






Cloud Tiering and Object Storage for Backup
Balancing cost and speed
This is a Press Release edited by StorageNewsletter.com on February 7, 2020 at 2:31 pm This article was written by Mike Wilson, director of technology, Quest Software, Inc.‘s data protection business unit.
This article was written by Mike Wilson, director of technology, Quest Software, Inc.‘s data protection business unit.
Cloud Tiering and Object Storage for Backup
Balancing Cost and Speed
How to get the best of both worlds: The low pricing of cloud storage with short data retrieval times.
Be sure you have the right architecture in place first.
There are 2 kinds of organizations: those that use the cloud for backup, and those that are going to use the cloud for backup.
And why not enjoy the advantages of the cloud for backup restore, DR and long-term retention? The cloud has become ubiquitous and its accessibility and cost structure are flexible. Cloud tiering has become popular as companies turn to object storage for the growing amount of data that may never change or may be accessed only infrequently.
But organizations don’t reap those advantages simply by pushing their data into Amazon S3 or Azure block blobs. They get the most out of cloud storage when they consider and implement architectural changes to fully support its advantages. Careful consideration around technology and deployment will keep them from making costly mistakes, like sending duplicate data to the cloud and storing low-priority data in expensive tiers.
This paper focuses on data protection through storing data in different tiers in the cloud, or cloud tiering. It examines the costs, benefits and risks associated with the cloud tiering of backup data. With the right architecture in place, organizations can rely on cloud tiering to lower the cost of data protection and make life easier for backup administrators.
Object storage, cloud tier, Capex and Opex
With the growth of data and new kinds of data to protect, object storage of backup data has become increasingly appealing to businesses. Object storage is for backup data because it can scale infinitely, is cost-effective, works almost anywhere and is not tied to a specific size or format.
Cloud tiering takes advantage of object storage in the cloud. Amazon S3 and Azure block blobs are examples of cloud storage destinations that cloud tiering solutions are designed for, providing huge scale and supporting large amounts of unstructured data.
Figure 1: Typical hierarchy for cloud tier storage
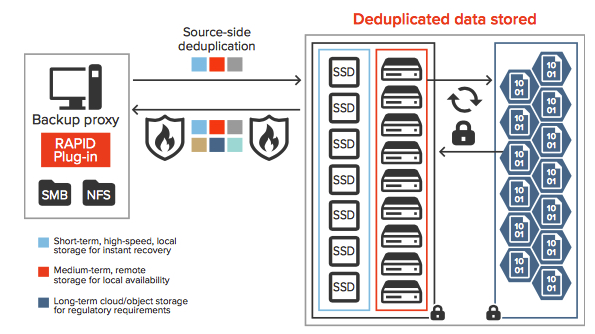
Because cloud providers offer storage at low costs, smart organizations have turned to the cloud as part of their storage strategy.
Figure 1 depicts an example of an enterprise backup storage hierarchy.
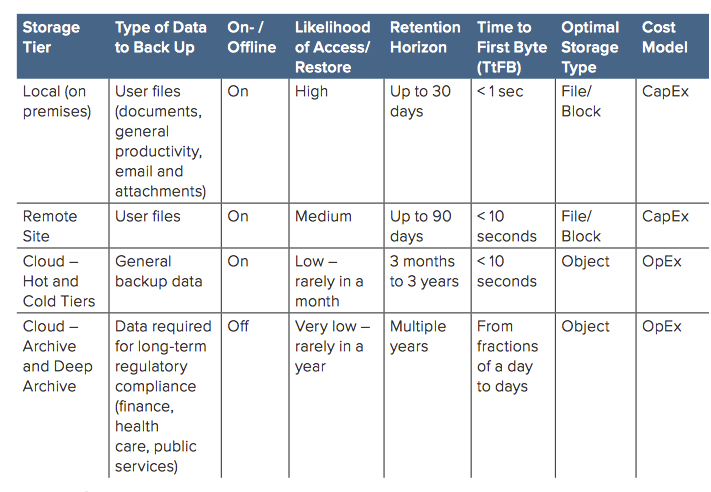
Table 1 contains details of different tiers in the storage hierarchy. A compelling feature of using cloud tier storage for backup (last two rows of Table 1) is its cost model.
