






Analysis of Mass Data Volume Archiving
Lessons from CNES, DKRZ, LANL, NERSC, NOAA, Sandia National Laboratory, Lawrence Livermore National Laboratory, etc.
By Philippe Nicolas | November 17, 2020 at 2:28 pmData archiving is not new even the term and notion of archive have evolved over the last few decades. In parallel, we saw a deluge of data, especially unstructured ones, with some technology breakthroughs that can be leveraged in such big projects.
We had the opportunity to access several data archiving projects requirements for large, very large projects, and we thought it’s worth a summary associated with market perspectives.
First, a few definitions to stay on the same page especially for primary and secondary storage with two ideas in mind.
Primary storage is where data are created supporting the activity of the organization. Having troubles at this level significantly impacts the on-going activity. It is pretty common to protect data with multi copy techniques but also with backup and archive, at least we hope. The applications and services are made highly available or even fault tolerant with other considerations but again the couple data+applications must be preserved to make the activity continuous.
Secondary storage receives data copies with different techniques and this level doesn’t support the activity but supports the primary storage environment. It plays its role when there is an issue on the primary level. Historically there were multi levels of storage but we can assume mainly 2 levels: the production level with primary storage and the protection level with secondary storage even if coexist different natures of storage at this level. In the past there was also a hierarchy across secondary storage entities but it makes things complex. We continue to see this at different places and it requires real sophisticated requirements and even constraints between levels. Also this definition doesn’t imply any access protocols from the storage.
Depending on the industry and activity of the organization, users can consider block, file or object storage as primary storage, this is driven by the use cases and applications and services requirements.The industry literature often covers these 2 storage flavors with their data attributes i.e hot and cold data. This different behavior explains why secondary storage grows faster than primary as data are accumulated with potentially long retention.
Now for archive, it’s the process to move (copy and delete) and store data on a secondary storage layer. Move is important as the data is no longer present at the source, thus archived data are the last copies of data and require strong protection, preservation, integrity and redundancy methods. The other dimension of store action implicitly associates long term retention attributes as archiving is considered for multi years preservation even decades.
For these technical environments, we found technical or scientific archiving that doesn’t require, at least for these kinds of data and usages, some compliance approaches. Other departments may require some legal archiving relying on WORM and solutions certified by third-party authorities aligned to some specific regulations.
As illustrated by the IO500 rankings, the vast majority of file systems are parallel with Lustre, BeeGFS, IBM Spectrum Scale and WekaIO and some of them are open source. A bit of Intel DAOS appears and also 2 fast NAS products started to be deployed as well represented by Qumulo and Vast Data.
The environments covered here are data intensive and represent several 100s of petabytes. Therefore solutions are not so obvious with huge challenges and these projects require proven deployments with real outcomes.
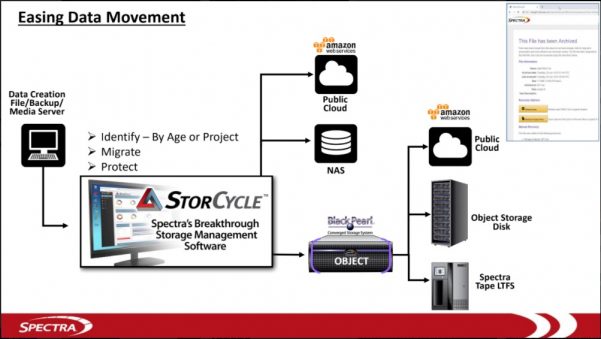
Historically, users adopted asynchronous methods for archiving with a non continuous data access, having to use separate mechanisms. Then people started to invent Hierarchical Storage Management aka HSM to arrange storage entities based on data criteria. Some vendors introduced this and named it a nearline approach, we all remember that period. Most of the time it was the age or size of files that made files candidate for such archiving processes. The beauty of this was the full visibility of namespace with all files, physically present on file systems or migrated to secondary storage levels. When an access of a migrated file is initiated, a cache/copy back action is launched to let the call process access the data from the primary storage. The key element to remember here is that secondary storage controlled via HSM logic are not seen and considered by applications. Therefore, data must be copied back to primary level to be accessed generating extra traffic and access latency. It was one of the first tries to build an active archive environment but users need more.
