






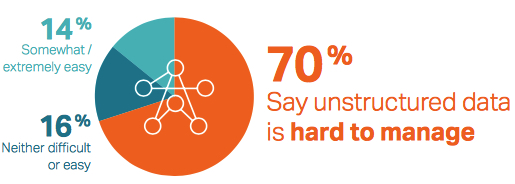
70% of Respondents Said Managing Unstructured Data Somewhat to Extremely Difficult
To move files between cloud platforms, between on-prem tiers and between on-prem and cloud, hard to gain visibility into billions of files.
This is a Press Release edited by StorageNewsletter.com on February 20, 2020 at 2:24 pmThis survey is authored by Igneous, Inc.
Rise of the Data
Economy 2020 Igneous Survey
According to the Economist, data has surpassed oil as the world’s most valuable economy. And, just as oil did in the last century, data is poised to change our world. We are seeing the rise of the “Data Economy”2.
It’s important to understand just how different this emerging data is.
First, it is almost always machine-created. People simply cannot create that much data that quickly. Research instruments, design simulation, sensors and imaging and other kinds of machines can generate the petabytes and exabytes now routinely being amassed by Data Economy enterprises.
Second, this is unstructured data. This is not the nice, ordered, well- mannered data that sits in massive databases. This is messy data that sits in billions of files, mostly in on-premises NAS systems. Unlike structured data, the unstructured data of the Data Economy is unruly and extremely difficult to manage.
Igneous set a goal to better understand the effects this explosion of unstructured data will have on enterprises. To find out, Igneous fielded the Rise of the Data Economy survey at the AWS re:Invent show in Las Vegas, NV, in December of 2019.
Data Economy Scale
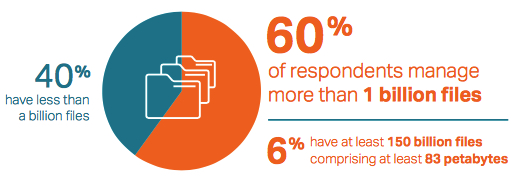
The first thing to understand about the Data Economy is the massive scale of data enterprises have amassed. 60% of respondents report managing more than one billion files. The top 10% of that group manages at least 150 billion files comprising at least 83PB of data.
To understand why enterprises now manage so many files, it is helpful to explore an example from the healthcare industry. Until recently, cancer was fought with surgery, chemo and radiation, but that is changing with the advent of personalized medicine. Using DNA sequencing, doctors can now tailor treatment plans to a patient’s specific genetics.
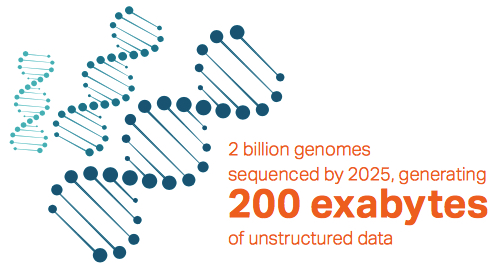
The challenge is that genetic sequencing creates massive amounts of data. A single machine can generate up to 2TBof data per run. With researchers predicting the industry will sequence as many as 2 billion genomes by 2025, the total storage requirements will soon top 200EB of data.
That’s just one example. There are further examples in virtually every industry. Autonomous vehicles are sending telemetry back to the manufacturer for every vehicle they sell and every mile the vehicle travels, GIS mapping of our world uses LiDAR and hyperspectral imaging and the list goes on and on.
The result in all cases is the same. Organizations find themselves having to manage billions of files comprising petabytes of data. And, over time, this will grow to hundreds of billions of files and exabytes of data.
How are things faring so far?
The Struggle With Unstructured Data
Most respondents (70%) told us managing their unstructured data is somewhat to extremely difficult.
Why? First, it is difficult to move files-between cloud platforms, between on-prem tiers and between on-prem and the cloud.
Second, it is hard to gain visibility into the billions of files. Unstructured data Is valuable; organizations say a third of the data they manage has little to no value. An obvious question is why they don’t delete (or at least archive to cold storage) this data?
The answer is a combination of the difficulty enterprises have moving unstructured data combined with a fundamental lack of visibility. If you cannot move data it is difficult to backup or archive data. And, organizations cannot identify, nor even find this value-less data in the first place.
Finally, as a corollary to their inability to move unstructured data, respondents report trouble archiving and backing-up unstructured data. In fact, half of our respondents aren’t even trying to backup or archive data to the cloud. It takes too long, has security implications, is too expensive and overall just too ineffcient to accomplish.
Bringing Your Unstructured Data Under Control
For the most part, organizations are stuck in the mud when it comes to managing their unstructured data.
As the survey illustrates, they have poor visibility into their data and have immense trouble moving the data between on-premises tiers and up and down from the cloud. As a result, organizations are missing enterprise SLAs, leaving crucial data unprotected and are unable to take advantage of cloud to reduce their data center footprint.
In short, until they fix the fundamental issues of visibility and data movement, organizations have no hope of regaining control. To solve these issues there are two basic (albeit extremely complex) things organizations need to accomplish:
Visibility
IT needs timely, accurate information in order to make the decisions necessary for managing unstructured data. With such visibility IT can decide which files they can delete, which need to move to secondary tiers, and which belong in cold storage.
The problem is that traditional tools fall down at scale, taking weeks or months to provide information about your entire data store. By that time the information is no longer accurate. Organizations need to implement solutions that can provide visibility within the following parameters:
- Scale. Many traditional solutions fall down long before reaching a billion files. You need a solution that can scan billions of files in hours or days vs. weeks or months.
- Scope. Most organizations have a mix of storage systems … on-prem, cloud, different file systems, NAS – everywhere. Your solution must provide full visibility to ALL of your data, regardless of where it resides.
- As-a-Service. You have enough things to manage – you don’t want to add managing your data visibility solution to that list. Insist on an as-a-Service solution.
Data Movement
Once you have solved the visibility problem, you’re ready to act. But acting on data nearly always means moving your data. Once again, most traditional solutions fall down well short of billions of files and petabytes of data.
To be able to move your unstructured data quickly, efficiently (and cost-effectively) there are several things you need to solve for:
- Scale. Once again, you’ll need a solution that can work at the billions of files, petabytes of data level. It will need to transfer data very close to the theoretical limits of your network bandwidth – something never achieved by traditional solutions. And, it needs to scale-out horizontally in an efficient manner to handle peak transfer loads.
- Latency-aware. Scale is important, but not at the cost of bringing your network to its knees. You’ll need a solution that monitors overall network latency in real-time and backs off when data movement is affect user experience.
- Cloud-savvy. Storing data in the cloud is extremely cost effecting today, but moving data to and from the cloud is tricky. Done incorrectly the cost of moving data to and from the cloud can easily dwarf the cost of storing the data in the cloud. Make sure you select a solution that is cloud-savvy and minimizes data move charges in the cloud.



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