Even on tape, the infrastructure for storing the data on premises or in a remote office involves capital expenditure (CapEx) and long-term purchase and ownership. Besides hardware, software and facilities, the maintenance cycle includes refreshing the data every few years. That entails reading back all the data, replacing the media, rewriting the data onto new media, replacing drives and paying people to perform the work.
Table 1
Storing and maintaining data in the cloud, on the other hand, involves a monthly operational expenditure (OpEx), which is easier to control. A company facing $100,000 of CapEx to build out its data center for long-term backup storage could easily prefer spending $1,000 per month in OpEx for similar capacity without owning infrastructure.
OpEx and cloud pricing allow organizations to increase and decrease their spending as their storage needs grow and shrink.
Cost advantages of cloud tiers
So, why not store all backup data in the cloud, if the cost model favors it so heavily?
First, there are the transaction costs. Although it costs less per gigabyte to store data in the cloud, it costs more per gigabyte to request (read, write, list, copy, etc.) data. Thus, it makes little sense to store the most recent backup as an object in the cloud, because it is likely that somebody will want to retrieve the data in it. The cost of touching the object again will offset any savings.
Then, there is retrieval time.
An important factor when using cloud storage for backup data is the expectation for the RTO. As shown in Table 1, retrieval times can vary depending on the tier. The “Cloud – Archive and Deep Archive” storage tier in the last row of the table refers to data that is, in effect, stored offine, with considerable delay – Time to First Byte, or TtFB – to make the data accessible again. While fees vary depending on the tier, data may remain offine for hours or even days after the initial request for retrieval. That can conflict with expectations for RTO.
Another important factor that organizations often overlook is the increase in network costs they will incur when moving backup data to and from the cloud. To maintain a WAN link to the cloud and use it frequently for cloud tiering generally requires additional bandwidth. Those increased costs are not covered in cloud providers’ data transfer charges.
The goal is to get the best of both worlds: the low overhead and pricing of the OpEx cost model with the short TtFB of the CapEx model.
The right type of cloud storage account will address both of those.
Hot and cold storage? Or Archive and Deep Archive?
How can administrators balance low storage cost and short TtFB? Consider this typical scheme for storage, mapped vs. the tiers in Table 1:
1. First, an organization stores its most recent 30 days of backup data on premises, because the hottest, most urgent and most likely data restores will occur in that timeframe. It needs to be able to restore recent data very quickly to avoid any business impact.
2. Next, data to be retained for 90 days is copied to remote site storage. Data is still close at hand, but overall restore is slightly slower than from the on-premises tier. That also supports the best practice of having an o site, secondary copy of backup data for DR.
3. Then, the organization needs to retain data for a few years in case of audit. The probability that it will need to retrieve the data is lower, and it can tolerate a slower restore. Thus, it stores the data in the cloud as hot and cold objects.
4. Finally, it stores data required for the long term, usually to comply with government or regulatory bodies, in archive and deep archive. The need to restore is far less frequent and far less urgent, so the data is stored in the cheapest, slowest location possible.
How much does cloud tiering cost?
Table 2 summarizes representative costs of different cloud tiers and storage services. Note that the Archive (Azure) and Deep Archive (Amazon) cloud tiers cost less per gigabyte of storage but more per transaction, with longer TtFB.
Table 2: Typical costs for cloud tiering
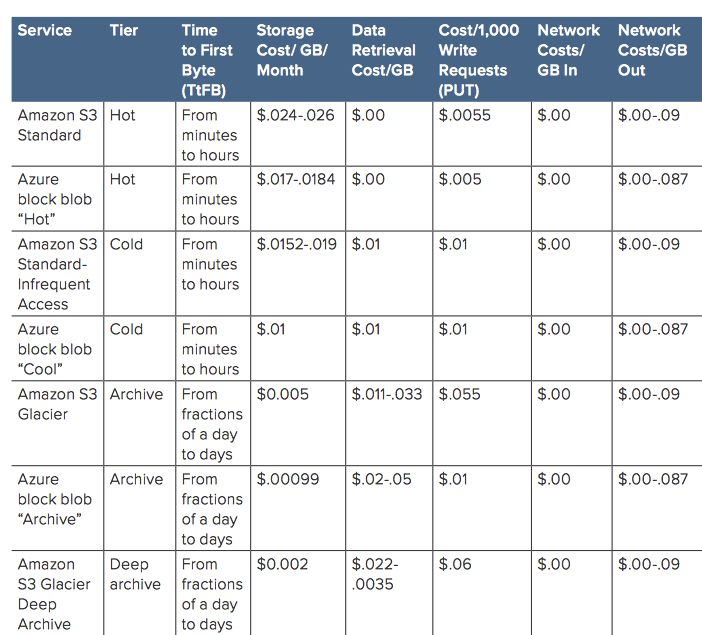
With cheaper, slower offerings, administrators must make a request for the entire object to be restored, then wait a long time to access it. That, in turn, requires an interface in the backup/restore application to request the data needed, along with callbacks that notify the application when the data is accessible.
