






Unstructured Data Management: Infrastructure-Focused Solutions
Leaders being Hitachi Vantara, NetApp, Komprise, Cohesity and Data Dynamics
This is a Press Release edited by StorageNewsletter.com on May 20, 2022 at 2:02 pmThis market report from GigaOm was written on March 15, 2022 by analysts Enrico Signoretti and Max Mortillaro.
GigaOm Radar for Unstructured Data Management: Infrastructure-Focused Solutionsv3.01
1. Summary
Exponential data growth is no longer news, with unstructured data already accounting for 80% to 90% of the total data stored in enterprise storage systems.
Human-generated data is now joined by machine-generated data that is growing even more quickly and needs infrastructures with different characteristics.
Managing storage capacity with efficiency has become more accessible, less expensive, and reasonably priced, thanks to scale-out storage systems for files and objects. At the same time, the cloud offers the opportunity to expand the number of options available in terms of performance, capacity, and cold data archiving. The proliferation of data silos is an issue, though, and a trend accelerating alarmingly because of new multicloud IT strategies and edge computing.
Moreover, in this multicloud scenario, new demanding regulations like GDPR, CCPA, PIPL, and others require a different approach. Data protection and management processes are crucial for compliance with ever-changing business requirements, laws, and organization policies.
Furthermore, data sovereignty regulations impose restrictions on physical data location and data flows, requiring organizations to adequately segment access to resources by location and identify and geo-fence impacted datasets. Solutions that support these regulatory frameworks and are capable of handling data privacy requests-like Data Subject Access Requests (DSARs), identifying and classifying personally identifiable information (PII), or even taking further action with right to be forgotten (RtbF) and right of erasure (RoE) requests-can simplify compliance operations.
We’re coming to a point where it may seem that storing data safely and for a long time does not benefit an organization and can quickly become a liability.
On the other hand, with the right processes and tools, businesses can do more with their data than ever before, mining it for hidden insights and gaining incredible value in the process, transforming it from a liability into an asset. Examples of this transformation are now common across all industries, with enterprises of all sizes reusing old data for new purposes, thanks to technologies and computing power that weren’t available a few years ago.
With the right unstructured data management solutions, it’s possible to:
• Understand what data is stored in the storage systems, no matter how complex and dispersed.
• Build a strategy to intervene on costs, while increasing the ROI for storage.
Depending on the approach chosen by the user, there are several potential benefits to building and developing a data management strategy for unstructured data, including better security and compliance, improved services for end-users, cost reduction, and data reusability. The right data management strategy enables organizations to mitigate risk and make the most of opportunities.
2. Market Categories and Deployment Types
To better understand the market and vendor positioning (Table 1), we assess how well solutions for unstructured data management are positioned to serve specific market segments. This radar will cover infrastructure-focused solutions and provide insights as to whether evaluated solutions can also meet business-focused solution requirements. Business-focused solutions will be covered in a sister radar; however, some solutions overlap and may appear in both radars, although with different placements and evaluations.
• Infrastructure focus: Solutions designed to target data management at the infrastructure level and metAdata: including automatic tiering and basic information lifecycle management, data copy management, analytics, index, and search.
• Business focus: Solutions designed to solve business-related problems, including compliance, security, data governance, big data analytics, e-discovery, and so on.
In addition, we recognize two deployment models for solutions in this report: user-managed solutions and SaaS.
• User-managed solution: Usually installed and run on-premises, these products often can work well in hybrid cloud environments.
• SaaS solution: Based on a cloud backend and usually provided as-a-service, solutions deployed this way work in a manner quite distinct from that of the products in the on-premises category. Traditionally, this type of solution is optimized more for hybrid, multicloud, and mobile/edge use cases.
Table 1. Vendor Positioning
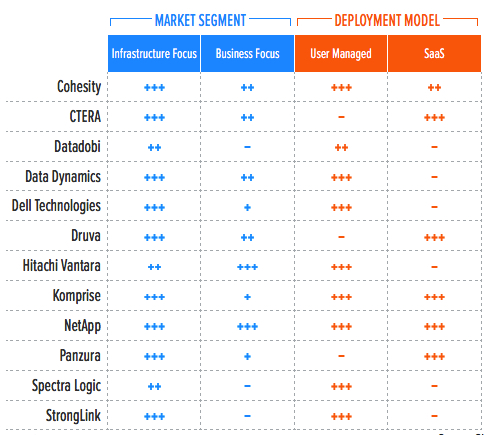
*** Exceptional: Outstanding focus and execution
** Capable: Good but with room for improvement
* Limited: Lacking in execution and use cases
* Not applicable or absent
3. Key Criteria Comparison
Building on the findings from the GigaOm report, Key Criteria for Evaluating Unstructured Data Management Solutions, Table 2 summarizes how each vendor included in this research performs in the areas that we consider differentiating and critical in this sector. Table 3 follows this summary with insight into each product’s evaluation metrics-the top-line characteristics that define the impact on the organization. The objective is to give the reader a snapshot of the technical capabilities of available solutions, define the perimeter of the market landscape, and gauge the potential impact on the business.
Table 2. Key Criteria Comparison
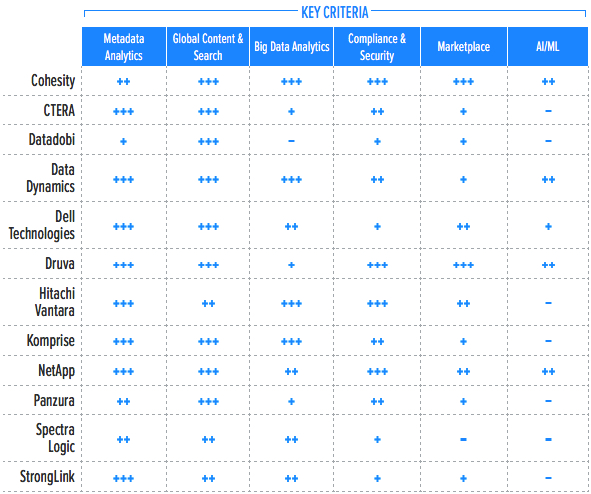
*** Exceptional: Outstanding focus and execution
** Capable: Good but with room for improvement
* Limited: Lacking in execution and use cases
* Not applicable or absent
Table 3. Evaluation Metrics Comparison
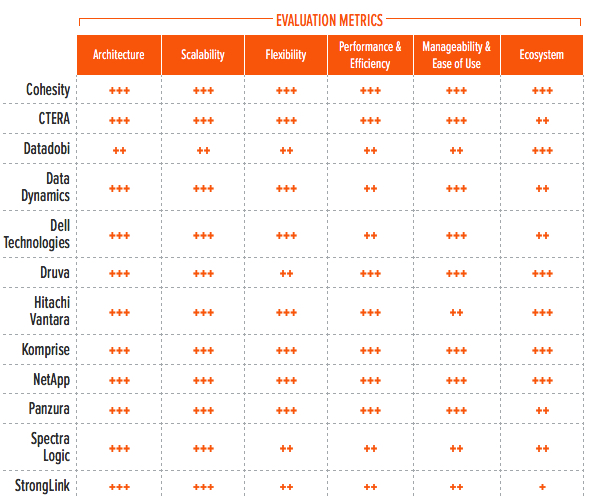
*** Exceptional: Outstanding focus and execution
** Capable: Good but with room for improvement
* Limited: Lacking in execution and use cases
* Not applicable or absent
By combining the information provided in the tables above, the reader can understand the technical solutions available in the market.
4. GigaOm Radar
This report synthesizes the analysis of key criteria and their impact on evaluation metrics to inform the GigaOm Radar graphic in Figure 1. The resulting chart is a forward-looking perspective on all the vendors in this report, based on their products’ technical capabilities and feature sets.
The radar plots vendor solutions across a series of concentric rings, with those set closer to the center judged to be of higher overall value. The chart characterizes each vendor on 2 axes – Maturity vs. Innovation and Feature Play vs. Platform Play-while providing an arrow that projects each solution’s evolution over the coming 12 to 18 months.
Figure 1. GigaOm Radar for Infrastructure-Focused Unstructured Data Management Solutions
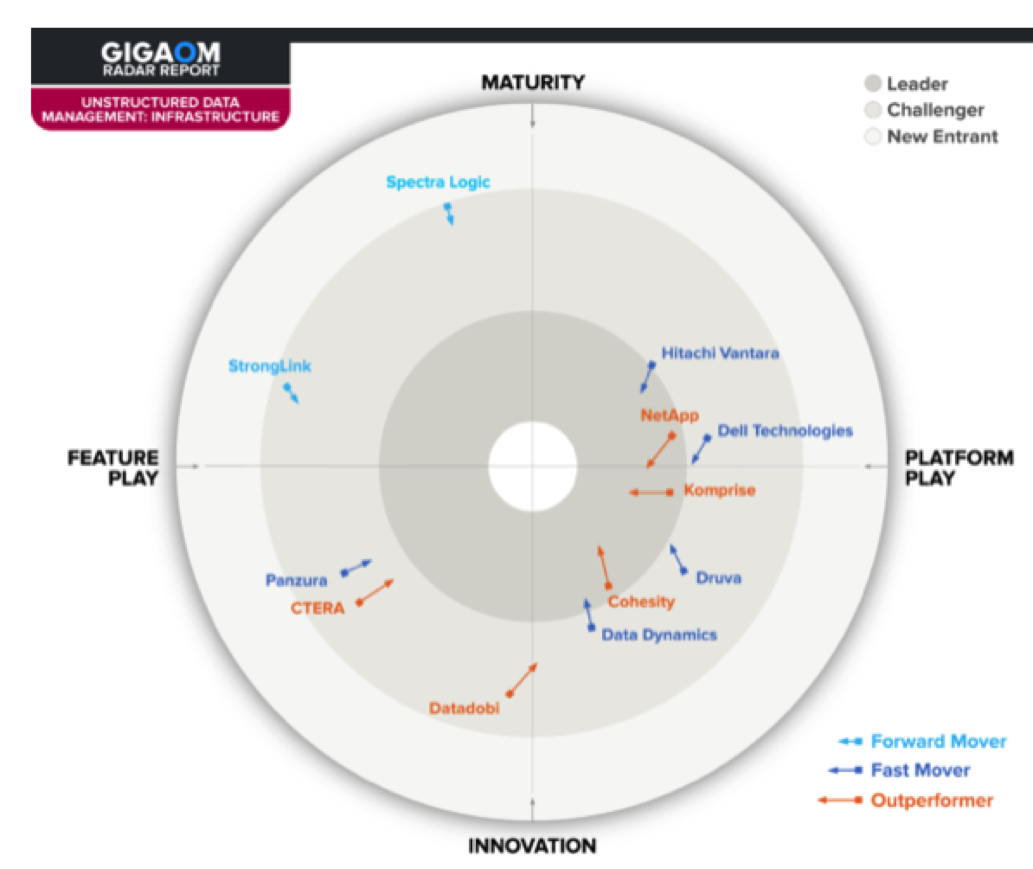
As you can see in the chart in Figure 1, the infrastructure-focused unstructured data management market is particularly dynamic, with 5 outperformers and 5 fast movers out of 12 evaluated solutions. To interpret this radar accurately, readers must consider its emphasis on infrastructure-related activities.
Among all evaluated solutions, Cohesity offers a formidable platform with comprehensive, end-to-end unstructured data management capabilities under a single umbrella, offering a one-stop-shop to organizations seeking the most complete coverage, including privacy compliance. Komprise is another outstanding solution with a slightly different approach: the solution excels with data migration activities, data classification capabilities, and data placement recommendations with actionable insights, as well as a dynamic development pace.
Data Dynamics excels in multiple areas, with a comprehensive and unified solution that combines broad vendor support, petabyte-scale data management, policy-based data copy, and migration scenarios with strong data analytics and classification capabilities.
Druva has a very interesting approach characterized by providing data compliance, search, and analytics capabilities on top of its SaaS-based data protection platform. It includes a broad set of features including AI/ML-based anomaly and ransomware detection. It also encompasses potential ransomware activity detection and a growing set of integrations with industry-acclaimed security and analytics platforms.
Two well-established storage vendors are found in a transformative position, crossing from maturity towards innovation: NetApp and Dell Technologies.
With Cloud Data Sense, NetApp offers unparalleled business-related unstructured data management capabilities, with outstanding handling of DSARs, PII identification, and data classification. Despite its business focus, Cloud Data Sense can also address some of the infrastructure use cases and demonstrates NetApp’s commitment to innovation.
Dell Technologies is also modernizing its portfolio and platforms. Its EMC DataIQ provides a unified system view across Dell, third-party, and cloud storage; it provides solid reporting capabilities with policy-based data management and migration options, and offers an open plug-in development framework.
Hitachi offers a broad ecosystem of solutions, with Hitachi Content Intelligence being the most focused on this report’s key criteria. The solution is mature and proven, with a strong emphasis on business-oriented features such as policies and data workflows, making it best suited for large enterprises. Still, it can also work for infrastructure use cases.
Datadobi provides an interesting perspective. Primarily oriented towards data migration and protection use cases, it has an outstanding roadmap ahead and is executing fast. Therefore, it can transition this year from its current position as a feature player to a platform player, with the first of a series of launches at the end of March 2022.
Panzura and CTERA are two other interesting contenders, notably because of their background as distributed cloud file storage solution providers.
Panzura Data Services is an easy-to-use and effective solution providing data analytics with classification criteria, data insights, and growth patterns, plus various auditing features (including ones that check for regulatory compliance violations) and anomaly detection mechanisms, including ransomware protection.
CTERA’s cloud-based SaaS distributed file storage solution implements an intuitive and interactive data insight visualization platform that, combined with strong multi-tenancy capabilities and new geo-zoning features, enables its customers to define granular, regulatory compliant access policies. It offers integrations with 3rd party security products and has a strong roadmap for 2022 with an upcoming AI/ML-based anomaly detection engine, among other improvements.
StrongLink AI, by StrongLink, implements a single namespace with multiprotocol access to data, making multi-vendor environments easier to manage. It offers automated file migrations, metadata augmentation, and metadata-based search. It could grow into an interesting platform, provided that StrongLink commits to a strong roadmap with increased execution pace.
Spectra Logic delivers a mature and efficient solution focused around information lifecycle management, with automated data movement policies that support targets on-premises and in the cloud, all while maintaining transparent front-end data access. The solution is cost-effective, although more advanced features would be welcome.
5. Vendor Insights
Cohesity
It offers an end-to-end solution designed to tackle data and apps challenges in modern enterprises. It is available both as a software-defined, scale-out solution deployed on physical or virtual servers and as a service from major cloud providers-Amazon AWS, Microsoft Azure, and Google Cloud Platform (GCP).
Users can consolidate disparate workloads, including backup, archiving, file shares, object stores, test/dev, and analytics, onto a single software-defined platform. This approach simplifies the storage, protection, and management of massive volumes of data. On top of the efficient, web-scale distributed file system and integrated data protection, Cohesity offers a growing list of capabilities to address both infrastructure-focused and business-oriented applications.
The Helios management interface provides a unified view of objects and files stored across locations and offers a set of actionable insights such as backup and restore, cloning for test and development use cases, and reporting. Helios also supports the deployment of applications such as Insight and Data Classification. These go far beyond standard metadata search and support real content and context-based search and discovery, all within the unified Helios management interface. When combined with another native application branded Spotlight, organizations can use Insight to analyze user activity and search for unstructured data. Metadata tagging already happens on backup snapshots for data lifecycle management and combined with Data Classification, should be extended in a future release to cover more use cases.
Cohesity natively supports data management operations, including test/dev clones. It also supports native cloud integration for tiering, archiving, and replication to public cloud storage services such as Google Cloud Storage Nearline, Microsoft Azure, and Amazon S3 as well as Glacier. Organizations can then leverage cloud-based analytics services on those datasets.
The platform includes comprehensive data security and compliance functions such as anti-malware and ransomware, vulnerability assessments, data masking, data expunge, classification and analytics. These are available either as built-in capabilities, through containerized apps, or via API-based integrations. It also integrates with SIEM and SOAR platforms. In addition, Cohesity DataGovern (a compliance-centric module currently in beta stage) will greatly improve compliance and regulatory reporting capabilities.
Cohesity enables organizations to analyze content for a growing number of use cases, taking advantage of the previously mentioned native apps or pre-configured, easy-to-use third-party apps in its marketplace. The marketplace already offers solutions for global search, e-discovery, log analysis, ransomware, vulnerability scanning, threat detection and mitigation, advanced reporting, and compliance.
Finally, AI and ML capabilities in Helios support 2 features: First, ransomware detection and alerts enabled by identifying encryption-based ransomware attacks; and second, enhancing capacity and workload modeling by offering improved impact prediction of workload changes on capacity utilization, both globally or by specific areas such as geo, site, or cluster.
Strengths: Offers a complete end-to-end solution for data protection, consolidation, and management, with a centralized user interface, great overall efficiency, and TCO. The marketplace is showing strong potential, expanding the possibilities of this platform even further.
Challenges: The solution, designed for large and distributed enterprise deployments, has a good ROI, but the initial investment may be steep for small organizations.
CTERA
It proposes a cloud-based SaaS distributed file storage solution incorporating unstructured data management and analytics capabilities. These are delivered through CTERA Insight, a data visualization service that analyzes file assets by type, size, and usage trends, and presents the information through a well-organized, customizable user interface. Users can drill down to understand which tenants and locations see data growth patterns and pinpoint the related groups, individuals, and data types.
Besides data insights, this interface also provides real-time usage, health, and monitoring capabilities, encompassing central components and edge appliances. CTERA also implements a comprehensive role-based access control (RBAC) system that supports folder and user-based tagging to grant dynamic data access, including geographic or department-based access.
The solution allows enterprises to design their global file system in compliance with data sovereignty regulations through CTERA Zones. With Zones, the global file system can be segmented into multiple data units to prevent data leakage between zones. Users are prevented from accessing any share in the global namespace that does not belong to their defined Zone. Shares can be shared between multiple zones. Administrators can define zones based on the content required by each department and associate a department edge filer to each zone, ensuring that users only have access to relevant data while restricting access to sensitive data across the organization. Another product feature is deploying the solution across multiple cloud providers and performing transparent policy-based data movement between clouds for data locality or financial reasons without impacting front-end access to the data.
CTERA provides its own security layer with audit trails, authentication mechanisms (including two-factor authentication), ransomware protection through immutable snapshots, antivirus scanning, and granular versioning. In addition, it offers integrations with Varonis to deliver capabilities in multiple areas, including data classification (regulated, sensitive, and critical data), security analytics, deep data context and audit trails, and security recommendations.
CTERA’s SDK allows API integrations which allow microservices to perform data management related tasks. In 2022, S3 connectors will be added as well.
In 2022, CTERA will add an AI/ML-based anomaly detection engine to Insight, providing anomaly detection capabilities like ransomware alerts and the ability to terminate user accounts tied to a potential ransomware attack.
Strengths: Combines proprietary data insights, advanced compliance, and security features, some of which are delivered by Varonis. The solution has its own security layer, which will be comprehensively improved in 2022. This allows CTERA to deliver comprehensive unstructured data management capabilities and a promising near-term roadmap.
Challenges: big data analytics capabilities are currently lacking and represent an area ripe for improvement.
Datadobi
It proposes a suite of data management products with DobiMigrate and DobiProtect. Both solutions are deployable on-premises and provide infrastructure-grade data management capabilities such as data migration, data protection, archival functions, movement, and deletion. The solution scans data sources, collects metAdata: and aggregates collected information in dashboards, where it can be analyzed further by individuals who can take action.
Currently, company’s solutions can use native metadata provided by storage systems. To manage unstructured data, Datadobi introduced Datadobi Query Language (DQL), a language created to enhance its file system assessment service offering. This language is now available to DobiMigrate and DobiProtect users, who can query data sets and plan subsequent activities. It’s also expected that future releases will provide better data organization capabilities.
The solution offers a simple user interface; however, global content and search capabilities such as data reuse, e-discovery, compliance, and data placement and data sovereignty features are not yet supported. The firm doesn’t intrinsically offer a way to build data lakes. It is, however, capable of migrating data sets (DobiMigrate) or creating copies (with DobiReplicate and DobiSync), despite the primary marketing of these products for data protection use cases. A recent release of DobiMigrate makes it possible to create programmatic migrations and ensures perfect data equality between source and target.
Security-wise, the firm currently offers auditing and monitoring capabilities through chain of custody audit journals. Another feature, branded Software Composition Analysis, can scan application libraries (currently Java Libraries) and identify CVE-referenced vulnerabilities.
Datadobi has recently published its API, providing the foundations for a rich and growing marketplace of third-party applications. It is currently in talks about future integrations with several third-party vendors.
Currently, AI-driven data management capabilities are on the roadmap, like many of the other capabilities covered in the GigaOm Key Criteria for Unstructured Data Management. The company has just issued (March 2022) the first major announcement of several planned in 2Q22, which strengthen its position as an unstructured data management platform provider. Worth mentioning, DobiReplicate integrates with Dell Technologies PowerStore systems and proposes PowerStore-to-PowerStore multiprotocol replication.
Strengths: Offers a simple and affordable solution for data migration and data protection use cases. The company has also launched the first phase of its ambitious roadmap, with a rapid implementation pace for subsequent updates.
Challenges: Despite its compelling roadmap, current capabilities remain limited.
Data Dynamics
It offers a complete unstructured data management solution built around 3 products: StorageX (data location optimization and enterprise data migration), Insight AnalytiX (privacy risk classification), and ControlX (Remediate data exposure risk).
StorageX allows organizations to manage unstructured data at petabyte scale across storage systems and locations, including cloud-based storage, with features such as data discovery, classification, and augmentation. It supports a broad set of data movement options and policy-based management capabilities.
It analyzes data across storage systems and performs automated metadata tagging and augmentation based on various criteria: tags can be added automatically based on criteria such as file type, file content, or file name or folder expressions, but administrators also can define and apply custom policies.
It is complemented by Insight AnalytiX, a privacy risk classification solution that recognizes files containing PII across more than 200 known file types. Its privacy risk classifier currently recognizes 49 different types of PII; the solution combines pattern recognition technology, keywork recognition, and AI. It works in coordination with StorageX, from which it fetches dataset information by building advanced multi-level logical expressions and a combination of logical operators and then proceeds to stream and analyze data to identify PII and potentially risky content. Once analysis is complete, the solution offers templates to view the analyzed data and allows users to download reports in various formats. The report is powered by deep analytics (both descriptive and diagnostic) to help enterprises get a clear understanding of the risk that exists and an easy means of quantifying it. Both StorageX and Insight AnalytiX support RBAC, boast an intuitive user interface and support full text-search functionality.
ControlX integrated with InsightX gives enterprises the ability to mitigate risk proactively and to provide scalable security remediation, with the ability to quarantine at-risk datasets and re-permission files intelligently, as well as creating an immutable audit trail backed by blockchain. ControlX’s file control operations can be integrated into enterprises’ existing environment service management, data management, and governance workflow automation via RESTful APIs.
The solution is policy-based and supports multiple data copy and data movement scenarios. Datasets can be used to create data lakes for big data analytics applications; also, age and last accessed criteria can be used as the basis for data tiering policies, which can automate data placement into cheaper storage tiers.
Strengths: Offers a robust, policy-based unstructured data management platform that embeds outstanding metadata augmentation capabilities, broad storage solution coverage, outstanding data movement/tiering options, and a solid data analytics and privacy risk classification solution. ControlX provides a quarantine option for moving files to a specific location and isolating them. The air gap provided by Quarantine helps prevent ransomware attacks on critical files while providing immediate protection.
Challenges: Insight AnalytiX offers interesting capabilities for PII detection, so the company has an opportunity to extend its feature set further and include actionable insights on the data (including handling of privacy law mandated access and deletion requests).
Dell Technologies
It offers unstructured data management capabilities through its EMC DataIQ storage monitoring and dataset management software. The solution offers a unified file system view of PowerScale, ECS, third-party storage platforms, and cloud storage, with insights into data usage and storage infrastructure health. DataIQ is software-based and can be deployed either on Linux servers or as a VM. For large deployments involving frequent, sizable data transfers, organizations can offload data traffic and optimize transfer flows with additional components (DataIQ Data Mover external workers).
DataIQ’s capabilities for analyzing and classifying large data sets across platforms and locations are optimized for high speed scanning and indexing, with the ability to get search results within seconds, regardless of where the data resides. DataIQ supports metadata tagging of files and datasets. Tagging can be automated or manual, with automated tags applied during regular scan activities based on policies previously configured by administrators. Tags can contain size limits and/or expiration dates for tagged data (with the ability to alert data owners when one of the criteria is met).
Te firm also provides solid reporting capabilities (including the ability to identify redundant, unused, and dark data) and can provide reports on storage usage by project, teams, or individuals, as well as cost-based reports for chargeback/showback purposes. The solution visually presents some of the data through “data bins,” each of which contains a view of datasets classified by their latest modified and accessed attributes, presenting pools of hot, warm, cold, or frozen data. The time ranges for each bin are customizable and provide a clear view of data categories and data placement optimization opportunities. In addition, DataIQ can be used to provide advanced monitoring capabilities to Dell EMC PowerScale scale-out file system storage.
The DataIQ platform is extensible through plug-ins, including data movement capabilities with the data mover plug-in. This allows the transfer of specific files and datasets across locations, storage systems, and through different source/target protocols to feed relevant data to appropriate applications. Other plug-ins allow the identification of duplicate data (only for file-based repositories), auditing of deleted files, and the ability to preview files.
From a security perspective, the solution supports RBAC and Active Directory-based authentication while it implements industry-standard traffic encryption protocols. However, it doesn’t yet have any anomaly detection mechanism to help identify early abnormal user behavior or a potential ransomware attack. CloudIQ usually handles ransomware detection, but it is a separate product and may not always cover the same data and system scope as DataIQ does.
DataIQ offers an API (branded ClarityNow!) that can be accessed directly through Python. In addition, its modular architecture allows the creation of third-party plug-ins, which can tap into the API and offers a comprehensive developer guide for front-end and back-end plug-in development, and sample code on Dell’ Github repository.
Strengths: DataIQ seamlessly integrates with the Dell storage portfolio, complementing CloudIQ and allowing the monitoring of data across Dell EMC and third-party products as well as cloud-based storage. The solution offers solid reporting capabilities and an excellent open architecture that allows third-party plug-ins.
Challenges: The solution currently lacks anomaly and ransomware detection capabilities. It also doesn’t include any regulatory or compliance features that could facilitate data classification and/or actionable insights related to data privacy laws, e-discovery, or data sovereignty.
Druva
Its Data Resiliency Cloud provides centralized protection and management across end-user data sources and is offered as SaaS. By unifying distributed data across endpoints, data center workloads, AWS workloads, and SaaS applications, organizations have a single place to manage backup and recovery, DR, archiving, cyber resilience, legal hold, and compliance monitoring. This unification minimizes data risks and ensures continuity for employee productivity.
Druva provides advanced metadata analytics based on unstructured data by analyzing data pipelines consisting of hundreds of millions of events per hour and more than 400,000 queries per hour. Data is collected from backup events and then run through big data analytics pipelines to make it queryable. Currently, the company provides dashboards giving users summary level information and federated search capabilities (including e-discovery and legal hold queries) but also provides storage insights and recommendations.
The solution offers an easy-to-use and feature-rich management console that provides useful metrics and statistics. Druva implements federated search, a powerful search engine that enables administrative, security, legal, and forensic teams with enhanced capabilities to conduct global metadata searches across workloads, including Microsoft 365, Salesforce, Google Workspace, and endpoint devices. Various attributes can be used to search, including for email-related information.
The firm doesn’t offer big data analytics capabilities currently (in the sense of allowing data copy actions to create data lakes); however, it uses big data analytics internally with ETL pipelines to build datasets for its AI/ML solutions and for monitoring its own cloud services.
Druva’s SaaS platform offers a broad set of compliance and security features. As previously mentioned, the solution supports compliance queries related to e-discovery and legal hold. In addition, it monitors unusual data activity to detect potential ransomware attacks, and implements an accelerated ransomware recovery feature, which performs quarantine and orchestrated recovery and allows the recovery of curated snapshots. Security-related features include RBAC, strong user authentication, multi-factor authentication, and multiple security certifications. It can provide access insights on data usage, inform of potential anomalies, and integrate with a rich ecosystem of security, monitoring, and logging solutions.
While Druva has no marketplace of its own, the solution provides a full REST API, enabling integration with industry-acclaimed third party solutions in multiple areas such as authentication and ITSM (Okta, Splunk, ServiceNow, ADFS, GitHub), e-discovery (Disco, Access Data, OpenText, Exterro), and security (PaloAlto Networks, FireEye, Splunk).
The vendor considers AI and ML to be essential capabilities for improving their solutions and differentiating them vs. competitors. AI/ML are currently used to enhance customer experience with unusual behavior detection and IOC scans, provide content-based recommendations such as file-level storage insight and advanced privacy services, and to enhance the underlying metadata. The product capabilities enhanced by AI/ML include ransomware anomaly detection, storage consumption forecasting, and data privacy and compliance features.
Strengths: Data governance and management tools are integrated in a modern SaaS-based data protection solution. It’s easy to deploy and manage at scale, with a simple licensing model, good TCO, and quick ROI. Druva is also accelerating its data privacy and compliance capabilities, with more improvements expected soon.
Challenges: While the company sees consistent improvements to its platform, the dependency on SaaS data protection may be an adoption barrier for organizations looking for a standalone UDM solution.
Hitachi Vantara
It has a comprehensive data management strategy for IoT, big data, and unstructured data. When it comes to unstructured data management, it offers a broad solution portfolio, including Hitachi Ops Center Protector) aimed at data protection and copy management, Hitachi Content Platform (HCP) object store, and Hitachi Content Intelligence (HCI).
The latter offers the necessary features to optimize and augment data and metAdata: making it more accessible for further processing through tools like Pentaho (data analytics suite) and Lumada Data Catalog. One of the key features of HCI is the ability to define policies and actions based on standard and custom object metadata: policies can be related to a variety of actions such as data placement (protection, replication, cost-based tiering, and delivery to processing location), data transformation (anonymization, format conversion, data processing), security, and data classification.
HCI supports the creation of simple or complex end-to-end workflows that work on-premises or in the cloud. A new object or file can be augmented automatically with application-supplied metAdata: scanned for a variety of criteria (for example identifying PII), and subsequently augmented with classification and compliance-related metadata. It also offers multiple capabilities related to compliance and governance. Besides detecting PII, HCI can be used for retention management and legal hold purposes; it supports geo-fencing, GDPR, HIPAA, and other regulatory frameworks. These are supported by data disposal workflows, including a built-in system to process RTBF requests, the ability to automatically delete data after retention periods have elapsed, and custom audit logging of disposition activities.
Strengths: This solution framework can be optimized for several use cases, including indexing and search, data governance and compliance, auditing, e-discovery, ransomware, and detection of other security threats. Hitachi Ops Center Protector can be utilized with a variety of sources, including non Hitachi storage systems, while HCP and Pentaho are designed for high scalability and can be deployed in hybrid cloud environments.
Challenges: Hitachi’s ecosystem is designed for large organizations and can be expensive and complicated for smaller ones. The solution has a heavy focus on data processing workflows, making it less appealing for organizations seeking simple data management and data migration capabilities.
Komprise
It has a compelling data management platform that boasts easy deployment and management to enable rapid ROI. Initially aimed at some of the biggest pain points in large-scale file storage infrastructures, the solution has evolved and is capable of providing data analytics, search, and tagging, as well as building virtual data lakes. Very easy to deploy and manage, Komprise is a SaaS-based solution compatible with any NFS and SMB network share, on-premises or in the public cloud, as well as in S3-compatible object stores. Recently, the firm announced support for several AWS services, including Amazon FSx for NetApp ONTAP, Amazon S3 Glacier Instant Retrieval, and large transfers through AWS Snowball.
Komprise Deep Analytics provides Metadata analytics capabilities, an ElasticSearch-powered feature capable of indexing metadata and tags across heterogeneous storage systems, whether on-premises or in the cloud, including S3 buckets. The firm creates a global file index automatically when you point it at different data repositories, and Deep Analytics provides the ability to query across all the different data repositories. Deep Analytics allows the creation of queries to identify specific data sets and create reports and dashboards that let users drill down into data. In addition, it provides actionable insights, such as the ability to initiate data movements from queries executed with its Deep Analytics Actions feature. In addition, it offers data retention capabilities and can identify dark or orphaned data.
The solution is policy-driven; it takes advantage of both Deep Analytics and Komprise’s transparent move technology (TMT) to move data seamlessly based on customer-defined policies and datasets from deep analytics queries. From a user perspective, TMT means no change to the way data is accessed after it is tiered or migrated, which means no disruption. Komprise allows users to identify datasets across multiple storage systems, thanks to its global indexing capabilities. This feature is very relevant for big data use cases and allows organizations to copy or move assets related to these analytics queries into a data lake through TMT.
Regarding compliance and security, the firm leverages its global index to find and then securely share data relevant for compliance, legal hold, legal discovery, and retention purposes. The solution is capable of identifying anomalous activities through Deep Analytics, while it can help provide additional protection vs. ransomware attacks for unstructured data by tiering cold data into immutable object storage buckets in the cloud. Finally, it’s capable of maintaining secure access by preserving access control and security posture across platforms.
While the solution has no marketplace of its own, Komprise offers an API for organizations that plan to automate activities or interface Komprise with their existing systems. For example, it can be connected with cloud-based natural language processing systems to create policies that perform in-depth data analysis based on specific criteria or text patterns. It also offers several python scripts to accelerate integrations.
Strengths: Can be deployed in minutes and starts producing the first reports and providing insights on how to optimize data placement in a few hours. Deep Analytics offers outstanding data classification capabilities with integrated actionable insights.
Challenges: Currently lacks easy-to-use, pre-packaged connectors to integrate its solution easily with popular applications.
NetApp
It offers Cloud Data Sense, a comprehensive, predominantly business-oriented unstructured data management solution that covers infrastructure-based needs. It performs several types of analysis on storage systems (NetApp and non-NetApp) and their content (including files, objects, and databases), providing insightful dashboards, reports, and guidance for several roles in the organization.
Based on ElasticSearch, it centrally manages all storage repositories and can scale to hundreds of petabytes. The solution is implemented on the 3 major cloud hyperscalers and is also available for on-premise customers as a local setup due to significant demand from our install base. Data can reside on a single server or a cluster of servers, either in the cloud (customer-operated servers) or on-premises, putting organizations fully in control of their data.
Metadata analytics features include full data mapping, data insights and control over redundant and stale data, the ability to perform advanced data investigation through comprehensive search options, and the possibility of mapping PII across storage systems. Similarly, the solution can be used to search for sensitive data through specific patterns (for example, SSNs). Organizations can generate legal-ready compliance reports in minutes, with automatically classified data, and can generate reports for privacy risk assessments as well as reports meeting the requirements of HIPAA, DSS, and DSARs.
The solution supports DSARs (usually related but not limited to GDPR and CCPA regulations) to locate human data profiles and related PII. Those capabilities are accessible through a comprehensive, yet intuitive, user interface that’s integrated with NetApp Cloud Manager.
Big data analytics are supported by the solutions’ data source consolidation capabilities. Users can create queries to find specific data sets across storage systems, then copy those files to a designated target location, effectively creating a new data subset.
Cloud Data Sense also addresses compliance and security by providing data encryption with Cloud Volumes ONTAP. The solution provides ransomware protection and supports GDPR, CCPA, and other privacy regulations. In addition, alerts can be created that inform administrators automatically whenever sensitive data is created (for example, when files contain credit card information) or to identify dark data sources (such as large email address lists), helping to achieve better compliance within organizations.
From a marketplace standpoint, Cloud Data Sense is tightly integrated with the NetApp portfolio and supports a broad range of firm’s solutions and services, whether on-premises or in the cloud, such as Cloud Volumes Platform, Cloud Volumes ONTAP, Cloud Insight, Cloud Backup and Cloud Tiering. Also supported are Azure NetApp Files, CVS for Google Cloud, and Amazon FSx for ONTAP.
Cloud Data Sense leverages AI and ML for automated data classification, data categorization, and contextual, deep data analysis.
Strengths: Cloud Data Sense provides a formidable set of business-oriented capabilities and comprehensive data source support. The ability to serve DSARs, identify PII, and support compliance regulations are significant advantages of the solution.
Challenges: The solution will be less appealing to organizations seeking a purely infrastructure-oriented unstructured data management solution.
Panzura
Its Data Services is a SaaS-based analytics suite compatible with its CloudFS and any NFS or SMB compatible file repository (including NetApp and Dell PowerScale/Isilon), both on-premises and in the cloud. It offers a complete view of storage infrastructures, including resource utilization, file auditing, and global search, while enabling enterprises to analyze trends and get complete reports about the file systems and data stored in them.
The solution takes a snapshot of all data every 60s and incorporates it into a metadata catalog that provides comprehensive information about files, owners, access frequency, and data growth. Data Services provides a simple and easy-to-use management interface that includes free-text search and a broad set of filters; searches can be saved for future use. Search includes file recovery capabilities, soft user quotas, and data analytics.
Data analytics presents information about hot, warm, and cold data; filters it by age, size, storage distribution, file type, and file size; and provides insights about how data is distributed. In addition, it shows how data grows daily, helping organizations to understand growth patterns and identify potential spikes. The solution includes monitoring capabilities and can report latency issues or spikes in CPU usage. Currently, metadata tagging and augmentation are unavailable but the capability should be implemented in 2022.
Data Services provides comprehensive auditable information for data stored on CloudFS about several user activities such as data copy, file and folder creation, file system operations (lock, write, move, read, deletion, rename), and changes in attributes and permissions. This information is accessible through the same search mechanisms highlighted previously, using filters to refine by audit action and date range, or user, and the solution can return millions of results in under a second. Auditing capabilities can be used to identify violations of regulatory compliance mandates such as data sovereignty legislation, for example, if files are copied or moved to or from geo-restricted storage systems by end users. Search capabilities can also be used to rapidly identify and retrieve data impacted by legal hold notices.
Besides comprehensive auditing capabilities, the solution implements various anomaly detection mechanisms used for ransomware detection and protection. When a suspicious activity that follows ransomware patterns is detected, Data Services can identify, alert, and shut down access to data repositories to prevent further damage.
Taken together, the features contribute to improving overall storage infrastructure TCO.
Strengths: The solution is straightforward and effective; it can be deployed in minutes and strips hours from time-consuming IT tasks such as legal holds. Even more so, support for ElasticSearch and Kibana increases the number of use cases and possibilities the platform offers.
Challenges: An area of improvement for Panzura is developing additional capabilities to serve big data analytics use cases better.
Spectra Logic
Its StorCycle is a simple and very effective solution for storage lifecycle management, optimized to move or copy data from primary storage systems to a cost-effective tier that can include disk, tape, and cloud. Deployed as a virtual or physical appliance, the solution is simple to deploy and easy to manage. The user interface provides browser-based configuration, management, and monitoring of the StorCycle solution.
The later scans storage locations for files and their attributes, like file size and age. StorCycle allows automated migration activities that are based on file age and size criteria. Once these are configured, StorCycle will automatically migrate matching files to colder storage tiers such as Spectra Logic BlackPearl NAS and object storage disk, network-attached storage from third-party vendors, or public cloud, including AWS S3. Project-based archiving capabilities are also available. In this case, administrators can tag datasets with custom metadata on a per-job basis and do metadata searches to easily identify and retrieve projects, directories, or files.
When moving data to cold storage, the solution can replace original files with a symbolic link to the archived data, effectively enabling transparent storage migrations, although longer access times must be taken into account. Files can also be repla, with .HTML links, which provide access to StorCycle’s restore wizard or the ability to request a restore from an Administrator (for users who do not have StorCycle credentials).
StorCycle implements RBAC, Active Directory, and LDAP integration and supports multiple at-rest encryption options based on the target storage tier capabilities. To further enhance security and ransomware resiliency, it protects data through end-to-end checksums, encrypting on all storage targets, and the ability to store multiple copis on multiple storage mediums.
Strengths: StorCycle provides an easy and affordable means to migrate inactive data and completed projects to lower-cost storage. The data is securely preserved for long-term retention, compliance, and ransomware resiliency. StorCycle reduces the cost of storing and managing data and offers a quick ROI.
Challenges: The lack of advanced features around data discovery, metadata augmentation, privacy law compliance, and identification of PII is a limiting factor for organizations seeking comprehensive unstructured data management.
StrongLink
It offers StrongLink AI, an autonomous data management solution designed to provide automation and control in multi-vendor, multi-platform storage environments. The solution presents a single namespace that abstracts underlying storage on-premises or in the cloud, whether block, file, or object based, and scans those systems for data and metadata. Users and applications access data subsequently through StrongLink AI’s single namespace.
StrongLink AI can automate file migrations among storage types in the backend, without any disruption to users or apps, thanks to a combination of user-defined policies and automated data classification capabilities, ensuring data is always placed in the right location. It can be deployed in or out of the data path, with the former offering direct I/O to high IO/s storage and the latter offering strengthened access security, virtualization, and control. Both deployment modes can be combined in a hybrid approach.
The solution implements global file and metadata search. It takes advantage of file system metadata and application metadata contained in file headers and supports user-created custom metadata. Queries on metadata can be used to create metadata-driven data policies (for movement or data tiering to cheaper storage on-premises or in the cloud), and actionable insights are also possible after a query has been executed. StrongLink AI also supports data visualization and report creation. Finally, metadata can be used to tag specific datasets for compliance or retention purposes.
Besides a web-based user interface, StrongLink AI offers an open RESTful API, a command-line interface, and shell access for administrators. It supports RBAC and directory integration with LDAP, Active Directory, and SAML, plus the ability to monitor user activity through audit trails.
Although the solution has no marketplace of its own, third parties can leverage the StrongLink AI API to integrate with their products. Currently, the solution doesn’t implement any AI/ML-based capabilities.
Strengths: Proposes a solid architecture that provides unified storage, multiprotocol data access capabilities, and unstructured data management with a strong focus on metadata management and data copying and movement.
Challenges: The solution doesn’t implement any AI/ML capabilities currently. Security features are also an area for improvement, by adding ransomware protection capabilities, for example.
6. Analyst’s Take
With the increasing size of storage systems dedicated to unstructured data, a growing number of enterprises are looking at management solutions to minimize costs and increase control over critical security and compliance functions.
Cohesity and Komprise are leading in the infrastructure segment, with NetApp getting closer.
Cohesity already had an enviable position and managed to close the gap with additional features around governance and compliance.
Komprise has continued to innovate fast, adding outstanding data analytics capabilities, but it may need to add data privacy and compliance options to establish itself further as a holistic platform.
While behind from an infrastructure feature standpoint, NetApp has remarkable classification and data discovery capabilities using AI and ML to detect different patterns and categories. The company is also innovating at a very rapid pace.
In the group of Challengers, several interesting solutions could soon push into the Leaders group. Most of these already have strong capabilities but are missing functionality related to the key criteria we evaluated in the Key Criteria for Unstructured Data Management report. Also among the Challengers are 2 niche players with laser-focused and cost-effective solutions that can deliver quick ROI: StrongLink and Spectra Logic.
One of the trends we see in unstructured data management is that some of these evaluated solutions come from data protection vendors. These are interesting developments because data protection is often the “final target” where all of an organization’s data is collected, opening the door to many data analysis and classification opportunities. It also makes this data relevant from a privacy and regulatory perspective, notably for legal retention requests.
Another interesting observation can be made with respect to distributed cloud file storage solutions. While these do not have the breadth of scope of a data protection solution in terms of the universality of data collected, they still manage a significant data share and offer the immediacy provided by live production data. Data growth trends and operations can be analyzed in real time, and the same can be done to identify anomalies and potential ransomware attacks.
Anomaly detection algorithms mostly rely on AI/ML, but AI and ML can also perform different activities such as deep content analysis, providing improved context for data classification, and even helping to identify sensitive data sets and/or personally identifiable information.



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter


