







Exclusive Interview With Tarun Thakur, CEO, Datos IO
Start-up in application-aware, cloud-scale data management software built for cloud
By Philippe Nicolas | January 18, 2017 at 3:11 pm
Who is Tarun Thakur ?
He is:
- Co-founder and CEO, Datos IO, Inc.
He was:
- Various product positions at Data Domain then EMC
- Product manager at Symantec for Veritas Data Protection product
- Strategy consultant at Campbell Alliance
- At IBM Almaden Research Center
- Senior software engineer at Ario Data Networks (acquired by Xyratex)
- Started as firmware engineer at Seagate Technology
StorageNewsletter: Datos IO is a pretty recent company, could you summarize the genesis and background of the company?
Tarun Thakur: Backup, BC and DR have all been a critical part of IT for over 30 years – ever since we began relying on technology to run our businesses. Traditional solutions were designed for the world of on-premise infrastructure and structured applications and relational databases.
But the world is changing. Application and data platforms are undergoing the biggest transformation since the dawn of computing – what analysts are describing as the era of digital transformation. New applications are geo-distributed, scale across multiple systems, are always on, and are typically deployed in a cloud-first model. Companies are moving production workloads to these new platforms, but as we talked about on the Datos blog, existing backup and recovery tools can’t protect them effectively or efficiently.
That is where Prasenjit Sarkar, my co-founder and I, have both spent our careers in enterprise storage, backup and recovery. We saw a unique opportunity to reinvent backup and recovery for this new era of computing and give customers a way to fully protect modern applications. We founded Datos IO two and a half years ago and have pursued the core goal to create the industry’s first application-centric data management platform for next-generation applications and enterprise deployed across private cloud, hybrid cloud and public cloud environments.
Who are the people behind Datos IO? What are the products or storage technologies they already developed?
I’m the co-founder and CEO of Datos IO. Dr. Prasenjit Sarkar is the co-founder and CTO. With a focus on big data, distributed systems, and file systems, he has defined and led industry disruptions including inventor of iSCSI protocol, delivered storage and systems products, and led product development organizations to deliver next-generation solutions – all while generating millions of dollars in revenue for IBM.
How is the company capitalized? VC money, others? And are you looking for additional VC round?
Datos IO raised over $15 million through its series A round two years ago from VCs, Lightspeed Venture Partners and True Ventures.
What’s the company vision?
Datos IO is pioneering a new market category – application-centric data management – uniquely suited to protect next-generation applications deployed on cloud databases and traditional applications that are being migrated to the cloud.
- Data Protection: scale-out backup and recovery platform
- Data Mobility: migrating data to the cloud with global data visibility
- Data Monetization: deriving value and delivering data management services
What are the challenges to solve?
We’re helping customers accelerate their transition to cloud and next-generation applications by solving 3 key problems:
- Giving them a reliable, efficient backup and recovery solution for modern applications and databases – such as MongoDB and Cassandra – so they can run production workloads on them confidently.
- Doing this at cloud scale. We had to tackle a number of technical challenges, such as parallel streaming-based data movement, application consistency, and fully orchestrated reliable point-in-time recovery in a multi-node distributed cluster.
- Simplify DevOps and Continuous Integration/Delivery by giving teams the ability to quickly clone production databases.
What kind of storage product is it?
Datos IO RecoverX is an application-aware, cloud-scale data management software built for the cloud.
So Datos IO has a new approach for cloud data management, in which ways?
Because of the deep insights that we have in the space of data protection, backup and recovery, and broader data management – and, how all of these are ready to reinvented for the distributed application architecture with the cloud era.
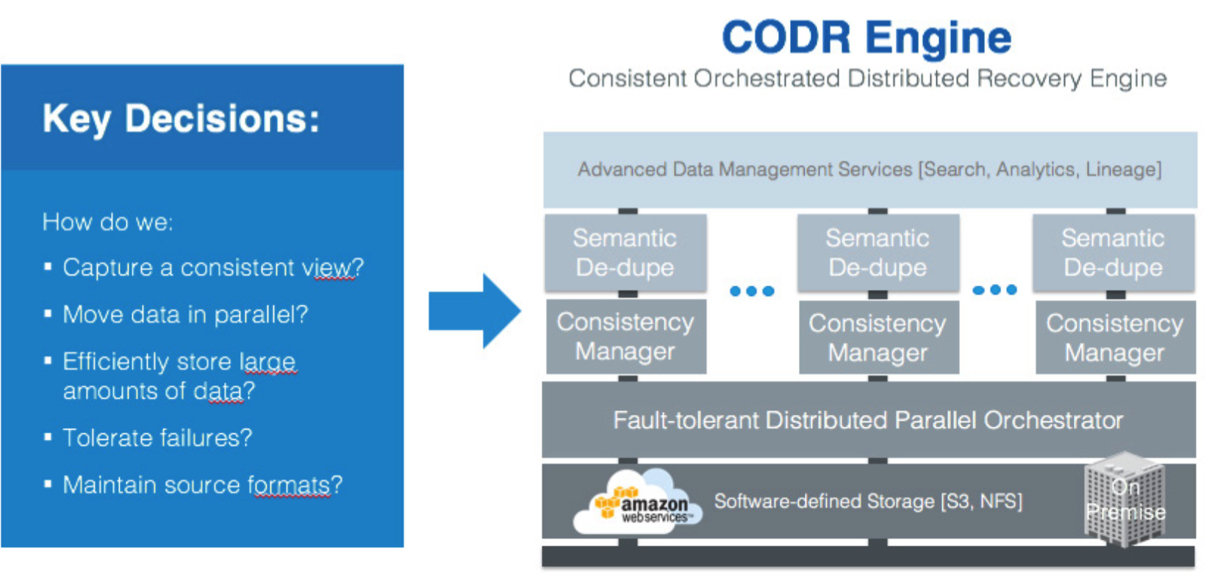
The most fundamental to our approach is our Consistent Orchestrated Distributed Recovery (CODR) architecture, next-generation scale-out data protection architecture that is based on elastic compute services that can be auto-scaled with load, removes the dependency on media servers and transfers data in parallel to and from file-based and object-based secondary storage. The core of the architecture is ability to have enable consistent versioning and industry-first semantic deduplication that is application-centric when it comes to storage efficiency. In addition, the pure software-defined approach enables customers to address data management use cases across public and multi-clouds (DR in cloud A, test/dev in cloud B, etc.).
Could you elaborate on RecoverX?
RecoverX’s cornerstone is a patented CODR, a non-media server dependent solution that transfer data efficiently in parallel to and from file-based and object-based secondary storage. CODR delivers highly space efficient application-consistent backups available always in native formats on secondary storage, for application-ready, repair-free recovery. It provides a consistent view of data even in the event of hardware failures. Additionally, RecoverX v1.5 enhancements include granular node-level recovery for quick recovery from dedicated node failure, enhanced security via application-aware data masking (hiding PII) and compaction-related optimizations to reduce secondary storage costs without sacrificing retention time periods.
What is your link with open source?
We believe that open source will become the de facto standard of all enterprise software in the years to come. The economics and the massive developer base behind open source software will enable some of the large enterprise customers to go ‘open-source-first’ strategy. Today, RecoverX supports both open-source (Apache Cassandra) and commercial versions of databases (DataStax). In addition, we are giving back value-added tools to the open source community. For example, we open-sourced our test automation framework – Geppetto – on Github. In future, we are plan to open-source more tools and components of our product.



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

