






Robin Systems With Hyper-Converged Kubernetes Platform
Brings self-service App-store experience and increases efficiency to big data, databases and AI/ML.
This is a Press Release edited by StorageNewsletter.com on August 31, 2018 at 2:22 pmRobin Systems, Inc. announced a hyper-converged Kubernetes platform that brings self-service App-store experience and increased efficiency to big data, databases and AI/ML.
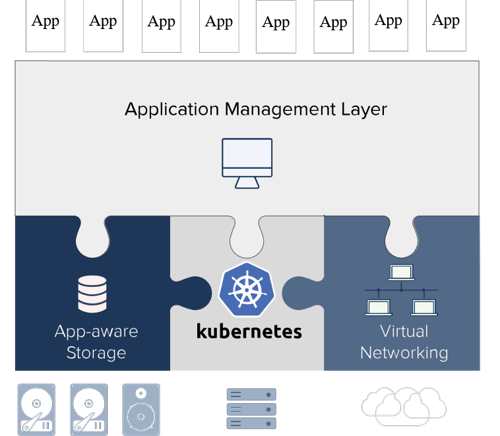
The company is a purpose-built Kubernetes-based solution with the entire application lifecycle management embedded natively into the compute, storage, and network infrastructure stack for any application anywhere (on-premises and on the public cloud).
Kubernetes is the facto standard for container orchestration for microservices and applications. However, enterprise adoption of big data and databases using containers and Kubernetes is hindered by multiple challenges such as complexity of persistent storage, network, and application lifecycle management. Using the hyper-converged Kubernetes technology, with built-in enterprise-grade container storage and flexible overlay networking, ROBIN eliminates these challenges and extends Kubernetes’ multi-cloud portability to big data, databases, and AI/ML.
It offers a self-service app-store experience that simplifies deployment and lifecycle management with one-click functions that shorten DevOps and IT tasks from hours and weeks to minutes. It makes applications agnostic of infrastructure choices and enables them to share resources and data with predictable performance, leading to cost savings.
Unlike existing Kubernetes offerings that do not control the complete infrastructure stack, hyper-converged Kubernetes offers built-in resources for native storage, compute and network, and an application management layer to control them so that DevOps and IT operations are simplified. Without this end-to-end resource management, conventional offerings cannot control QoS, performance SLAs, and lifecycle management. Hyper-converged Kubernetes architecture, on the other hand, lets users dynamically adjust and guarantee resources, and enjoy one-click lifecycle management operations to scale, migrate, snapshot, upgrade and patch even big data, databases and AI/ML applications.
It is an implementation of hyper-converged Kubernetes. Using Robin users can do self-service deployment of big data, databases and AI/ML, share entire experiments among team members, quickly do what-if trials, scale resources including GPU and IO/s, and migrate as well as recreate entire application environments across data centers and clouds.
Click to enlarge
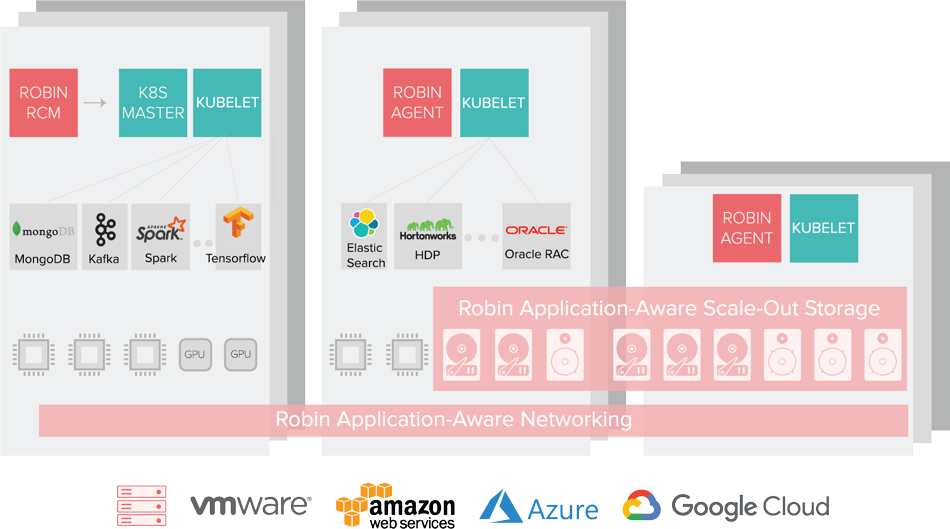
“Customers in the process of modernizing their IT infrastructure want the benefits of agility and efficiency from containerization and Kubernetes, and Robin is the first Kubernetes based platform to achieve the rigorous QATS certification for Hortonworks Data Platform,” said Scott Andress, VP, global channels and alliances, Hortonworks, Inc. “With Hyper-converged Kubernetes, Robin makes it simple to deploy and manage HDP on Kubernetes. We are excited about this collaboration and look forward to working with Hortonworks customers who choose the Robin Hyper-converged Kubernees platform for their HDP deployment.“
“Most enterprises are interested in improving agility and infrastructure efficiency through DevOps. Containers and Kubernetes can be key to achieving these improvements, but significant challenges persist, especially when incorporating advanced technologies and workloads such as big data, artificial intelligence, machine learning and IoT,” said Jay Lyman, principal analyst, 451 Research. “Software that brings these technologies together with container and Kubernetes-based infrastructure and application lifecycle management can help enable agility and efficiency for these data-rich and data-heavy applications.“
“For large enterprises, modernization and optimization are a continuous process. Running highly advanced, distributed, and performance optimized applications is not easily containerize-able or adoptable to Kubernetes,” said Mikael Loefstrand, VP, multi-cloud technology office, cloud architecture and engineering, SAP Labs. “I’m looking for a solution that could bring hyper-convergence into the Kubernetes ecosystem. This goes beyond just running containers or clusters in hyper-converged boxes (compute, network, storage), and into modern updated stacks enabling Kubernetes to marshal the entire application and IO path.”
Read more.
“Enterprises have traditionally had to develop custom workflows per application to deploy and manage databases and applications in their big data/AI/ML pipelines,” said Premal Buch, CEO, Robin. “The process requires IT and DevOps to undertake lengthy third-party integrations as well as a tedious, manual, repetitive process for each on-premise and cloud installation. This only leads to high cost, complexity, and delayed time-to-value. With hyper-converged Kubernetes, Robin eliminates time and cost drain for IT and DevOps and empowers them to achieve faster roll-out of critical initiatives.“
DevOps and IT teams are already using the Robin to ingest and analyze eleven billion security events daily. Customer deployments also include active management of 6PB data in a single cluster and management of 400 Oracle RAC databases by a single Robin cluster.
Robin hyper-converged Kubernetes platform features for DevOps and IT:
-
Provision, scale, clone and migrate big data and databases with one-Click
-
Achieve time-travel between application states
-
Clone the entire application including data
-
Perform one-click backup and restore for the entire app, any app
-
Upgrade any application in a failsafe manner
-
Perform one-click control QoS of each app to meet performance SLAs
-
Enable data and application mobility across clouds



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