The better the technology is for cloud tiering, the more options there are to get the best of both worlds: lower monthly cost and faster storage. But those advantages don’t come from simply going the object storage route and moving all backup tasks to the cloud. As with most things cloud, it’s necessary to revisit and optimize the IT architecture.
Starting with security.
Architecture – security and cloud tiering
Object storage does without the overhead of policies, user accounts and access privileges. That means businesses cannot rely on the usual security constructs when locking down an object. Cloud tiering requires a different firewall and different access patterns, along with an associated learning curve.
Just assume that object storage is less secure
Lack of familiarity with object-based storage security can result in data breaches. Many high-pro file data breaches are the result of writing an object to cloud storage (like an Amazon S3 bucket or Azure blob storage) without properly securing the object first. Users and administrators unaccustomed to the practices of infrastructure as a service (IaaS) can easily make mistakes by thinking cloud security works the way traditional, on-premises security works.
How to send data to object storage securely
When a cloud provider owns the infrastructure, it’s impossible to know who all can access the network, who is permitted in the data center and whether security policies are enforced. Therefore, for secure object storage, smart organizations encrypt their data before sending it, and they use their own encryption keys instead of the IaaS provider’s keys.
Applications that securely send data to the cloud share several encryption characteristics. They offer the industry-standard, FIPS 140-2-compliant, 256-bit AES algorithm for encrypting and decrypting user data. They use zero-knowledge encryption to allow for local control of the encryption keys rather than using the cloud provider’s keys. They include ever-changing, rotating encryption keys that further reduce the potential for a bulk data breach.
Those characteristics represent at least the same level of security and process as in most on-premises infrastructure – in some cases, a higher level.
Technology architecture – de-dupe reduces amount of data that heads to cloud
Besides making architectural changes for security, IT teams can address the trade-off between lower pricing and shorter TtFB by rethinking the architecture behind the storage itself. The upshot of Table 1 and Table 2 is that the less data there is to move into the cloud, the lower the overall cost to store and transfer it.
To reduce the amount of backup data that leaves the local infrastructure, the primary technologies available to busi nesses are deduplication and compression. Deduplication uses algorithms to scan the data and remove any elements that have already been stored, replacing them with a pointer to similar, backed-up data.
Specifically, source-side deduplication combined with compression is the most effective way to reduce the size of data to be backed up before it goes to storage. That can speed up the movement of data and increase throughput.
In fact, combining compression and deduplication with a hot or cold cloud tier can deliver the best of both worlds: lower pricing and shorter TtFB.
Architecture – finding right cloud tier technology
Which factors come into play in reducing the amount of data to be stored, before the data leaves the local infrastructure?
Bandwidth
As mentioned above, some companies anticipate the need for a higher-capacity WAN link and an increase in network costs. But because source-side deduplication backups and cloud-tiers only the delta, those companies can see a reduction of up to 80% in needed bandwidth and storage space. That makes a long-term upgrade in WAN link capacity unnecessary.
(Note: Deduplication that does not take place on the source side involves sending a full copy of the data to be backed up. That consumes network bandwidth and storage space on the target.)
Variable-length, sliding-window deduplication
Variable-length, sliding-window deduplication is the gold standard for data reduction. Applications that include it can get data to the cloud, store it there and bring it back on site efficiently, reducing monthly storage costs by up to 95%.
Local storage
Applications that deduplicate on the source side can also take advantage
of on-site capacity to achieve the same RPO without increasing WAN link capacity. They can accelerate data retrieval from the cloud, providing real-time access to data and in many cases restoring data in minutes instead of days.
Transparent operation
In transparent operation, the application reading and writing the data eliminates complexity by behaving the same whether the data is stored on a local device or in the cloud. In effect, it extends local storage to the cloud by backing up and restoring data transparently, without continued e ort or intervention. For restoring data, it liberates administrators from having to figure out where an object is stored and then waiting until its data is accessible again.
Could tier backup – an example
Consider an organization that decides to store data locally for 30 days and back it up to an online cloud tier thereafter.
A transparent application designed for cloud tier data should not need special configuration, and it should replace older and potentially costly methods like tape backup and off-site storage and handling.
Production Data Center
Administrators can simply set a policy in the backup application that automatically deduplicates, compresses, encrypts and sends the data to an available cloud tier after 30 days.
Since data is compressed and deduplicated before being sent to the cloud, the costs can be lower than with cheaper, slower cloud storage such as Amazon Glacier and Azure Archive.
However, this warmer, online cloud tier keeps all backup data easily accessible. Then, when restoring, a transparent application doesn’t require manual intervention. More important, administrators do not need to find files or backup images, or even know where the data is currently stored. They start the restore process on the desired files, then the application does the work of finding and restoring the data. Retrieval is faster because deduplication matches local data objects before calling for data from cloud storage. Also, it is less expensive because the transaction costs to read the cloud data are lower. The application reassembles the files and restores them.
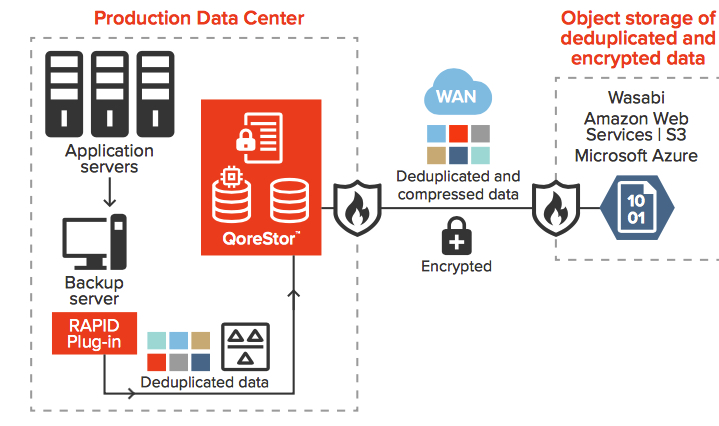
Figure 2 depicts a typical configuration for cloud tier backup using Quest QoreStor, with deduplication and compression to reduce the amount of data sent across the WAN link.
Figure 2: Cloud tier backup from data center to cloud storage providers (Azure, AWS, Wasabi)
Conclusion – questions to ask
To some businesses and administrators, cloud tiering is a tempting alternative to tape backup: newer technology, less overhead, lower storage costs and fewer points of failure. But before simply sending all their backups and archives from tape to the cloud, administrators should consider their architecture in light of a few strategic questions:
• How much data will I have to store monthly?
• How frequently must I retrieve and handle the data?
• How long should I keep the data on site before sending it to cloud?
• Should I keep two copies of that data in case of a disaster?
• What RPO and RTO do users expect for restore jobs? How quickly must I be able to retrieve and restore data?
• When I have multiple restore jobs queued up, can I use the time productively? Or must I babysit each job and wait for it to finish?
• How much more efficiently could I work if all data movement were automated through policies?
• How much easier would my job be if all my backup data (no matter how old) was immediately accessible?
Online cloud tier technology – combined with the right backup application, compression, source-side deduplication and encryption – offers the best options for a transparent, cost-effective data protection strategy. It uses low-cost cloud object storage for highly effective restoration of data from the most recent backups and longer-term archives.
With changes to the architecture to take advantage of object storage, sending data o site is fully automated and retrieval is transparent. Companies can lower the cost of data protection and free up the time and resources of backup administrators for higher-value tasks. A transparent cloud tier solution reduces all the hard work, cost, time and risk.



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter