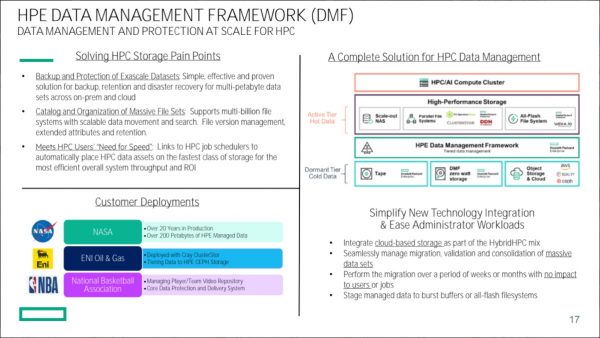
This notion was then addressed by capacity NAS dedicated for secondary usages, sometimes used for backup but also for archives. Active in that case means that data are accessible in a reasonable time to satisfy applications and users. At the same time, these entities are file servers meaning that their access is open and rely on industry standard file sharing protocols such NFS and SMB.
This is also illustrated by LTFS, the file system built on tapes, to mimic a disk file system and finally be integrated transparently into a global file storage environment. These aspects invite us to mention the data mobility requirement and the choice of LTO and LTFS is largely adopted even if we continue to see some proprietary approaches. There were some integration of LTFS and NAS with some offering to facilitate integration in existing environments. This alternative logic with secondary NAS makes things different with some redirection mechanisms to route access requests to the new data location. And here there are many implementations with of course stubs or symbolic links to name two classic examples. And finally universal access is also a need with http protocol providing remote access capabilities.
Some directions towards object storage, with simple http or more sophisticated approaches such as S3, are largely adopted and seen deployed in these large environments as these storage entities were designed for large capacity.
As mentioned above open source plays a significant role in large environments as often these entities prefer to invest in hardware systems and computing power than data management software.
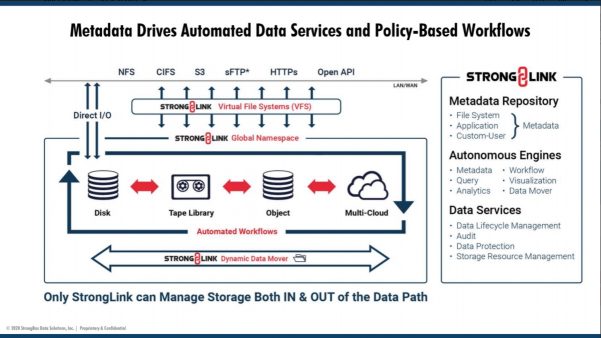
In term of needs, we can summarize them with the following non exhaustive list:
- coexistence with backup software,
- acceptation of trillions of files,
- support of small files,
- exabyte-scale solution with multi-server model,
- scalable file pointers techniques (modern stubs, symlinks, etc.),
- intelligent file system scanning and selection,
- migrated file versioning,
- 10s-100s GB/s read/write throughput,
- SLA and QoS,
- load balancing,
- Posix, NAS, http/S3 and LTFS integration or a subset of these,
- same content access via different protocols (ex. NFS and S3),
- seamless integration and application access,
- global namespaces even across sites (notion of archive datalake),
- energy efficient with power management,
- protection of data with wide erasure coding or RAIT,
- data reduction to eliminate unwanted file duplication,
- data integrity control,
- data portability and mobility with open format,
- integrate technology refresh as data last longer than storage device,
- new VTL model with S3 gateway to tape and cloud,
- project archiving with file grouping,
- indexing at ingestion with potentially content indexing,
- federated open search with Apache Lucene, Solr and Elasticsearch,
- integration of different disk flavors (SMR for instance),
- user, applications, sites… quotas,
- internal database protection (snapshot, incremental, etc.),
- centralized console with policies, workflows, user roles, etc.
- analytics and file statistics,
- monitoring, auditing, accounting, security, etc., and
- finally the cost…
We invite users to align their needs with the following products all having some interesting characteristics depending on the environment: Atempo, Data Dynamics, Grau Data, HPE DMF, HPSS, IBM, iRODS, iTernity, Komprise, Point Software and Systems, QStar, Quantum, Starfish, StrongBox Data Solutions and Versity.
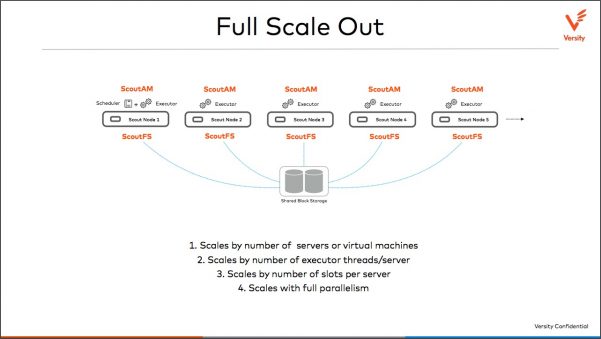
These high data storage needs may also consider some future developments around glass or DNA storage. Some recent tests and progress were demonstrated with some key investment by big IT players such as Microsoft with project Silica or DNA with Twist Bioscience or Catalog. These approaches solve the energy and space challenges.



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

