. Dell’s hyperconverged solutions can be acquired via traditional Capex models or new flexible subscriptions through Dell Apex.
Strengths: VxRail is a well-integrated solution for large organizations, with an extensive partner ecosystem and a cloud-like experience, thanks to Dell Cloud. There are a number of models to choose from, including SMB and ROBO dedicated nodes.
Challenges: The new VD-4000 nodes need to prove firm’s ability to deliver VxRail optimized for edge use cases that involve several small sites characterized by very few VMs, space efficiency, and very low power consumption needs.
Hitachi Vantara
Its compelling hyperconverged solution is based on VMware’s vSAN and VCF, with additional features to automate first deployments and Day2 operations. This includes end-to-end system lifecycle management, fast provisioning, and seamless integration with existing Hitachi Vantara storage systems. These rack-server-based products suit near-edge deployment into telco data centers or branch office data closets.
For edge-deployment use cases, Hitachi’s Unified Compute Platform (UCP) HC can be paired with Lumada for IoT and Pentaho for analytics. The UCP edge is likely to be deployed in a manufacturing plant or some other operational technology deployment. Alternatively, both VMware Tanzu and RedHat OpenShift are supported for container orchestration on top of UCP, as is Hitachi’s own Kubernetes (HKS) platform. The Hitachi Content Platform (HCP) can also be licensed with UCP to provide S3-compatible object support with object-level replication between sites, which is potentially very useful for replicating backup images from ROBO and Edge UCP to central data centers.
Customers with a significant commitment to Hitachi will find UCP HC to be a fully featured HCI platform and may well deploy UCP HC at regional location sto complement UCP RS (Rack Scale) in larger data centers. The Lumada and Pentaho combination may encourage application owners to bring UCP into manufacturing and IoT deployments where Hitachi might not already have a footprint.
The company doesn’t provide its own cloud services, but because of the VMware VCF stack, users can take advantage of multiple solutions from major cloud providers based on the same stack. Kubernetes support is now available through VMware Tanzu Kubernetes Grid, the Hitachi Kubernetes Service,and RedHat OpenShift.
The firm is expanding its subscription program to include HCI solutions, but traditional purchasing options are available as well.
Strengths: This solution is an interesting value proposition with a solid stack and well-designed automation and management tools. The Hitachi Vantara UCP HC series complements Hitachi Lumada Edge Intelligence solutions.
Challenges: Large, distributed infrastructures for edge use cases can be expensive compared to other solutions dedicated exclusively to edge use cases.
Hivecell
It has a hardware appliance plus software platform purpose-built for edge computing, particularly for edge locations with little infrastructure and possibly no local staff. This hardware and software combination, along with a monthly billing model, delivers edge as-a-service. These edge locations generate significant amounts of transient data, and the edge applications respond to this data in near real time and return smaller amounts of persistently valuable data to a central location, either on-premises or in the public cloud. The SFF hardware appliances have a unique stacking design that the company calls a hive, rather than a rack model. A single power cable and a single network cable connect to the hive and are shared by the appliances in the stack through connectors on the top and bottom of each appliance. Appliances have built-in batteries for power protection and Wi-Fi as a backup to the wired network, so lifting a node off the stack does not break the cluster.
The nodes do not require special power or cooling, as they are designed to run in closets or in vehicles rather than needing a data center. This unusual hardware design reduces training and skill requirements around on-site operations-for example, a courier with no prior training could add a node to a stack or replace a failed node. Another unusual aspect is that both the hardware appliances and the central management service (Hive Control) are delivered only as a service billed monthly. Customers can increase or decrease appliance numbers, or even change the model of appliance as required, with no capital expenditure. The company is partnering with Advantech to deliver the edge as a service platform to specialized hardware platforms in addition to their own stackable nodes.
The central control platform, Hive Control, is used to onboard devices through hardware ID integration with appliance fulfillment – there is no need to stage the appliance before it is sent to its end location. Hive Control is then used for the ongoing management and monitoring of the deployed appliances. HiveControl provides unified management of VMs and containers, potentially across thousands of hives.
The firm expects that many customers will want to follow DevOps and infrastructure as code (IaC) methodologies, integrating the infrastructure configuration with their application build and automating both with continuous integration/continuous delivery (CI/CD) pipelines. Applications can be run inVMs, using Linux’s kernel-based VM (KVM) as a hypervisor, in containers, or a combination of both. The VMs use appliances based on Intel CPUs; containers can also use advanced RISC machine (ARM) – based nodes with far smaller power requirements. The ARM nodes include NVIDIA CUDA cores to enable higher-performance, ML use cases. A single stack can have a mix of Intel and ARM nodes, possibly to mix VMs and containers, although individual applications are usually tied to a particular CPU architecture.
Strengths: The custom platform ideally suits locations that are never visited by IT staff yet require reliable infrastructure. An all-inclusive monthly cost model is innovative.
Challenges: The platform is foreign to enterprise IT organizations and different from the organizations’ existing platforms, thus requiring new skills to operate.
HPE SimpliVity
It is one of the most mature and feature-rich platforms on the market. It supports VMware ESXi and provides a clear, simple, and cost-effective migration path for existing HPE ProLiant customers who want to move to hyperconvergence.
The platform has always been focused on efficiency, with always-on global de-dupe and compression enabling efficient data protection and replication for DR. A single-node deployment at a near-edge location can have data protection and recovery by replication, or a cluster can scale out to meet data center requirements. One design consideration is that a SimpliVity cluster must contain uniform hardware – upgrading to newer hardware requires a new cluster be built and the VMs migrated using the efficient replication.
One of the main factors differentiating SimpliVity is its core storage architecture, which is designed to optimize the data footprint. This approach allowed the company to build a solid set of data protection services – including snapshots, backups, and remote replication for DR – that are particularly bandwidth-conscious, an important feature for remote site data protection. In addition, InfoSight, the AI-based analytic platform now available for most firm’s products, offers a complete view of the entire stack and helps users with daily operations, system tuning, and reporting, as well as support and capacity planning. Initial deployment is streamlined as well, so end users can get the system up and running quickly. Daily operations are also simple, with an easy-to-use interface and good integration with the hypervisors. SimpliVity supports Kubernetes through its container storage interface (CSI) plug-in and virtualization platforms like VMware Tanzu.
Users can choose from a range of preconfigured appliances, including high-capacity and workload-specific nodes, as in the case of virtual desktop infrastructure (VDI). SimpliVity is part of the HPE GreenLake program, which provides added flexibility and a cloud-like purchasing experience.
Strengths: SimpliVity is a robust platform that is easy to use and has the solid performance and capacity optimization associated with top-notch analytics.
Challenges: SimpliVity does not scale to large numbers of clusters within a federation; although customers can deploy multiple federations, each is a separate management domain.
Microsoft Azure Stack HCI
Company’s strategy for Azure Stack HCI has continued to evolve, and it is practically an extension of its Azure Cloud. Users can download and install a specific OS designed for HCI and opt for the pay-as-you-go model based on the resources used, starting at one core per day. Deployment is simplified, thanks to wizards and automation tools aimed at speeding up the provisioning of infrastructures of any size. System management is delivered through a management console available on Azure. Support is available via Azure Cloud as well, further simplifying the entire process while creating a consistent user experience (UX) across different services and environments.
The certified hardware list for Azure Stack HCI has grown over the last year. A range of rack-mount servers that suit near-edge locations is available. There are also a few specialized hardware platforms that suit far-edge deployment, such as SFF servers with 2 nodes in a single chassis for high availability. Azure Stack HCI now also supports a single-node deployment, making it more cost effective at the far edge. Infrastructure lifecycle management, including firmware upgrades, is possible via select hardware vendors. The improvements in storage flexibility have continued, with better support for Day 2 operations such as changing VM disks from thick provisioned to thin provisioned in bulk, reclaiming usable storage space.
Azure Stack HCI is the only HCI platform from a major public cloud provider, and its unique value stems from its ability to bridge from on-premises to Azure. Bringing Azure services to Azure Stack HCI is a priority for Microsoft. ARC (from Synopsis) and ARM both already support Azure Stack HCI for unified management and IaC workload deployment, respectively, along with Azure Monitor Insights for workload analytics. Azure Backup and Site Recovery allow data protection and DR from Azure Stack HCI, integrated with Azure. The Azure Kubernetes service is available with a local control plane to enable intermittently connected clusters, and Azure Virtual Desktop is in preview. Microsoft is adding services like Azure SQL, functions, and app services, which will enable more cloud-native application deployments on-premises.
Azure is a public cloud that is designed to accommodate existing on-premises applications, and Azure Stack HCI accommodates those applications that can’t be moved to the public cloud. As Microsoft adds more services to Azure Stack HCI, building more cloud-native capabilities around these applications,on-premises deployment will become more practical. Azure Stack HCI is attractive to customers who have made a significant commitment to Microsoft and Azure. Its value to them will increase as more Azure services become available on-premises.
The company doesn’t offer a complete fleet management solution for physical hardware yet, but it is quite clear that Azure Stack HCI can support infrastructures of any size for SMB, ROBO, and edge use cases.
Strengths: Azure Stack HCI acts as an extension of Azure Cloud, improving the overall UX and purchasing model while also providing a seamless hybrid cloud UX.
Challenges: Even though Microsoft has an enticing roadmap for Azure Stack HCI, hardware fleet management is not yet available, making it harder to manage large, distributed infrastructures.
NodeWeaver
It is solely focused on delivering an edge platform for applications. Scalability is both out and down, including not only many nodes and clusters but also low-resource nodes and small clusters. The platform supports all those nodes and clusters by automating every task possible, which minimizes the need for human intervention. In addition, it uses minimal supporting infrastructure. Clusters are configured through DNSOps,where domain name system (DNS) entries provide information for nodes to bootstrap and join the cluster. Using DNS alone is simpler than using a pre-boot execution environment (PXE), which requires dynamic host configuration protocol (DHCP) and trivial file transfer protocol (TFTP) in addition to DNS. The firm has slimmed down the minimum system requirements to under 1GB of RAM by separating optional components into snap-ins, VMs that integrate additional functionality such as the local management interface, or backup and DR capabilities.
Within each node, an autonomic engine manages mapping the physical hardware of each node to the policies attached to the cluster. The autonomic engine now also accounts for environmental factors such as temperature and vibration to optimize system availability and data protection. Hardware-independent cluster policies accommodate much simpler upgrades between gens of hardware, or any other requirement for non-uniform cluster hardware. Nodes within a cluster do not need to have the same CPU, RAM, or storage configuration, and they can range from as small as 2 CPU cores and8GB of RAM to multiple CPU sockets and hundreds of gigabyte of RAM. Policy-based management allows the autonomic engine to reconfigure the cluster when hardware fails or new hardware is deployed rather than requiring manual reconfiguration. The autonomic engine is also responsible for ongoing optimization, automated updates, and pre-failure detection.
As an edge solution, NodeWeaver automation integrates into a customer’s wider application platform. Both an API and a CLI are available for management, along with a variety of software development kits (SDKs) for the API and plug-ins to support declarative tools such as Ansible and Terraform. NodeWeaver integrates with enterprise Kubernetes distributions such as OpenShift and both the Azure and Amazon Kubernetes cloud services. VMs can be operated ina fully virtualized KVM for compatibility with existing VMs. Alternatively, NodeWeaver uses paravirtualized KVM for newer VMs and particularly to support containers and Kubernetes.
The storage cluster stores compressed data in chunks, as objects with metadata to assemble the chunks into a storage object. Nodes might have different sizes and types of storage devices, and the storage engine lays chunks out to get the most consistent application performance. Snapshots are simply point-in-time copies of the metadata: with no impact on performance, and they can be replicated to S3-compatible object storage for data protection. The software is installed on the customer’s choice of hardware by booting from a standard USB key, which registers the host with the firm’s web service based on its hardware MAC address. For secure environments without Internet access, the configuration can be placed on the USB key and managed from the secure network.
The choice of NodeWeaver as an edge HCI platform is likely to be driven by the application(s) to be deployed at the edge rather than selecting it to be an all-purpose platform for all locations and forcing applications to fit to the platform.
Strengths: A very light and efficient platform, scales to large numbers of clusters without requiring large supporting infrastructure.
Challenges: The very different control mechanism (DNSOps) may take some time for customers to embrace.
Nutanix
It is a global market leader in enterprise HCIs, with a take on edge infrastructures that is quite different from the competition. Customers can start with a minimal 1-node configuration, which can be a good solution for ROBO use cases in which HA is not a requirement. However, the resources needed to run the infrastructure make for a relatively expensive solution when compared with products specifically designed for edge deployments. Fortunately, users have plenty of choices, including firm’s Hypervisor (AHV) instead of VMware ESXi and Hyper-V, to mitigate costs and simplify the entire stack.
Company’s management and automation tools are well designed and scalable, but the real differentiator comes from the additional features the company is building into its platform as a service (PaaS) offer. In fact, Nutanix Prism tremendously simplifies the development and deployment of custom applications for edge use cases in industrial scenarios, with integrated analytics and AI frameworks that can be leveraged both on-premises and in the cloud. The availability of a Nutanix Kubernetes Environment (NKE) for this platform gives additional options to users considering future Kubernetes deployments at the edge. Other Kubernetes distributions are also supported, including those from public cloud providers. The solution also offers strong system lifecycle management functionality to ease maintenance and upgrades for the entire stack (hardware and software).
Another enabling technology is Nutanix Cloud Manager (NCM), which brings together several of the management and control products under a single umbrella. NCM Self-Service provides automated self-service application deployment and lifecycle management, and is now available as a SaaS product, providing a portal for hybrid-cloud automation. NCM Security Central adds security operations, monitoring, and compliance reporting, while NCM Cost Governance supplies hybrid-cloud cost governance, rounding out the hybrid-cloud portfolio to simplify operations beyond on-premises HCI.
The software is available for major hardware and cloud providers on a subscription basis. Its channel and technology partner ecosystems are very extensive and provide additional assurance about the overall flexibility of the solution.
Strengths: An end-to-end solution for building edge-to-cloud infrastructures with integrated and portable services. It has a strong ecosystem and partner network.
Challenges: The platform cost may be a significant issue for small sites.
Scale Computing
It offers a complete end-to-end solution based on its own virtualization stack, which is designed for small, medium, and distributed enterprises with a particular focus on edge use cases. Even though its ecosystem of technology partners is still limited, in the last couple of years, the company has signed important agreements with key partners, such as IBM, Lenovo, Google Cloud, Acronis, Leostream, Parallels, Milestone, and Intel. It is noteworthy that the company is often praised by its large user base for the quality of its support, and it has a very friendly approach with channel partners as well.
When it comes to edge computing deployments, the firm offers one of the most cost-effective solutions on the market. The Scale Computing HE100 is based on Intel NUC compute nodes connected to a clever networking solution on the back end that doesn’t require external switches. This brings the cost and the number of components down to a bare minimum, making it for unattended sites. Two HE100 appliances, based on Intel NUC hardware, can fit on a single shelf under the counter of a retail store and provide a highly available platform for multiple applications, such as PoS and signage. For near-edge deployment, the firm has rackmount HE500 servers, which deliver more performance for larger VM deployments. Dozens of these self-healing clusters can be managed centrally from a web console without sending technicians to the site. For more industrial deployments, Scale Computing partners with Lenovo for environment-tolerant servers.
The company has fleet management to provide a complete view of the entire infrastructure and automate operations on large-scale deployments. This includes zero-touch provisioning for clusters; the nodes can be delivered to the site without pre-staging the cluster configuration or on-site expertise. This SaaS solution can be leveraged as well by MSPs, who can deliver bespoke applications to shared customers. DR on Google Cloud is an option that allows users to minimize upfront infrastructure investments.
Finally, ease of deployment and ease of use are other areas in which the firm has invested heavily. New clusters can be installed in minutes and day-to-day operations are simplified, thanks to clean, well-designed dashboards. And the latest hardware appliances have improved VDI capabilities due tographical processing unit (GPU) support.
Strengths: This is an end-to-end solution that is easy to deploy and use. It is cost-effective, with tools designed to manage large edge infrastructures.
Challenges: Even though the solution ecosystem is growing and all major use cases are covered, options are still limited.
StorMagic
It has one of the few solutions designed specifically for edge and SMB use cases. With more than 2,000 customers across all industries, and partnerships with the most important hardware manufacturers and cloud providers, it has built a simple yet very efficient product with strong security features and additional cloud services to ease deployment while improving the UX.
Usually deployed with VMware ESXi, StorMagic SvSAN also supports the Hyper-V and KVM hypervisors. It can run on any x86 hardware, with minimal resource needs, in cost-effective 2-node configurations. Leading server manufacturers such as HPE and Lenovo also offer servers with SvSAN preinstalled, which simplifies the acquisition process. The management platform enables users to manage thousands of sites from a single console, and the cloud-based witness service further eases deployment of large, distributed infrastructures.
SvSAN usually has a 2-node, synchronous mirrored configuration for HA, with a shared witness to prevent split-brain during network failures. The shared witness, which can support up to 1,000 SvSAN clusters, is usually a VM located in a central data center. A 3rd mirror is supported for maintaining HA during maintenance or after an initial failure. Additional compute-only nodes can be added: which consume the HCI storage over iSCSI. SvSAN does not have data reduction features. In small edge locations, the compute resources required for data efficiency are more costly than the small additional storage capacity. SvSAN can use a SSD as a cache to accelerate I/O in a hybrid storage configuration, in which HDDs provide cost-effective capacity and the intelligent use of an SSD cache reduces the need for a virtual SAN appliance (VSA) RAM to provide performance.
The firm has invested heavily in security over time, with a specific product for encryption key management (SvKMS) that complements the HCI solution. For customers with enterprise key management already in place, SvSAN can also work with 3rd-party KMS solutions.
Users can choose between perpetual licenses with support or subscriptions based on capacity, with additional options for improved security, performance, and other services.
Strengths: Designed for edge-computing deployments with a lightweight and resource-savvy architecture, this solution is easy to manage at scale and very cost effective. Data encryption and integrated key management are also strong.
Challenges: Data protection, such as backup and DR, requires external products.
Sunlight
It has 2 core products: NexVisor HCI stack and the Sunlight Infrastructure Manager (SIM). Both are software and are licensed together on a monthly subscription basis with all features included-a very simple licensing model. NexVisor is designed to have very low overhead while delivering near-native performance for modern storage and networking hardware. The low overhead reflects company’s philosophy that more hardware is not always the best solution; using what you have more efficiently is better. As an edge-focused product, SIM supports thousands of clusters under a single console. The SIM product includes an application marketplace from which third-party applications can be deployed to NexVisor clusters.
The firm expects to see a variety of processor architectures at the edge; currently, both ARM and x86 are supported, with RISC-V on the roadmap. A common feature of the smaller system hardware deployed at the edge is that I/O capability tends to dominate over raw CPU power. If more CPU power is required for AI, it’s often implemented via GPUs rather than CPUs. Sunlight supports NVIDIA Jetson as a hardware platform, and it has optimized NexVisorfor the massively parallel I/O that these systems can deliver. The mission is to handle the massive amount of data being generated at the edge that also must be processed at the edge rather than forwarded to the cloud.
Typical customers require exactly the same application set at dozens to thousands of locations, with minimum cost, power, heat, space, and noise at each location. Often, each location will have a mix of VMs and containers. This tends to mean that containers are deployed as a fixed collection at each location, without the overhead of a container orchestrator like Kubernetes at each location. While some customers are building new applications in containers, there is a surprising prevalence of Windows applications that require x86-based VMs. Deployment is usually with partners such as Lenovo and Advantech on specialized and edge-optimized hardware.
One of firm’s unusual characteristics is the amount of its technology that has been developed in house. The NexVisor stack is unique to Sunlight, although it does derive from Xen and so has good support. Sunlight cluster nodes also use a proprietary network protocol rather than using TCP/IP like most HCI products. Using a specialized protocol for node-to-node communication reduces the required resources as well as the attack surface and risk from zero-day vulnerabilities in commonly used libraries. The node that is elected cluster leader uses TCP/IP to talk to SIM, with a single IP address per cluster to allow access through the firewall to SIM. Recent development at the company has included a focus on security, both for use cases such as photoprinting kiosks in public locations and to support a zero-trust model in which all networks and devices are untrusted until proven safe.
Sunlight is a software product, so it partners with hardware vendors for supported hardware configurations. The vendors tend to have specialized hardware for retail and manufacturing or industrial environments. High-performance platforms will include NVMe storage and Intel Optane, whereas NexVisor’s highly efficient parallel I/O can take advantage of the full power of the hardware. Though the Sunlight platform can run on datacenter servers, its greatest strength is delivering excellent performance with a small footprint.
Strengths: Offers turnkey HCI with hardware partners at edge scale. The platform is designed from the start for modern CPUs with strong I/O capabilities.
Challenges: Retaining support for legacy x86-based VMs may retard feature development in ARM, RISC-V, and container-based capabilities.
VMware
VMware Cloud Foundation is the market leader in enterprise virtualization. Already at the base of many HCI solutions from third-party vendors, VMware has, in the last few years, expanded its reach to edge use cases as well. In fact, it’s possible to run a VMware VCF cluster in a 3-node configuration, making the solution a viable option for edge deployments and scenarios where it is necessary to run a small infrastructure in a remote location.
Near-edge deployments might be on rack-server hardware, while far-edge deployments could be on SFF machines from vendors specializing in industrial premises computers. VMware also ported its ESXi hypervisor to ARM CPUs, with an experimental version of the product available for free download, hinting at future support for tiny, power-efficient, the infrastructures for IoT and other advanced use cases. VMware provides several licensing options to meet the needs of different organizations, including the new vSphere+ and vSAN+ subscription licenses.
The main advantage of VCF at the edge is its ecosystem. In fact, the stack is totally integrated, and tools like vCenter and vRealize Suite for automation and orchestration enable users to manage the hardware and software lifecycle of large, distributed infrastructures with the same tools already in place for datacenter operations. Firm’s edge strategy includes more than the HCI platforms, with software-defined wide area networks (SD-WAN) and virtual desktops.
The company has made significant investments in the cloud, and the platform is now available from all major cloud providers, enabling organizations of all sizes to take advantage of these services. It also has a compelling and cost-optimized DRaaS option for its customers. Last but not least, it is quickly becoming a credible and strong player in the Kubernetes realm, thanks to the native integration and the Tanzu portfolio.
Strengths: The company is a market leader with solid solutions for organizations of all sizes. VCF is now available on-premises and in the cloud, with additional cloud services planned for the future, for greater flexibility.
Challenges: VCF and vSAN may be expensive for deployments where non-traditional infrastructure approaches are taken at the edge to optimize cost savings.
6. Analyst’s Take
If your edge locations can accommodate rackmount servers, your HCI needs are similar to a ROBO use case with a massive number of offices. If your edge locations don’t look like an office, you probably need a solution that supports servers that don’t look like servers.
The near-edge locations where you deploy servers from Cisco, Dell, Hitachi, HPE, or Scale Computing are probably places that engineers-yours or the server vendor’s – can visit but don’t want to. Racking and cabling will be done on-site, but ongoing operations will be remote. The applications you deploy can be a mix of VMs and containers on Kubernetes clusters because the HCI platform is still a general purpose compute service.
Far-edge locations-such as delivery trucks, oil wells, and wind farms-are usually much harder to visit. Deployment of Scale Computing or Hivecell clusters, possibly with Sunlight running on them, doesn’t require an IT specialist; a diesel mechanic can install the boxes during a service visit.
We expect that over time, the far edge will be dominated by low-power processors and solid-state storage, with no moving parts to fail. Applications will always be king at the edge, so choosing an edge HCI platform starts with the application.



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter


