







Storage Outlook – Fred Moore, Founder of Horison Information Strategies
Emerging concepts playing significant role shaping future of storage industry
This is a Press Release edited by StorageNewsletter.com on September 27, 2016 at 3:03 pm Sponsored by Oracle Corp., this report was written in June 2016 by Fred Moore, founder of Horison Information Strategies, an information strategies consulting firm in Boulder, CO, that specializes in strategy and business development for IT and storage companies. He began his 21-year career at StorageTek as the first systems engineer and concluded as corporate VP of strategic planning and marketing.
Sponsored by Oracle Corp., this report was written in June 2016 by Fred Moore, founder of Horison Information Strategies, an information strategies consulting firm in Boulder, CO, that specializes in strategy and business development for IT and storage companies. He began his 21-year career at StorageTek as the first systems engineer and concluded as corporate VP of strategic planning and marketing.
[If there is a last one, it will be Moore, being during his career a solid supporter of tape technology. Ed.]
Storage Outlook
Executive Summary
The storage industry is constantly evolving, not only in the underlying technology but also in how storage is deployed, managed, protected and consumed. If you can imagine a time when things are changing so fast even the future is obsolete, that time is now!
Major new disciplines such as big data analytics, cloud computing, the hyperconverged infrastructure, impenetrable data protection, object storage, software-defined storage, and the IoT is giving IT and storage teams countless reasons to architect more advanced solutions than ever before to meet the relentless demands of the business. Storage workloads are growing, and modern data centers increasingly require more highly scalable environments to run their most demanding enterprise applications.
These factors are further impacted by the need to manage, store and protect data forever in the face of a continuing shortage of trained storage personnel. Guided by these 21st-century trends and others, businesses are constantly looking to gain significant efficiencies and turn IT into more of a service, and they have given rise to the cloud as a popular services provider. Let’s take a look at several of the emerging concepts that are playing a significant role shaping the future of the storage industry.
Big data is a broad and widely used term for data sets – both structured and mainly unstructured – so large or complex that many traditional data processing applications are inadequate. The term big data can often refer to the use of predictive analytics or other advanced methods to extract value from enormous amounts of data. With unstructured data now accounting for nearly 90% of all data being created, big data challenges include analysis, capture, data curation, privacy, search, sharing, storage capacity, transfer, and visualization.
Analysis of large and complex data sets can discover new correlations to spot business trends, prevent diseases, and combat crime. Consider that the challenge of over one hundred satellites orbiting the earth producing hundreds of terabytes of data daily to be mined in a timely basis for trends, national security, weather considerations, demographic characteristics and other revelations and it becomes almost unimaginable.
Cloud computing is currently shaping the data center possibly faster than all other technology forces. Today the cloud is a mainstream architecture due in large part to the growing recognition of its role as a powerful business enabler for mobile and social business computing, analytics along with many data intensive applications. In traditional IT, demand for applications and capacity is forecasted and requires time and money to develop the appropriate resources in-house or purchase them and operate them in-house.
With cloud computing, clients aren’t required to own their own or manage infrastructure enabling them to avoid significant capital expenditure and complexities. A cloud storage system is typically comprised of HDDs and tape, and we are witnessing the emergence of the cloud as a new storage tier. Data in the cloud can be accessed from anywhere, provided the location has Internet access, offering remote access without a physical storage device. Cloud computing is considered a disruptive technology that is quickly changing the information technology and storage business model.
Cold storage refers to low or no – activity data, but is becoming a hot technology. Approximately 70% of the data created quickly becomes inactive, creating what is commonly referred to as cold storage. High capacity, low cost, and long-term retention are important goals for cold storage. Cold storage solutions favor tape libraries, the active archive concept, and low-cost commodity HDDs. Tape storage is the most cost-effective home for cold data, and these solutions are becoming integrated into the cloud infrastructure.
Hyperconverged infrastructure (HCI) is an integrated solution that combines storage, computing, network and virtualization in a single hardware box or appliance. HCI often includes site-to-site replication, a cloud archive, and hardware-accelerated 256-bit encryption and other functionality. HCI focuses on overcoming the challenges of fragmented data silos caused by the adoption of various point solutions to handle backup, file services, analytics, and other secondary storage use cases.
The HCI solution can be costly and is currently best suited for smaller deployments and secondary applications in the SMB segment. For larger scale environments, HCI has not yet become the solution of choice for cost and manageability reasons, but this could change going forward.
Impenetrable data protection and data recovery have emerged as an overriding factor for most IT strategies today. The number of U.S. data breaches tracked in 2015 totaled 781, according to a recent report released by the Identity Theft Resource Center (ITRC) and sponsored by IDT911 – representing the second highest year on record since the ITRC began tracking breaches in 2005. Regarding reputation impact, not all data breaches are equal.
Data breaches have a significant impact on whether a customer will ever interact with a business again. Planning for data protection resulting from problems with hardware, software, malicious people, security breaches, theft and natural disasters has never existed at this level of intensity before. For organizations that fail to address their security vulnerabilities, the problem is only going to get worse as stricter regulations governing the reporting of data breaches are introduced across the world, making breaches more visible to the public.
Object-based storage is gaining momentum and is a form of software-defined storage. IT organizations are facing increasingly complex problems regarding how to manage petabytes of data and archives that consist of hundreds of millions or even billions of unstructured data objects.
With object storage, unstructured data is stored and accessed with its object ID, along with rich metadata that further describes the object. Object storage can increase the scale and flexibility of underlying storage and will coexist with file and block storage systems for the foreseeable future.
Object storage can be implemented at multiple levels, including the device level, the system level, and the interface level. At each level, object storage seeks to enable capabilities not addressed by other storage architectures.
Software-defined storage (SDS) is a quickly evolving concept using storage software to much more efficiently use policy-based provisioning for the management of the storage devices, making storage appear to be independent of the underlying hardware. SDS typically implements a form of storage virtualization to separate the storage hardware from the software that manages the storage infrastructure. SDS provides significant flexibility and ease of use for defining and managing hardware systems.
The IoT is the network of physical objects or ‘things’ embedded with electronics, software, sensors, and network connectivity which enable these objects to collect, store and exchange data. The IoT promises to transform the Internet from a network of human and information interaction to interaction among appliances, machines, components, systems, autonomous automobiles, and humans along with enormous volumes of information generated daily.
Various industry sources estimate that the IoT will connect over 25 billion ‘things’ to the Internet by the year 2020. If it has an IP address and connects to the network, it will be a candidate for a node in the IoT. There’s been far more energy spent on connecting things to the Internet than securing them. The advent of IoT also signals that information security systems must effectively address a completely new and far more complex set of vulnerabilities than ever before. The IoT could completely transform the security industry.
The Increasing Demand for Advanced Storage Solutions
Data Growth and Storage Requirements
2016 Storage Scenario
- WW Population >7.3 billion – Asia >4 billion.
- >3.3 billion Internet users (46%).
- 6.8 billion mobile phone users.
- Digital Universe was 4.4 ZB in 2013. 44ZB in year 2020 (doubling every two years).
- In year 2020, 44ZB will be 5.2 TB per person worldwide.
- Approximately 42% of all data is duplicated (at least once).
- Approximately 33% of data is compressed (2 times).
- Approximately 5% of data is transient (temporary).
- 7% of all data is unstructured (hard to navigate).
Note: Amount of Data Created ≠ Amount Data Stored
Data Classification by Business Value
Not All Data is Created Equal!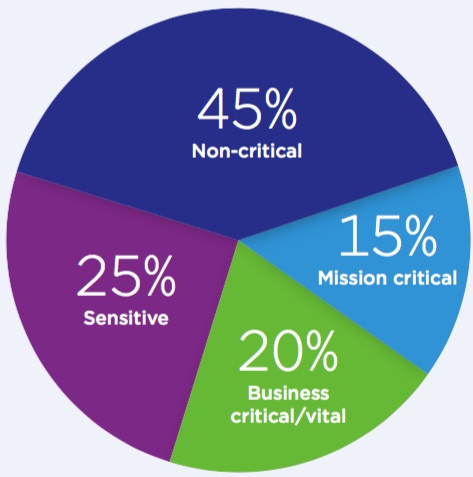
How Much Storage Is Needed After Data Reduction?
(in ZB for 2020)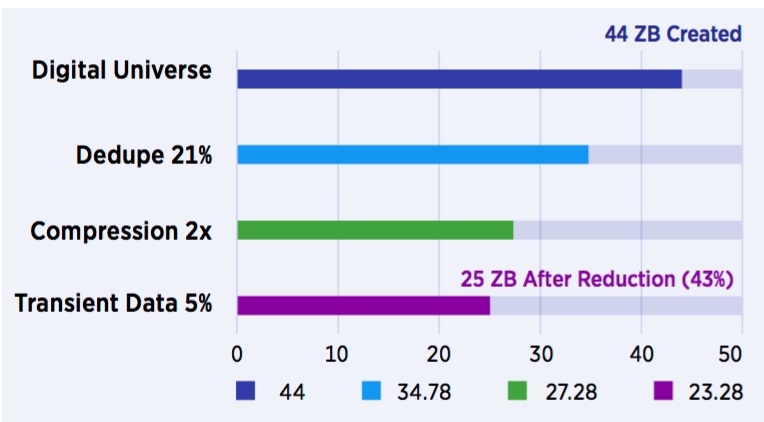
(Source: EMC IDC, Horison, Inc.)
- It is estimated that newly created digital data is doubling every two years and are now being generated by billions of people, not just by large data centers as in the past.
- Nasuni Corp. predicts around 2.5EB of data are created each day, and this trend is being fueled by over 3.3 billion Internet users and 6.8 billion mobile phone users worldwide as this market is far from saturation.
Big Data and the IoT could ultimately push annual digital data growth towards 100%ushering in the era of colossal content and requiring exascale storage systems with highly intelligent storage to address the growth.
- 90% of the data in the world today was created within the past two years, and the vast majority of it reaches the archival status in a relatively short period?
- New data management methods will be required – data reduction, Hadoop, HSM, parallel file systems, scale-out file systems, software defined storage, Dispersal, RAIT.
- The rules of IT security, data protection, HA, and DR will change.
The amount of data created is often and incorrectly assumed to be the same as the amount of data stored significantly impacting the accuracy of the capacity planning process. Data reduction techniques such as deduplication and compression reduce the physical amount of storage required.
Additionally, as much as much as 5% of data is transient lasting only for the duration of the transaction or session and is not permanently stored further reducing the net storage requirement. No more than 5% data is intentionally deleted given the common practice to ‘save everything .’ As a result, the amount of data generated and the net amount of storage required are not the same.
The Tiered Storage Hierarchy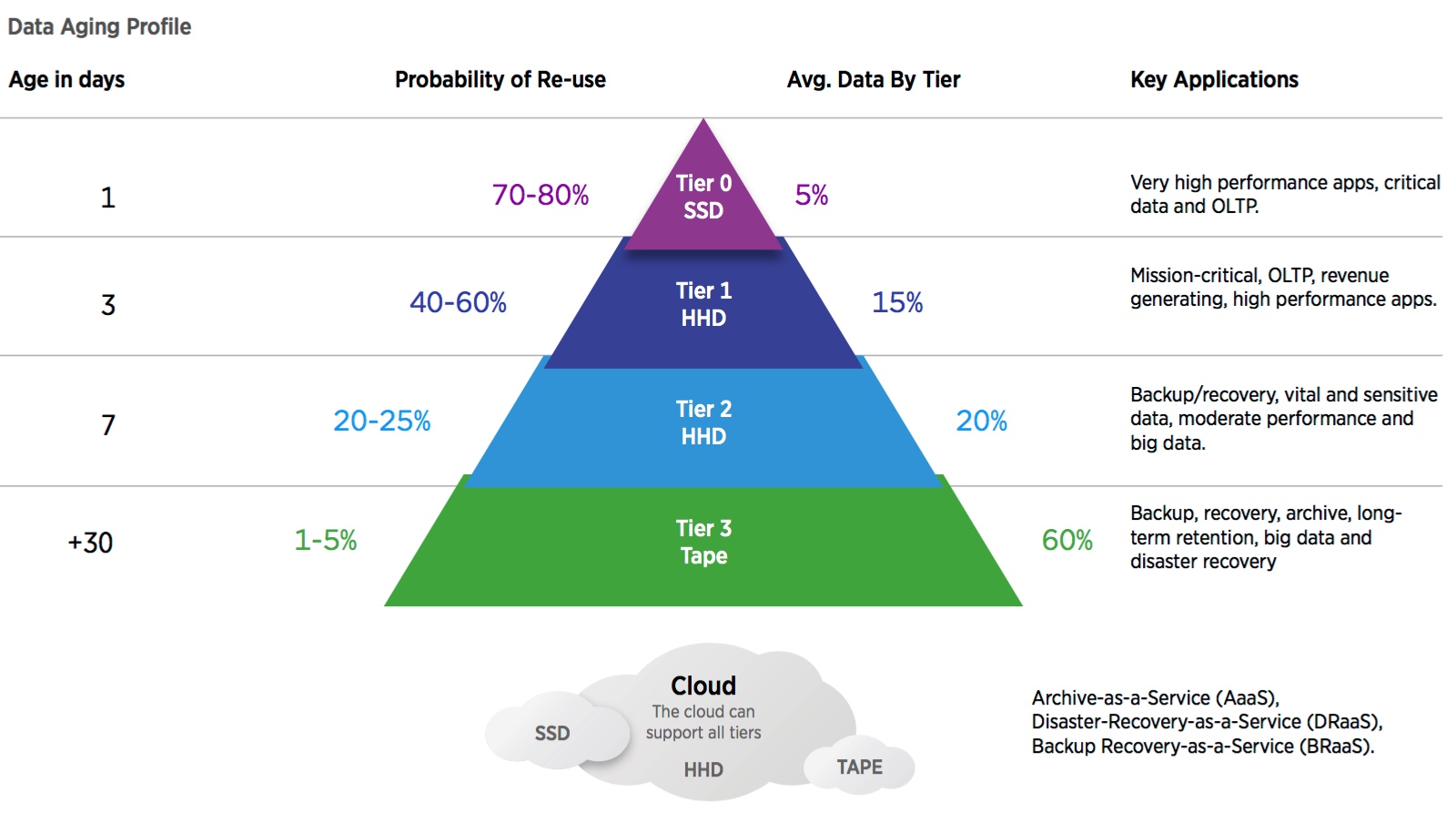
The selection of storage solutions has never been greater, and many of these options represent individual levels or tiers of the storage hierarchy. Organizations are implementing tiered storage to significantly lower cost and improve operational efficiency. Today’s choices range from ultra-high performance SSD at the top of the hierarchy to very high capacity, low cost, lower performance storage at the other end. Each tier offers advanced data management functionality coupled with a wide selection of data protection and security features.
Tiered storage is the process of assigning different classifications of data to different types of storage solutions to reduce total storage cost and still meet service level requirements. The cloud is emerging as a new storage solution which can combine SSD, HDDs and tape into its own tiered hierarchy.
One of the key parameters for tiered storage is the data aging profile which applies to most data types. The probability of accessing most data types declines as the data ages since its creation date and the data moves towards archive status over time. Tiered storage is an underlying principle of data lifecycle management. A tiered storage strategy can use two, three, or four tiers, with four tiers providing the optimal combination of cost and performance.
The foundations of tiered storage had their beginnings over 30 years ago when disk, automated tape libraries, and advanced policy-based data management software (now known as HSM) combined to migrate less active data effectively to less expensive storage devices. The business case for implementing tiered storage is strong and becomes more compelling as the storage pools get larger.
Tier 0 Storage
Storage Class Memory and Solutions
SSD Scenario
Storage Class Memory – Several SSD and Hybrid Implementations
- First SSD in 1978 (STK 4305 at $8,800/MB – DRAM).
- All Flash Arrays (AFAs) and Hybrid Flash Arrays (HFAs) are showing explosive growth.
- SSD capacity is now at 15.36TB (SAS).
- IO/s intensive applications, databases, OLTP and HPC burst buffer.
- Non-volatile and low power (one-third of HDD).
- No moving parts and high reliability – BER 1×1017????.
- Read access times: 0.2ms approximately 50 times faster access than HDD.
- Flash success is impacting HDD sales from enterprise to desktop.
- 3D NAND technology is on the on the horizon.
- Tier 0 is all about performance!
Storage Class Memory (SCM) devices (tier 0) are made from DRAM, flash, or silicon chips instead of rotating disk platters or streaming tape and are referred to as SSD. The first successful SSD product was developed for the IBM S/370 mainframe market in 1978 by StorageTek having a list price of $8,800/MB. That equates to $8.8 million per gigabyte using today’s pricing metric!
While HDDs will account for the majority of online storage capacity in the near future, their place within the storage hierarchy is being squeezed as HDDs are increasingly being replaced by flash SSDs for high-performance applications and by tape for lower activity and archival applications.
The vastly higher IO/s performance of SSDs in comparison to the fastest HDDs, reduced energy consumption, and the rapidly decreasing cost per gigabyte of flash memory are key factors in influencing this shift.
Looking ahead, SSDs have now outgrown HDDs regarding capacity and with 3D NAND architecture on the horizon, capacities will increase significantly. However, basic flash performance has only slightly improved (read, write and erase latencies) over the last decade. New solutions will focus on reducing cost and increasing the effective storage capacity to eventually serve specific cloud workloads that are dominated by reads and do not have stringent requirements on write performance and endurance.
Flash memory is now widely used from supercomputers to the desktop to personal appliances, and this widespread appeal makes flash storage increasingly cost-effective for data center usage. Expect a much faster SSD made from NVM (Non-Volatile Memory) such as PCM (Phase Change Memory) to supplant flash eventually as the preferred tier 0 media.
Key Flash Architectures
Traditional hybrid flash arrays combine a relatively small amount of flash media capacity with a larger complement of HDDs and use block-level storage tiering to deliver better performance than standalone HDDs with equivalent cost.
AFAs exclusively use SSDs and provide very high level of performance with the lowest latency possible. Compaction technologies like compression and deduplication used in conjunction with larger-capacity SSDs can bring all-flash costs closer to HDD levels. Look for all-flash arrays that can deliver consistent performance without compromising resiliency, scalability, or data mobility to gain market share steadily.
Converged flash arrays are a new variation of the all-flash array that can accommodate disk media as well, offering the high performance and zero latency of an AFA, the affordability of a hybrid array, and the agility of a unified array that supports files, block workloads, and object access. This new type of memory class storage array supports HDDs for capacity scalability, with the ability to allocate and automatically migrate data to HDDs as that data ages.
3D NAND flash is still in the development phase. 2D NAND (Two-dimensional not NAND) flash memory is widely used in cell phones, appliances, tablets and SSDs is getting cheaper and more capable every year. Ultimately there will be a 3D NAND flash limit to how much data can be packed into a given area of silicon since 2D NAND flash cannot be scaled much farther in length and width on the dyes surface.
NAND flash has a finite number of write cycles, and NAND failure is usually gradual as individual cells begin to fail, and overall performance degrades, a concept known as write-fatigue or wear-out causing flash vendors to overprovision their systems by including more memory capacity than is claimed. 2D NAND flash has enormous economies of scale and billions invested in fabrication plants across the world.
To address the certain limits of 2D NAND, flash vendors are working to move flash memory cells into the third dimension, which is called 3D NAND or 3D NAND stacking. The new 3D NAND technology stacks flash cells vertically in 32 layers to achieve a 256GB MLC and 384GB TLC die that fit within a standard package.
3D NAND eliminates the need to reduce dimensions by just adding more layers and is twice as fast, uses one-half the power, and has twice the number of cells per in2???? as 2D NAND with ten times the cell endurance while increasing capacity. 3D NAND and PCM (Phase Change Memory) are the best options to replace 2D NAND shortly as demand for tier 0 storage rapidly grows.
Tier 1 and Tier 2 Storage
HDD Technology and Solutions
Disk Storage Scenario
- HDD capacity is growing 20-30% while areal density growth is slowing.
- Current maximum HDD capacity at 10TB (SAS).
- Low HDD utilization (less than 50%) increases end-user costs.
- Future HDD performance gains are minimal.
- Longer RAID rebuilt times – dispersed storage and erasure coding are expected to replace RAID
- Reliability (BER) has fallen behind tape.
- Shingled Magnetic Recording (SMR) helps address physical Limits (track overlap).
- SED deployment remains minimal.
- HDDs can address all data types and requirements.
HDDs (HDD drives or just disks) have always been the workhorse of the storage industry and can handle any data requirement. Tier 1 HDDs are faster, more reliable and more expensive than their tier 2 counterparts. Typically, FC and SAS drives are used for tier 1, and SATA drives are used for tier 2. HDD capacity is expected to continue to grow at 16% per year with the potential to reach 20-40TB by the end of the decade while still maintaining the industry standard 3.5-inch form factor.
Looking to the future, there is considerable uncertainty regarding future scaling rates of HDD due to the challenges associated with overcoming the super-paramagnetic effect and the uncertainty over the timing and the eventual success of the introduction of new technologies needed to continue HDD scaling. HDDs with 10TB are starting to answer the industry’s high capacity, random access storage needs but are facing several challenges to deliver increased capacity and performance. HDD performance has seen little improvement in recent years.
HDD manufacturers are now facing other challenges as they attempt to sustain sales in the coming years as flash is capturing an increasing portion of the high-performance market while tape has become more cost-effective and reliable for long-term storage. Essentially the trade-offs all come down to the price. Flash and tape prices have been falling quickly and are expected to continue this trend in the coming years, thereby posing a mounting challenge to HDD makers.
Over the next few years, HDD manufacturers are hoping technologies like Heat-assisted Magnetic Recording (HAMR) and Shingled Magnetic Recording (SMR) that allow higher areal densities will quickly come online. Combined with helium-filled HDD technology, these should produce drives offering higher densities using less power and generating less heat than their predecessors.
Seveal New HDD Concepts Are Arriving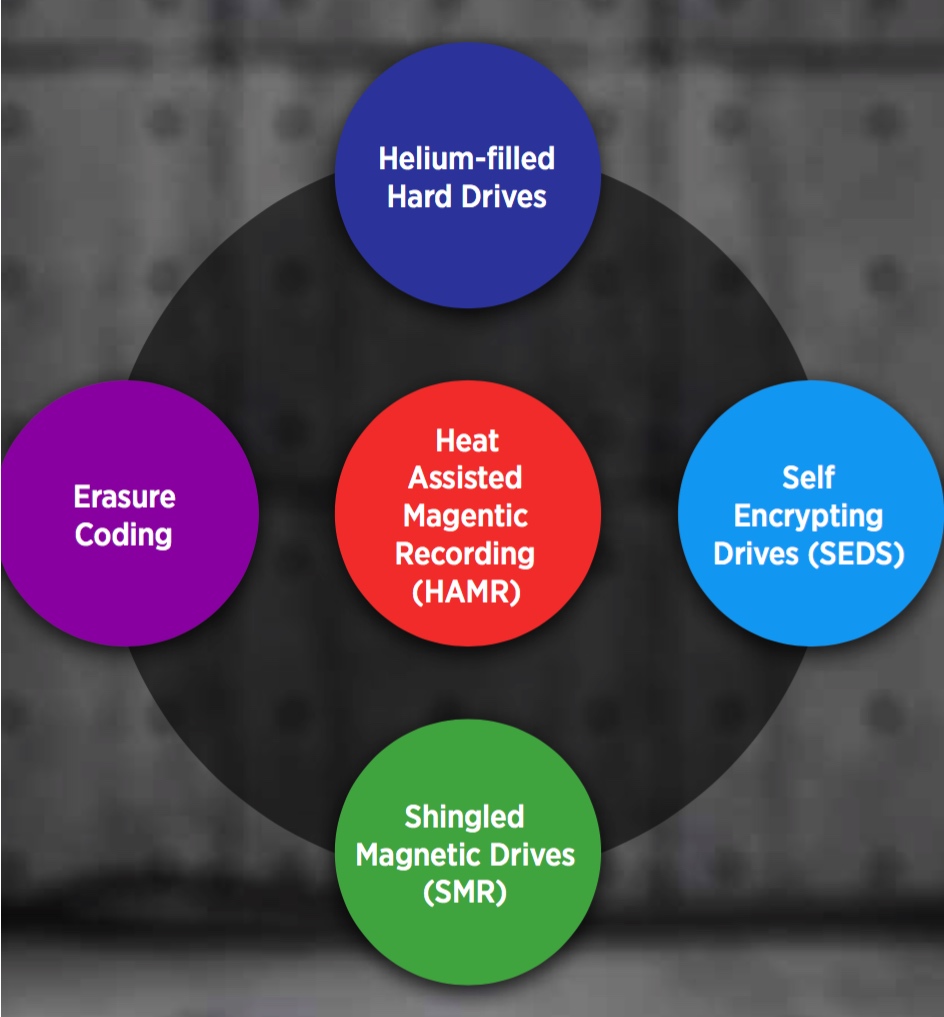
HAMR is a data recording technology for HDDs in which a small laser is used to heat the part of the disk surface that is being written to. The heat changes the magnetic properties (its ‘coercivity’) of the disk for a short time, reducing or removing the super-paramagnetic effect while writing takes place.
The effect of HAMR is to allow writing on a much smaller scale than before, significantly increasing the amount of data that can be held on a standard disk platter. HAMR was initially seen as being difficult to achieve which raised some doubts about its commercial feasibility. As of the year 2016, no HDDs using HAMR are currently on the market, but HAMR continues to be in an advanced stage of development with demonstration drives being produced.
Helium-filled HDDs are not entirely new to the HDD industry as helium has been considered for over 40 years. However, no company had been able to make it work on a consistent basis because helium has a tendency to leak easily out of its container as in the case of birthday balloons which droop in a few days.
The result of a leak for a helium-filled HDD is much more severe since the drive will stop working and all access to data is lost. With the leakage problem adequately addressed, helium-filled drives use less power to spin the disks (which spin more smoothly thanks to less resistance compared to air), they run cooler, and they can stack more disks in the same space. Helium drives currently feature seven platters, and a rise from five platters to seven yields a 40% increase in surface area and therefore a 40% growth in storage capacity over five-platter drives.
Self-encrypting drives (SED) leverages hardware built into the disk drive controller that encrypts all data written to the magnetic media and decrypts all the data read from the media automatically. All SEDs encrypt all the time from the time it leaves the factory, performing like any other HDD, with the encryption process being completely transparent to the user. A user provided password is used by the drive to encrypt or decrypt the media encryption key. In this way, even the media encryption key cannot be known without knowing the password.
By design, SEDs do all the cryptography within the disk drive controller, which means the disk encryption keys are never present in the computer’s processor or memory where hackers could access them. Given the countless number of data security threats, market acceptance of SEDs has been slow as IT security professionals are not typically involved in the buying decision. Also, because HDD suppliers usually sell to the OEM suppliers and resellers, there is little demand being created for SEDs. This is puzzling given the number of high-profile data breaches, hacker activity, that are fueling the rapidly growing need for improved data security.
SMR is a relatively new HDD recording technology first introduced in the year 2014. As with helium-filled drives, SMR technology allows for higher capacities on HDDs than traditional storage methods. SMR achieves higher areal densities by overlapping tracks, analogous to shingles on a roof, allowing more data to be written to the same space. As new data is written, the drive tracks are trimmed, or shingled. Because the reader element on the drive head is smaller than the writer, all data can still be read off the trimmed track without compromise to data integrity or reliability.
Also, traditional reader and writer elements can be used for SMR enabling SMR HDDs to help manage costs and avoid developing new technology. The increase in capacity from SMR limits the random write performance while sequential R/W and random read performance is similar to existing HDDs. This makes SMR drives especially suitable for streamed data, data archiving and lower activity data.
Erasure coding is gaining momentum as continuously increasing HDD capacities have made HDD RAID rebuild times unacceptably long for many organizations. High capacity HDDs can take several days to rebuild and have encouraged efforts to replace RAID for hardware failure protection. As a result, alternative redundancy technologies such as erasure coding are emerging to pick up where RAID stops. Erasure coding is a method of data protection in which data is broken into fragments that are expanded and encoded with a specific number of redundant fragments of data, and stored across different locations, such as HDDs, storage nodes or geographical locations.
The goal of erasure enoding is to enable corrupted data to be reconstructed by using information about the data that is stored within the array or even in another geographic location(s). Erasure coding works by creating a mathematical function to describe a set of numbers which can be checked for accuracy and recovered if one is lost. Sometimes referred to as polynomial interpolation or oversampling, this is the fundamental concept behind erasure coding methods.
Erasure coding also consumes much less storage than disk mirroring, which effectively doubles the volume and cost of storage hardware, as it typically requires no more than 25% additional capacity. Erasure coding’s high CPU utilization and latency make it better suited to storage environments with large, moderately active datasets and a correspondingly large number of storage elements.
What’s on Your Disk?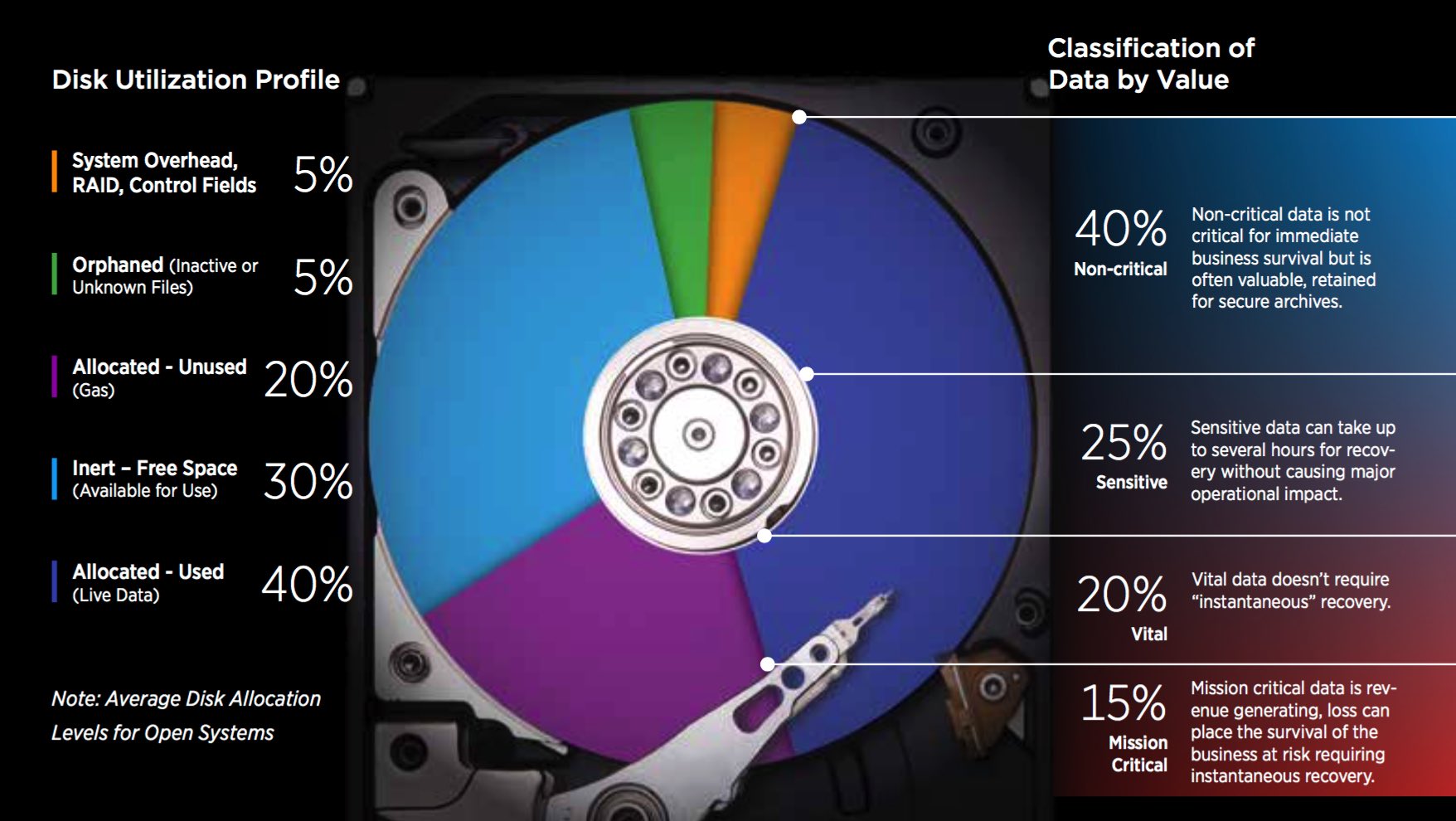
To cope with data growth, focusing less on improved capacity allocation efficiency and more on capacity utilization efficiency yields the bigger benefits. A surprise to many, the average disk drive has about 60% of its total capacity allocated while just 40% of its total capacity contains live (real) data. About 60-70% of the data stored on the average disk is relatively lower activity data, infrequently referenced and seldom-if-ever changed data, making it an excellent archive candidate in a relatively short period.
The remainder of disk capacity is consumed by a mix of system overhead, inert, orphaned data, unknown files and miscellaneous data copies that, if migrated from either a disk or flash storage system, will enable a substantial amount of expensive primary storage to be returned to productive use, reshaping the storage capacity demand and cost curves.
Storage managers often ‘short stroke’ higher capacity disk drives to minimize mechanical disk arm movement (seek time) activity by allocating only a fraction of the HDDs’ capacities (typically less than 20%) for performance sensitive data leaving the remainder of the drive capacity unallocated and unused.
If you limit capacity with short stroking, the minimum performance stays much closer to the maximum, and overall drive performance is increased but with the costly side-effect of significantly reduced capacity. For example, a short stroked 6TB disk drive might only use 1.2TB, leaving 4.8TB unused though it has been paid for and consumes floor space and energy. Judicious use of SSD supports high-performance application requirements while improving disk allocation efficiency.
The amount of live (actual) HDD data can be classified by a value ranging from mission-critical data to non-critical data and typical data allocation values are presented above. Based on the value of a given data set or file, the appropriate data protection techniques can be assigned to ensure the highest levels of availability.
HDD Challenge – Capacity Performance Conflict
The Measure of HDD Performance Capability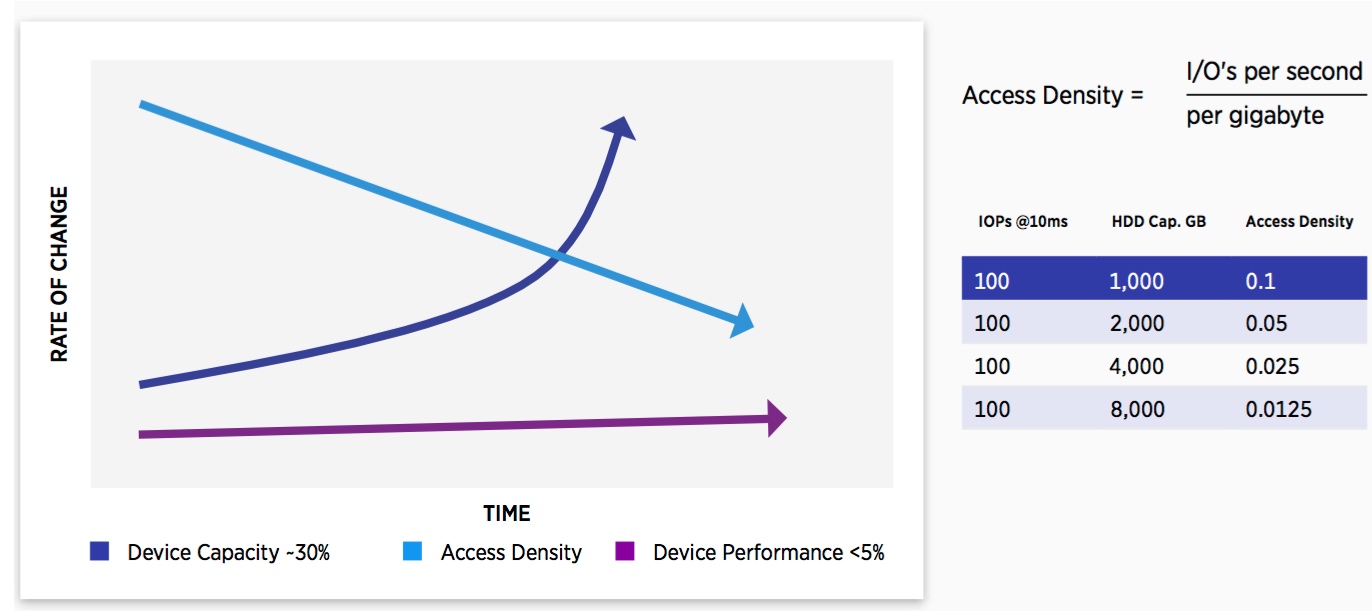
- HDD performance does not scale with capacity growth or server speed.
- Future HDD performance gains are minimal.
- SMR adds up to 25 percent capacity, but writes can be slower.
- Access density degrades response time – more actuator arm contention.
- Access density will continue to decline as HDD capacity increases.
- RAID rebuild times increase (n days) as HDD capacity increases.
- Creating more demand for high performance and hybrid disk category – SSD (tier 0).
The HDD industry is currently facing more challenges than at any time in its history and as a result, there is a fundamental shift underway within enterprise storage. At the core of the change is the fact that disks haven’t gotten much faster but they have gotten much larger. Drive capacity is increasing at 16% annually, but there are few if any rotational speed or seek time improvements on the horizon.
The key measure of disk drive performance is called Access Density and is the ratio of drive performance in IO/s to the capacity of the drive in gigabytes. Without any offsetting performance gains, drive capacity increases continue to reduce the access density and lowers effective performance and response time. These dynamics don’t appear to be changing in the foreseeable future. Declining access density trends have fueled the emergence of tier 0 memory class storage solutions to address higher performance data.
There is another factor associated with disk drives resulting from steadily increasing capacity and the result is a move away from high capacity HDD RAID arrays. Since the late 1980s, RAID has been used to protect against HDD failures. Rebuilding a RAID array depends on a whole disk’s worth of data being read from the remaining disks in the array.
The overall activity to the subsystem and the higher the HDD capacity, the longer the rebuild time and rebuilds can often take several days to complete. RAID rebuild times are critical, and growing concern for storage administrators as performance can be degraded during the rebuild period. Multiple failed drives in a subsystem can result in even longer rebuild times.
Tier 3 Storage
Tape Technology and Futures
Tape Storage Scenario
- Greater than 85% of tape drive shipments are LTO (over 100,000PB – 100EB – of LTO shipped).
- Tape drive reliability, data rate and capacity have surpassed disk.
- Tape capacities at 10TB native, greater than 25 TB compressed – tape has the highest capacity.
- Tape data rates at 360MB/s native.
- LTFS provides a universal, open file system for tape.
- Disk is gaining backup applications from tape via deduplication (HDD).
- Disk losing archive applications to tape – economics, reliability and media life.
- Greater than 70% of all digital data classified as tier 3 – archive and fixed content
- Clouds are embracing tape solutions for TCO and archival services.
The tape industry continues to gain momentum as tape has established its long-term role in effectively managing extreme data growth with new use cases. Both LTO and enterprise tape products continue to deliver unprecedented storage capacities per cartridge with the lowest TCO compared with all other existing storage solutions.
Steady developments have made tape technology the most reliable storage medium available, now surpassing HDDs by three orders of magnitude in reliability. Tape is well positioned to effectively address many data intensive industries including cloud, entertainment, the internet, business requirements to maintain access to data ‘forever’ along with applications such as big data, backup and recovery, archive, DR and compliance.
Remember that tape and disk best serve different storage requirements. Disk technology has been advancing, but surprising to many, tape’s progress over the last ten years has been even greater. Enterprise tape has reached an unprecedented 10TB native capacity per cartridge, 25TB compressed 2.5-1, with native data rates reaching 360MB/s.
Enterprise automated tape libraries can scale beyond one exayte marking the arrival of exascale storage solutions. Leveraging the new LTO-7 format, open systems users can now store the equivalent of up to 240 Blu-ray quality movies on a single 6TB native cartridge. In the future, an LTO-10 cartridge will hold the equivalent of up to 1,920 Blu-ray movies. Today’s modern tape products are nothing like their predecessors.
Tape Capacity Growth Accelerates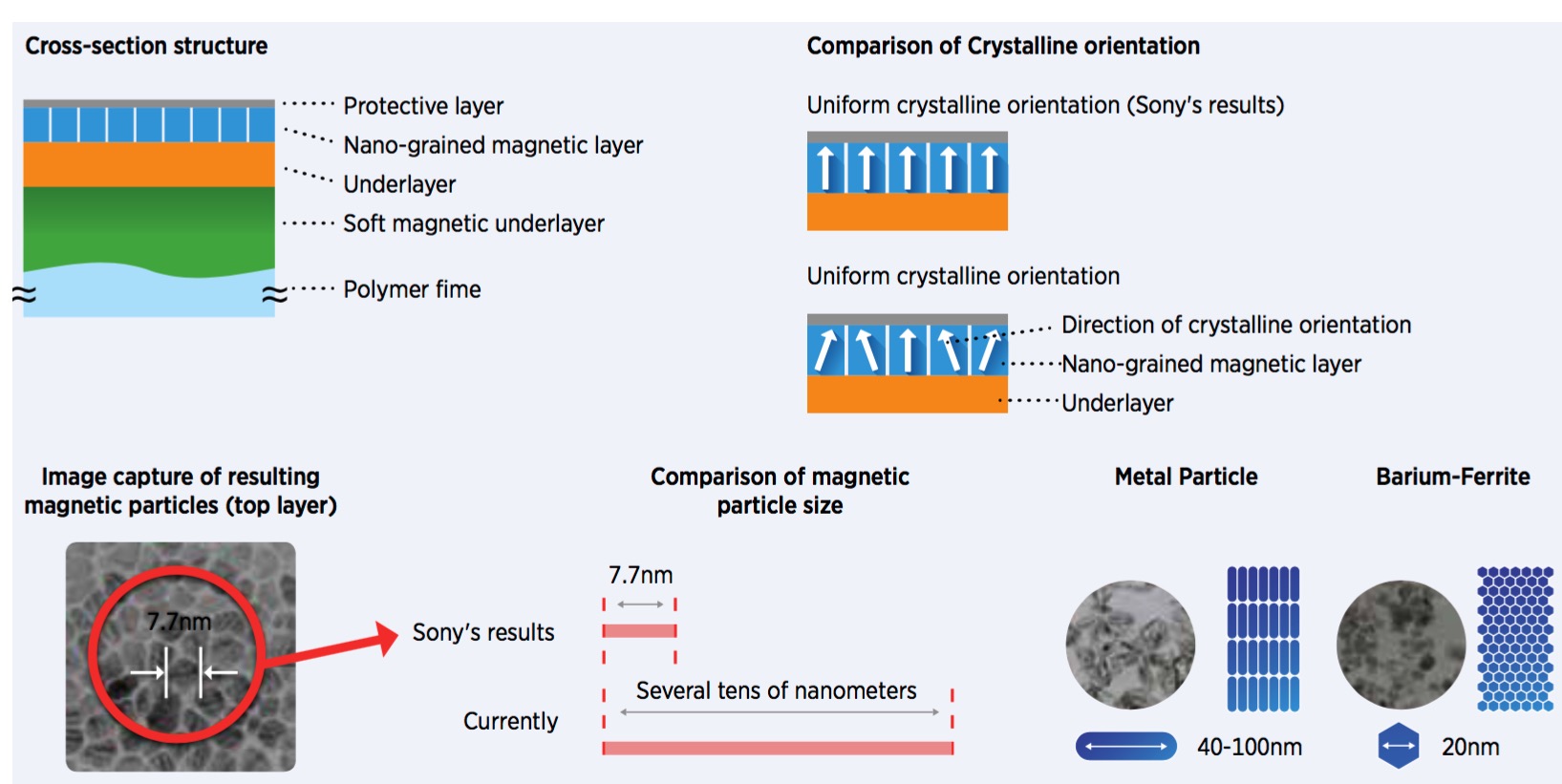
In April 30, 2014 – Sony Corporation announced a nano-grained magnetic layer with fine magnetic particles and uniform crystalline orientation for tape storage media with an areal density of 148 billion bits per in² and makes it possible to record more than 185TB of uncompressed capacity per data cartridge.
In April, 2015 Fuji Film Recording Media USA announced that in conjunction with IBM an areal density of 123 billion bits per in² on barium ferrite linear magnetic particulate tape had been achieved. This would yield a 220TB of uncompressed capacity on a standard LTO cartridge.
The INSIC Tape Technology Roadmap indicates it should be possible to continue scaling tape technology at historical rates for at least the next decade as tape is facing few, if any, capacity limits in the foreseeable future.
The INSIC roadmap indicates that tape’s areal density progress has been increasing about 33% in recent years and is projected to do so for the foreseeable future. Between 2003 and 2009, the areal density growth for HDD was about 35% per year. More recently, between 2009 and 2015, the rate of areal density HDD scaling has decreased to about 16% per year.
This slow-down in areal density scaling has been partially compensated for by an increase in the number of platters and heads in an HDD; however, the current rate of HDD capacity scaling is still much lower than historical rates. In contrast, the state of the art tape drives has areal densities that are more than two orders of magnitude smaller than the latest HDDs.
Therefore, it should be possible to continue scaling tape technology at historical rates for at least the next decade, before tape begins to face similar challenges related to the super-paramagnetic effect. Even though the areal density of tape is much lower than HDD, tape gets its capacity advantage over HDD by having a much larger recording surface in a cartridge, with about 1,000 times the area of a 3.5-inch disk platter, and subsequently does not need as high a recorded areal density to achieve its cost per gigabyte advantage.
Maintaining the historical scaling rate of tape of roughly doubling cartridge capacity every two years, enabling tape systems to continue and most likely increase their significant cost advantage over disk. Also, tape data rates are expected to increase by 22.5% while HDD performance rates are not projected to improve. Keep in mind that for any storage medium, increasing capacity without increasing performance – the access time and data rate – causes the access density to decline.
Tape Media Has Longest Archival Type
> 30 Years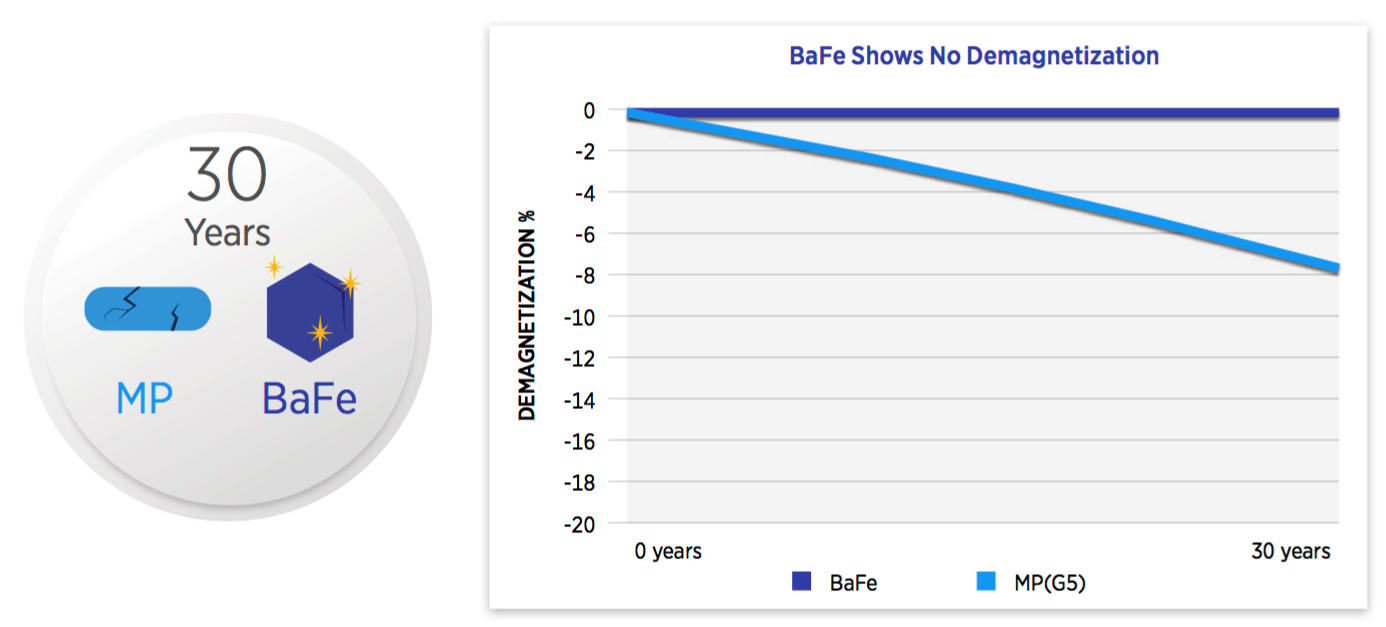
- Oxidation is major cause of MP (Magnetic Particle) deterioration with possible data loss.
- Barium ferrite is a new type of magnetic particle which can be greatly reduced in size to improve recording density without magnetic signal loss.
- However, BaFe media is already oxidized yielding a longer life compared to MP tape.
- MP shows slight degradation in magnetic signal over 30 years, although not
detrimental to read/write performance. Note: Average HDD lasts 4.1 years. - BaFe withstands realistic storage environment simulations and proves its reliability and stability over a 30 year time period.
- BaFe used for T10000, TS11xx and LTO media.
The answer to the question of “how long data written on tape can be read” has reached 30 years or more with the arrival of BaFe media pushing media life far beyond previous tape formats. Magnetic tape consists of tiny microscopic ‘magnetic particles’ uniformly dispersed and coated on the surface of the tape, and then small cells called a ‘bit cell’ are written on it.
For years, MP pigment was the primary tape media type. MP is mainly made of iron (Fe) therefore, it will eventually oxidize, and its magnetic property will deteriorate. To slow that down, the outer layer of MP is intentionally oxidized from the beginning. All previous generations of LTO cartridges before LTO-6 have used the MP pigment.
BaFe delivers greater storage capacity with lower noise and higher frequency characteristics than other metal particles. BaFe is made of an oxide. Therefore, it does not lose its magnetic property due to oxidation over time, and BaFe media life is rated at 30 years or more. Therefore, tape cartridges will most likely out-live the underlying drive technology and software systems that created it. Users should deploy a tape strategy that automates the movement of tape data from old technology to new technology with the understanding that most modern tape drives can read the new media and two prior media versions.
The typical tape drive can easily remain operational for 6-8 years before replacement because of this feature. BaFe tape has become the preferred recording technology for future tape generations since smaller particles will be required to achieve significantly higher cartridge capacities while providing the longest media life of any magnetic recording media.
Magnetic Tape Future Projections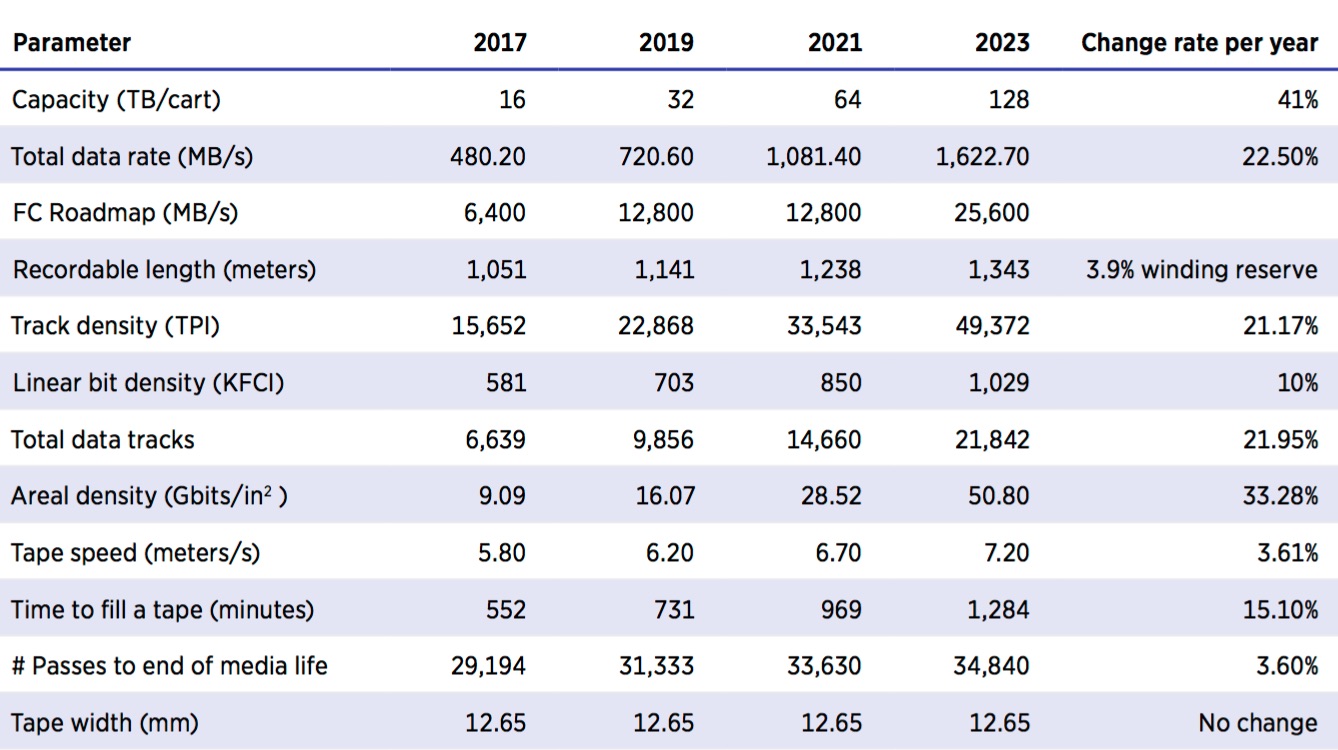
(Source: 2015 Information Storage Industry Consortium)
The future outlook for tape technology presents a compelling roadmap for substantial growth in the primary tape metrics. In particular, tape cartridge capacity is projected to grow over 40% annually while the data rate will double in the next six years. Other key parameters are listed above, and they portray a promising outlook for tape.
Tape storage features such as encryption, WORM, and LTFS, a universal open file system that partitions tape for facilitating file access, and active archiving all increase the attractiveness of tape for many new data intensive and long-term storage applications in addition to the traditional backup, recovery and DR roles.
Redundant Arrays of Inexpensive Tape (RAIT) concept has been around for nearly 20 years but is not yet a mainstream offering. This may soon change to take advantage tape’s fast streaming data rates and superior reliability. RAIT architecture is a HA, redundant array of tapes with both data striping and parity, and is analogous to RAID-3, -4, -5, or -6 for disk arrays.
RAIT is a way to aggregate physical storage volumes to create large virtual volumes while eliminating single points of failure and in some cases multiple points of failure in the underlying physical tape volumes.
RAIT also increases data transfer rates with data striping as the data path is spread over more channels. RAIT is most efficient for fast sequential writing and reading to tape. Because of the sequential nature of tape, writing is always sequential making RAIT efficient for a write-dominated archive. RAIT can also provide higher availability with fewer tape cartridges, as compared to mirroring, and offers much faster tape system throughput.
Tape Architecture Directions
- LTFS – Tape’s functionality and ease of use is greatly enhanced with LTFS.
- Capacity – Tape cartridge capacity currently at 10TB native and 25TB compressed.
- Reliability – Tape drive reliability (1×10**19) has surpassed disk drive reliability (1×10**16).
- Energy – Tape requires significantly less energy consumption than any other digital storage technology.
- Media Life – Tape media life at 30 years or more for enterprise and LTO.
- TCO – Tape storage has a lower acquisition cost and the TCO is typically around 15 times lower than disk.
LTFS was announced in the year 2010, and the long-standing rules of tape access were at last changed as the traditional longer, sequential search times for tape have given way to more disk-like access using familiar drag and drop techniques.
The LTFS partitioning capability first made available with the LTO-5 format, positions tape to improve data access by enabling tagging of files with descriptive text, allowing for faster and more intuitive searches of cartridge and library content.
Tape is benefiting from substantial development and manufacturing investment in the tape library, drive, media and file management software, and is adequately addressing the constant demand for improved reliability, higher capacity, power efficiency, and the lowest purchase cost-per-gigabyte and TCO of any storage solution.
Tape reliability has reached a Bit Error Rate (BER) of 1×10**19 making it higher than all other storage mediums. IT executives and cloud service providers are addressing new applications and services that leverage tape to derive significant operational and economic advantages.
With the exciting trajectory for future tape technology, many data-intensive industries and applications already have or will begin to benefit from tape’s continued progress. Clearly the innovation, appealing value proposition, and new development activities demonstrate tape technology is not sitting still.
Tape has been shifting from its historical role as primarily a backup solution to addresses a much broader set of storage requirements specifically including data archive and DR services.
Several critical technologies are yielding numerous improvements including unprecedented cartridge capacity increases using BaFe media, vastly improved bit error rates compared to disk, much longer media life, and faster data transfer rates than any previous tape – or disk – technology.
Media life for all new LTO and enterprise tape now reaches 30 years or more making tape the most highly secure, long-term digital archive storage medium available. Today’s modern tape technology is nothing like the tape of the past, expect tape-based solutions to address a much wider variety of applications in the future.
Cloud Storage Goes Mainstream
Cloud Services Driving Demand for Tape
Cloud Computing – Hybrid, Private and Public Clouds:
Method of delivering computing applications over the public Web 2.0 and potentially over private intranets as well.
- Moves compute cycles and storage problems somewhere else.
- The cloud is not for everyone!
Key challenges:
- 1. Security
- 2. Standards
- 3. Readily available data
Cloud Storage – Tape In The Cloud Has Arrived:
- Enterprise tape and LTO with LTFS is a key enablers for cloud.
- Tape cartridge capacity growing at unprecedented rates.
- TCO and raw hardware costs favor tape over disk (4-15 times).
- Optimal for archives, fixed content, compliance, streaming media, records.
- rojected around 100% annual growth for cloud storage and services in next 5 years.
“New tape capabilities are improving the economic model for cloud archiving.”
Given all the technology forces shaping the data center, none is having more impact than cloud computing. Today cloud is a mainstream architecture due in large part to the growing recognition of its role as a powerful business enabler for mobile and social business, analytics and innovation. Cloud computing, when used for storage services, is called ‘cloud storage.’
Cloud storage has gained traction for its easy and low-cost storage solutions. It saves data to an off-site storage system hosted by a third party in the case of a public cloud or hosted for a single organization in the event of a private cloud. Major cloud providers realize the cost-effectiveness of implementing tape in their cloud infrastructure as the total amount of data is escalating and storing less active data exclusively on HDDs becomes increasingly costly.
IDC indicates that cloud IT infrastructure growth outpaced the growth of the overall IT infrastructure market and grew by 25% in the past year. Cloud storage platforms have made slight gains in the overall storage market, accounting for an estimated 4.7% of total storage capacity shipped in the year 2015.
According to Statista, by the year 2016, cloud storage industry revenue is expected to be approximately $4.04 billion. By the year 2020, over one-third of all data is expected to reside in or pass through the cloud. More than 70% of businesses and IT professionals have already implemented cloud storage systems or plan to in the near future. What will you put in the cloud?
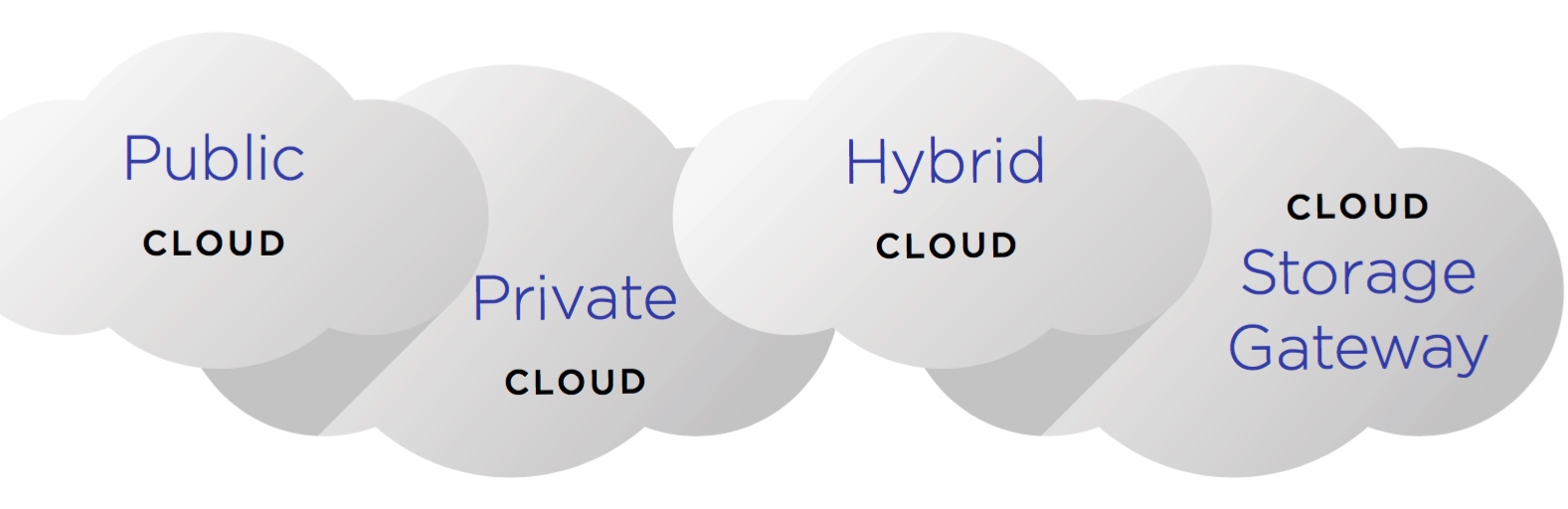
Key Cloud Definitions
Cloud computing consists of hardware and software resources made available on the Internet as managed third-party services. These services rely on advanced software applications and high-end networks of server computers. Generally, cloud computing systems are designed to support a large number of concurrent customers and unpredictable surges in demand. Bandwidth remains very expensive and can be a major consideration for using cloud services if the activity gets too high.
Public clouds are owned and operated by companies that offer access to a public network to affordable computing and provide storage resources to many organizations (multi-tenancy). With public cloud services, users don’t need to purchase hardware, software or supporting infrastructure, which is owned and managed by cloud providers. Public clouds are popular for unstructured data applications and with businesses that don’t want to be in the IT business.
A private cloud is an infrastructure operated solely for a single organization, whether managed by the internal staff or by a third-party and hosted either internally or externally. Private clouds are the most frequently used cloud option and are best suited for users who prefer customization and want to take advantage of cloud’s economic efficiencies while providing more control of resources and steering clear of multi-tenancy.
A hybrid cloud uses a private cloud foundation combined with the use of public cloud services. It includes at least one private cloud and one public cloud infrastructure. For example, an organization could store actively used and structured data (databases) in a private cloud for better performance and unstructured and archival data in a public cloud. The reality is a private cloud can’t exist in isolation from the rest of a company’s IT resources and the public cloud. Many enterprises with private clouds will evolve to manage workloads across data centers using private clouds and public clouds thereby creating hybrid clouds.
Cloud storage gateways are an appliance on the customer premise that serves as a bridge between local applications and remote cloud-based storage that addresses the incompatibility between the protocols used for public cloud technologies and legacy storage systems. The gateway can make cloud storage appear to be a NAS filer, a block storage array, a backup target or even an extension of the application itself. Most public cloud providers now rely on Internet protocols, often a RESTful API over HTTP, rather than conventional SAN or NAS protocols. Many of today’s cloud storage gateway products provide data reduction techniques such as compression and deduplication which make the use of expensive bandwidth more cost-effective and can move data as quickly as possible.
Cloud Storage Requirements
Private, Public or Hybrid
Increasing Expectations for Cloud Storage
- Archive and DR clouds emerging – the cloud tier.
- Massively scalable storage that scales, analyzes, adapts, and improves performance.
Best Practices Enable Cloud Storage Efficiency
- Allocation on demand.
- Real-time Compression, deduplication – up to 80% less space.
- Tier 3 (tape) for archiving in the cloud yields 4-15 times lower TCO than HDD.
- Thin provisioning for HDD yields up to 35% more utilization.
Data Protection/Security/HA in the Cloud
- Secure multi-tenancy with encryption and WORM.
- Remote mirror, remote vaults, geographically dispersed cloud sites.
- File replication and file level snapshots for business continuity and DR.
Data Management
- Support for unified SAN & NAS (block and file) and object storage.
- Support for NFS/CIFS/FTP/HTTPS file protocols.
- Policy-based management with user-defined policies to classify data.
- Active archive provides access time optimization.
Cloud Storage Systems
Scale to support billions of concurrent users. They provide data storage and retrieval that must be perpetually protected, resistant to denial of service, and able to withstand wide-scale disasters anywhere and anytime.
Key challenge – security!
The chart above highlights many common cloud requirements. More and more companies are looking to the cloud to resolve growing storage needs where a company’s data is stored and accessible from multiple distributed and connected resources. Storage is playing a vital role by enabling the arrival of ‘the high-performance cloud and the archive cloud.’ Using the cloud to store performance sensitive files is not yet realistic due to latency and bandwidth speed limitations. On-premise tier 0 and tier 1 transactional applications with heavy IO/s traffic remain a future challenge and growth opportunity for cloud services.
The preferred cloud storage solution should be able to scale to accommodate additional storage capacity on-demand and be able to do so using a policy-based, user-transparent system. For example, a policy could be set to allocate storage once latency reaches a certain point or throughput requirements change. Security has historically been the key challenge for using cloud services.
While a public cloud is shared by multiple customers called multi-tenancy, a company’s data should only be visible to, or accessed only by those who own the data. Access to this data can be ensured in many ways, primarily through encryption, and confirming that only the customer holds the encryption key for that data set.
Another requirement is that the data stored on a cloud isn’t tied to a specific, physical location. Instead, cloud data is dispersed in such a way that even if a company is physically located on the East coast, with information stored at multiple locations thousands of miles apart across the United States, the user should not feel any effect. Cloud users need to be able to move and access files and objects with an expected response time based on SLAs. If one data center is down, users should still be able to access their data without impact.
Cloud and Archive Applications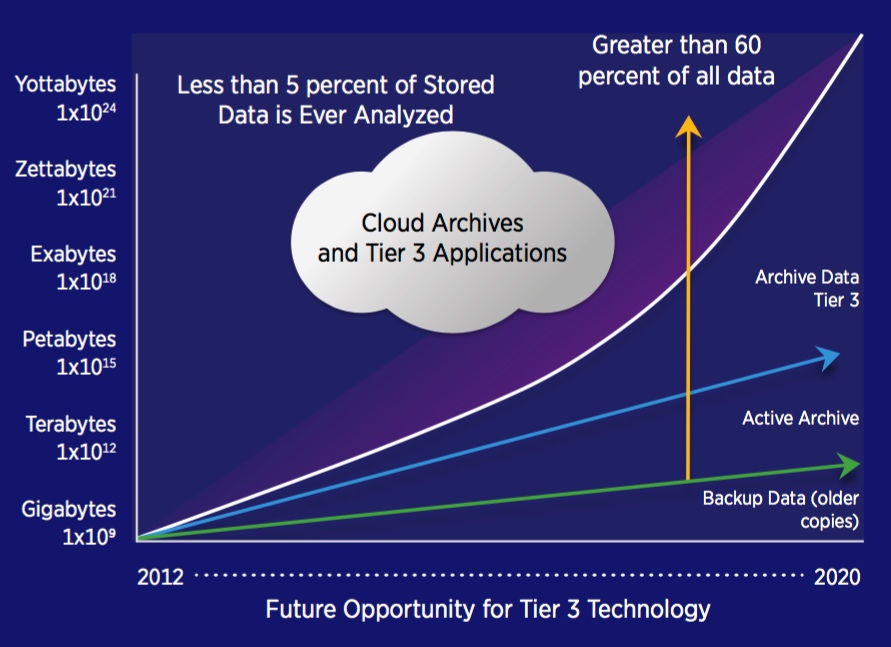
Tier 3 Applications
- Digital Assets – Big Data Apps
- E-mail and database archives
- Compliance, E-discovery
- Financial transactions
- Insurance claims
- Web content, images, photos
- Social networking explosion
- Documents, printed materials
- Rich Media (3-dimensional)
- Scientific, geophysical, geospatial
- Games, music, movies, shopping,
Entertainment, audio and video - Medical images (3D MRIs, CAT scans, X-rays)
- Surveillance, forensics
- Exascale architectures required
A growing list of global compliance, government, and legal regulations now describe the way data should be managed, protected and how long it should be stored throughout its lifetime extending the need to archive data for indefinite periods of time. With the right middleware, a cloud computing system could execute all the programs a standard computer could run and store much of the required data. Potentially, everything from generic word processing software to customized computer programs designed for a particular company could eventually work on a cloud computing system.
Many of these applications require significant bandwidth. Pushing terabytes of data into the cloud requires plenty of fast data pipes. Some cloud providers don’t care how much bandwidth you use while other vendors charge you based on bandwidth consumption. Bandwidth considerations can become a primary factor for moving specific files and performance sensitive applications to a cloud infrastructure. Always understand the rate structure from the cloud services provider.
In any case, the number of applications suitable for cloud computing is growing. The combined deployment of HDDs and tape are making the cloud a cost-effective repository for large-scale archiving applications that ensure long-term accessibility, preservation, and security. Also, the rapid growth in business and big data analytics is continually increasing the value of archival data, further pushing the security, size bandwidth, and management requirements of the digital archive.
Advantages of Cloud Storage
- Archive, Backup, and Recovery: The greatest benefit of storing archive data in the cloud is that it reduces the higher cost of storing lower activity data on primary storage, or on premises, and reducing the backup window by not backing up unchanged archival data.
- Automatic Software Integration: Cloud computing services allow you to customize your options and select exactly the services and software applications that will address your needs.
- Cost Efficiency: Cloud computing can be more cost efficient to use and maintain than upgrading hardware and software as incurring licensing and maintenance fees can prove to become very expensive.
- Easy Access to Information: Once you register yourself in the cloud, you can access the information from anywhere there is an Internet connection allowing you move beyond time zone and geographic issues.
- Nearly Unlimited Storage: Storing information in the cloud provides almost unlimited storage capacity. This means no more need to worry about running out of physical storage capacity, floor space, or increasing your current storage space availability and LUN management.
- Quick Resource Deployment: Cloud computing gives you the advantage of quickly deploying resources meaning users can have an entire system fully functional in a few minutes.
Disadvantages of Cloud Storage
- Access Time and Performance: While storage capacity almost doubles every year, networking speed grows by a factor of ten about every ten years or 100 times slower. The net result is that storage demand quickly outgrows network capacity, and it still takes a very long time to move significant amounts of data in and out of a cloud network. Today’s network performance is not acceptable for using the cloud for performance sensitive applications.
- External Hacker Attacks: Storing information in the cloud could make your company more vulnerable to external hack attacks and threats.
- Security in the Cloud: Before adopting cloud technology, realize that you will be surrendering your business’s sensitive information to a third-party cloud service provider potentially putting your business at risk. Joint-tenancy makes a public cloud more appealing to hackers. Choose a reliable and established service provider, who will contractually agree to keep your information totally secure.
- Technical Issues: Cloud technology can be prone to outages and specifically network and connectivity problems.
Cloud Becoming a New Storage Option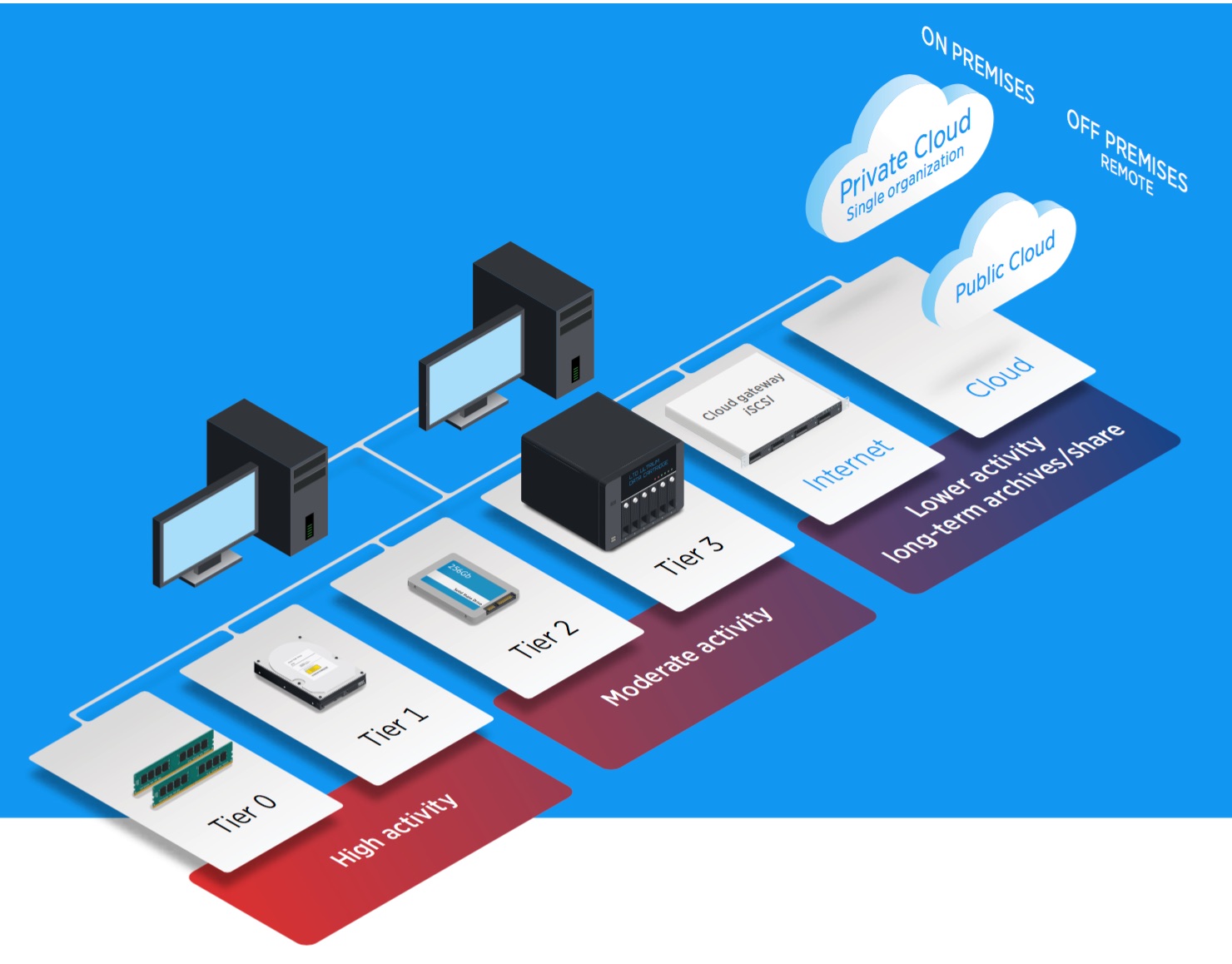
The cloud is adding many new capabilities and as a result is emerging as a new storage tier. HDDs were the first storage media used by cloud storage providers, but tape is complementing HDDs by becoming the most viable and lowest cost cloud archive solution. The reliability and long media life of tape, coupled with encryption, enables customers to store archival data securely in the cloud for indefinite time periods.
The consolidation of both HDDs and tape into a tiered cloud storage solution signals that cloud storage offers the potential to vastly improve the economic model for any long-term storage and archival services. For example, many of today’s popular office applications generate the majority of all business data and this data quickly ages, resulting in vast stores of lower activity data.
Storing archival data on tape in the cloud represents a significant growth opportunity for cloud and tape providers by offering a lower cost, and more secure archive alternative than an HDD only cloud. With HDD, tape and SSDs (in the future) now available in the cloud, the arrival of the cloud with its tiered storage solutions is imminent.
Data Management
The Data Lifecycle Model
From Creation to End of Life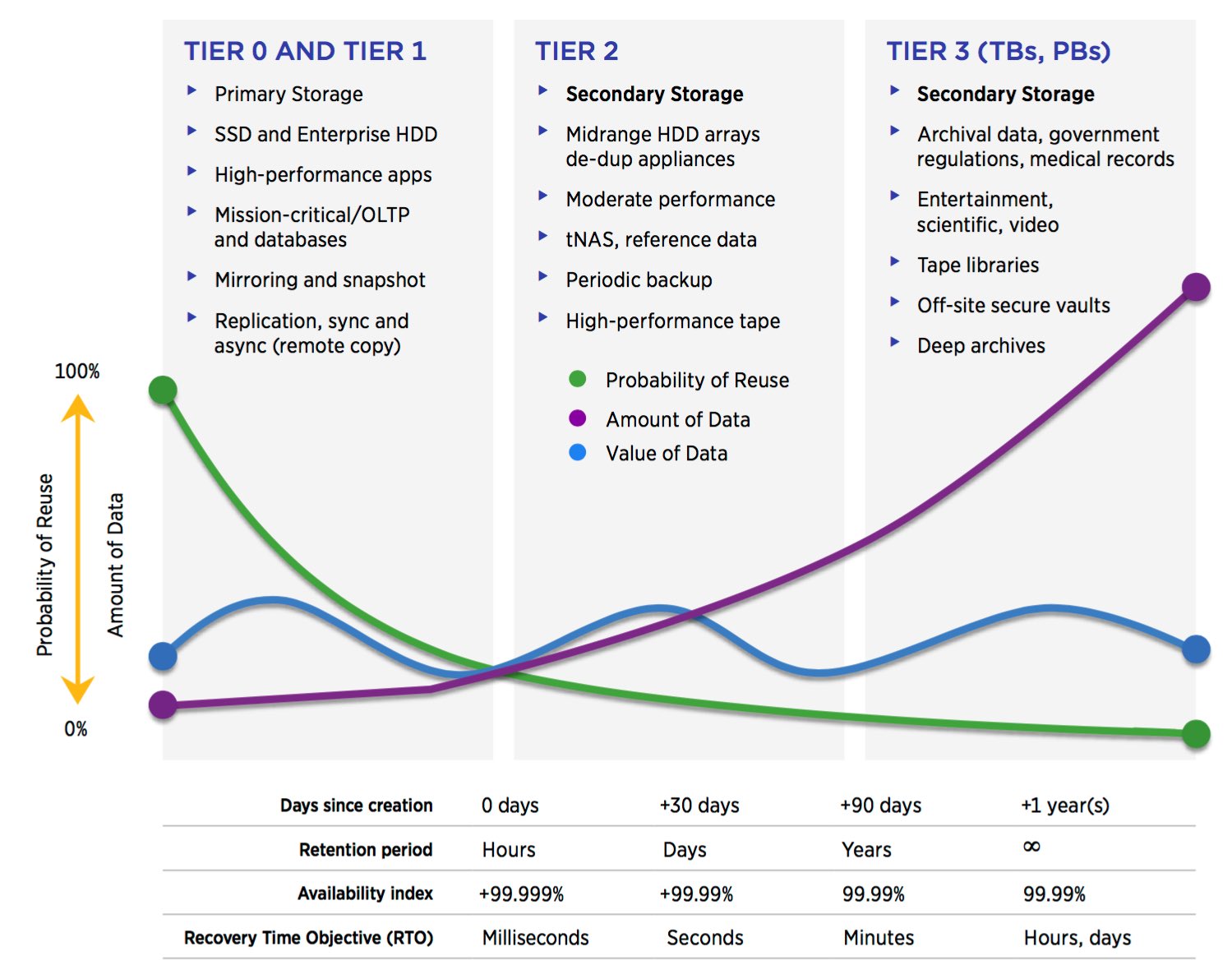
Data Lifecycle Management (DLM), also known as Information Lifecycle Management (ILM), is a policy-based approach to managing the flow of a system’s data throughout its life cycle: from creation and initial storage to the time when it becomes obsolete and is deleted.
DLM products automate the processes involved, typically organizing data into separate storage tiers according to specified user-defined policies, and automating data migration between tiers based on those criteria. In most cases newly created data, and more frequently accessed data, is stored on faster, but more expensive storage media while less critical and less active data is stored on lower cost, but slower media.
The storage hierarchy represents different types of storage media including SSDs, HDDs, and tape with each tier representing a different level of cost and speed of retrieval when access is needed. HSM software is the primary type of DLM product that moves data to and from its optimal location based on user-defined policies.
Using an HSM product as the active agent, an administrator can establish guidelines for how often different kinds of files should be moved to a more cost-effective tier in the storage hierarchy. Typically, HSM applications migrate data based on the length of time elapsed since it was last accessed and can use additional policies based on more complex criteria to optimize storage costs.
Capacity – Performance Profile
Planning for Tiered Storage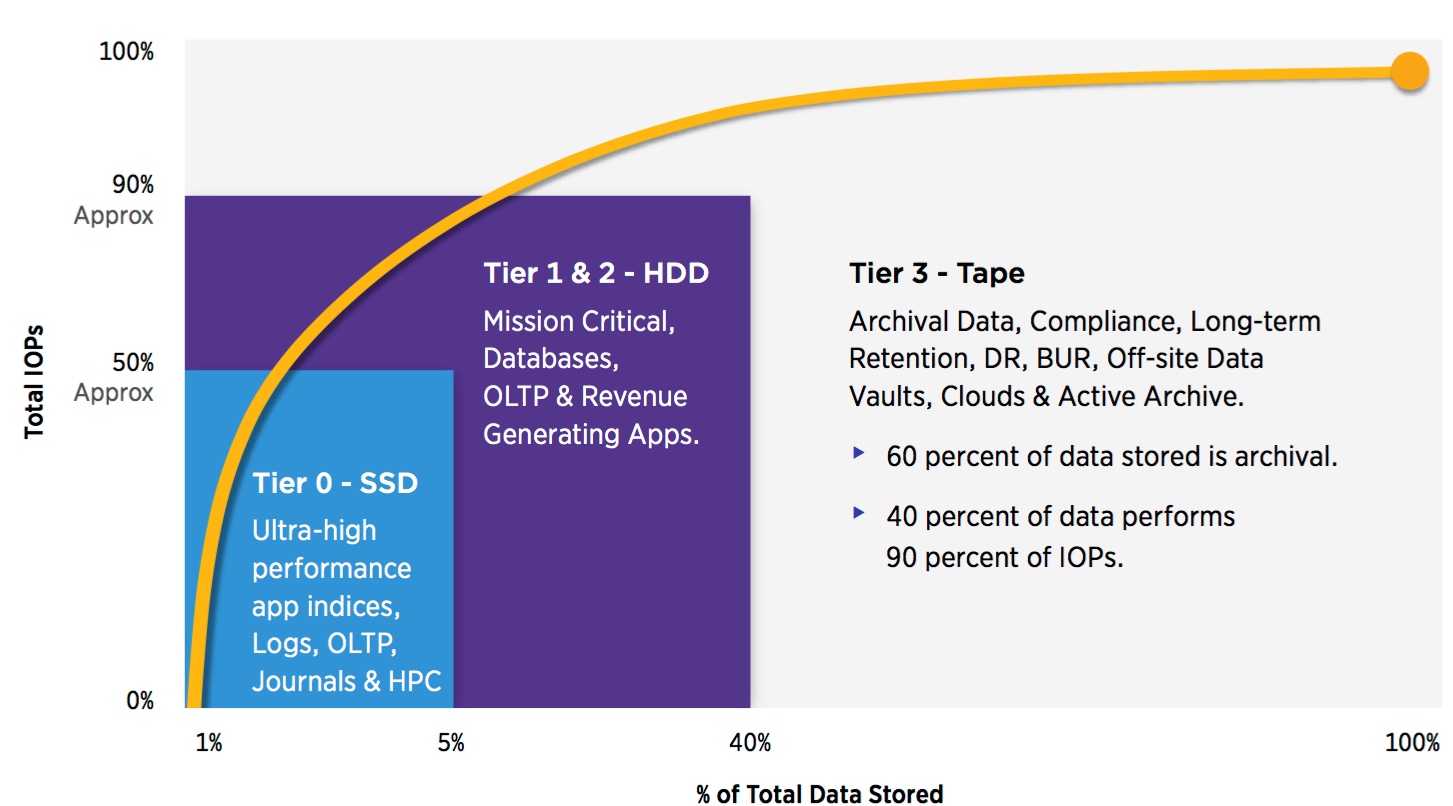
The capacity – performance profile has withstood the test of time for most all storage environments. The profile indicates that approximately 50% of the total IO/s goes to no more than 5% of the amount of stored data making it optimally suited for tier 0 SSD solutions. Approximately 35% of stored data generates another 40% of total IO/s and is optimally suited for tier 1 or tier 2 HDDs.
That leaves about 60% of stored data capacity generating just 10% of the total IO/s making that data optimally suited for tier 3 tape storage. It is this profile that establishes the criteria for implementing cost-effective storage using the tiered storage model.
TwinStrata, Inc. announced the results of its Industry Trends: 2014 State of Storage survey. The analysis reveals that the majority of organizations continue to use expensive primary storage systems to store infrequently accessed data – this is a strategy, just not a very cost-effective one.
The survey collected responses from 254 IT professionals
involved in storage strategy and revealed:
- Management of inactive data (unused data for six months or more) proved to be an area where the greatest improvements can be made.
- The majority of organizations estimate that at least half of all data stored is inactive.
- One-fifth of the people surveyed stated that at least 75% of their data is inactive.
- 81% of organizations who use SANs and NAS in their environment store inactive data on them.
- Three out of five organizations replace their disk storage systems within five years.
- When asked the top reasons for storage system replacement, growing capacity needs (54%), manufacturer end of life (49%), new technology (38%), and high maintenance costs (30%) were most cited.
Cost Reduction Using Tiered Storage
Optimize Data Placement – Move Archival Data Off of Disk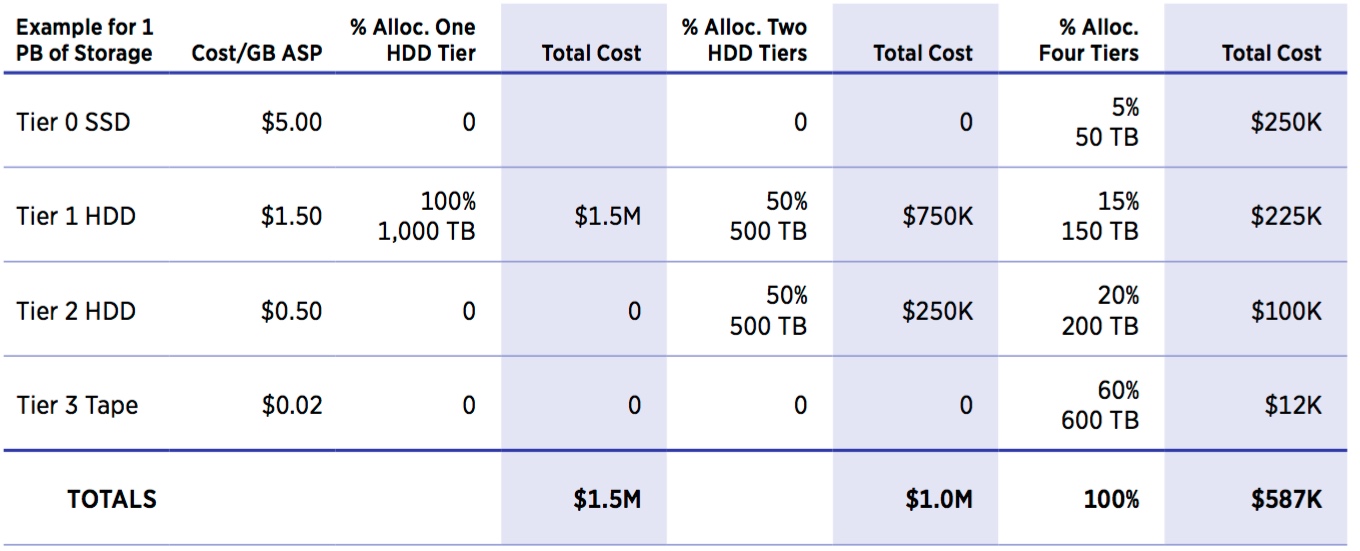
– Allocation Percentages Use Industry Average Data Distribution per Tier.
– Pricing Uses ASP (ASP/GB), Not List Price. Prices will vary greatly.
Data storage professionals are under constant pressure to efficiently and safely manage data that is being generated at an exponential rate while keeping costs as low as possible. While there are many data management solutions to choose from, organizations that have implemented a tiered storage strategy see significant cost savings. Implementing tiered storage can significantly reduce both acquisition costs and TCO. It is estimated that approximately 40% of data centers have implemented some form of tiered storage.
The model above compares the initial acquisition cost of 1PB of storage for a disk-only (all data on tier 1), a disk only (tier 1: 50% and tier 2: 50%) strategy, and a strategy using all four tiers. The prices used serve as examples only, and customers should use the latest price quotes from their storage supplier(s) as input to determine costs for any particular storage tier. The average amount of data in each tier uses the industry averages from the data classification model described earlier.
For 1PB of data, the acquisition price of a single tier 1 enterprise HDD strategy is $1.5 million and is 50% higher than a two-tiered HDD strategy at $1 million. A two-tiered, ‘put it all on HDD’ implementation is 1.7 times more expensive at $1,000,000 compared to $587,000 for a four-tiered implementation using SSD for tier 1 for high-performance data and tape for tier 3 archival.
Moving archival data from HDDs to tape is where the greatest tiered storage economic benefits come into play (the 5-year TCO for HDD is around 15 times higher than automated tape for archive data). Moving data from higher cost disk to lower cost disk without using tape has less benefit as a tiered strategy. Unfortunately, many enterprises continue to waste money storing their least important data on their most expensive systems.
Classify Your Data
Determine the Relative Importance of Your Data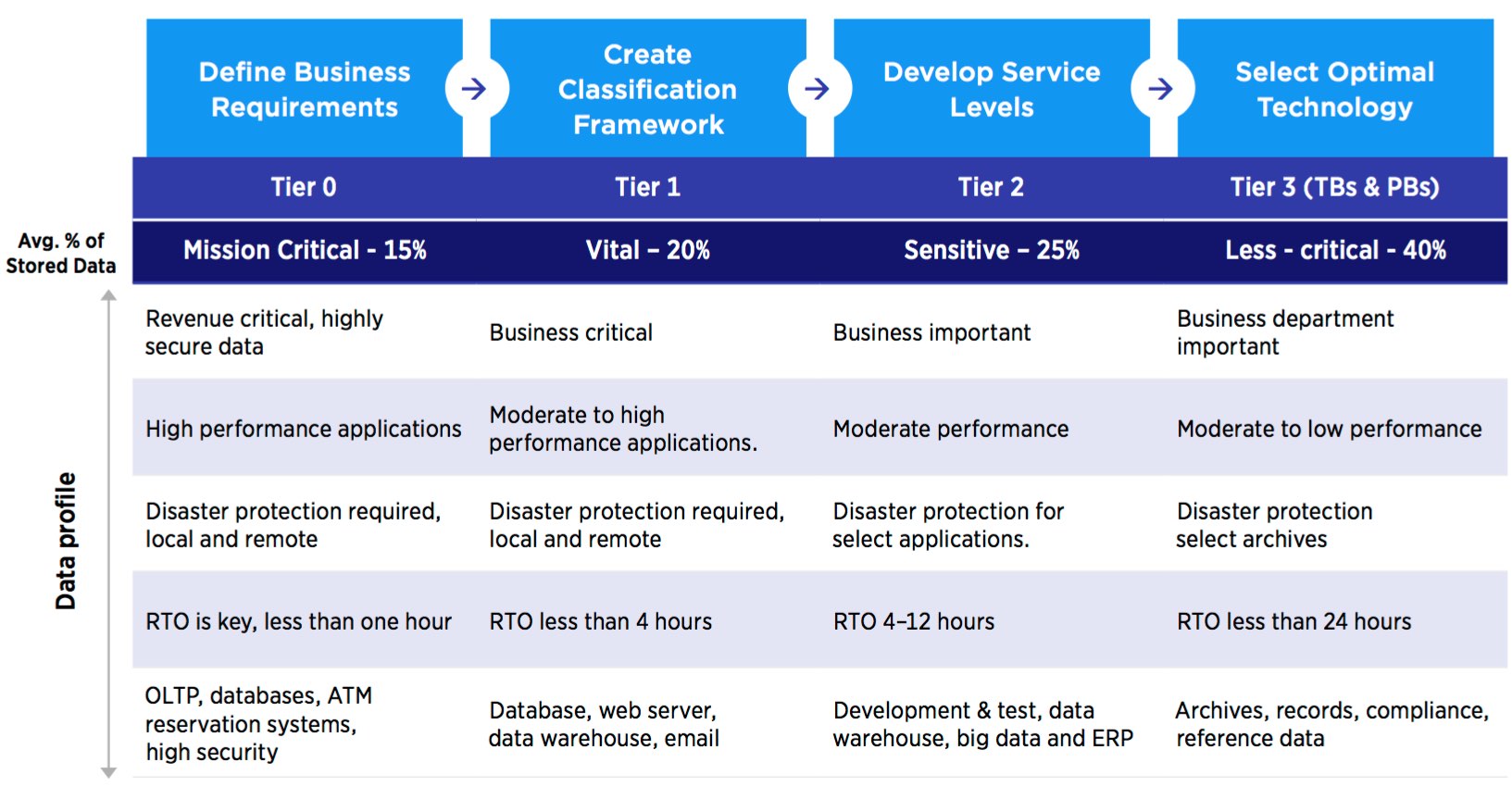
The cost savings with implementing a tiered storage strategy is evident when examining the example above. To keep costs at a minimum, tiered storage takes into account: price, performance, capacity and functionality for each data type located on each tier. Data that requires high performance and availability is optimally stored on more expensive, high-performance storage that requires more power.
Data that is not accessed as frequently is optimally stored on less expensive, lower activity storage that does not consume power. For many businesses, disk has been pressed into service as a long-term retention or deep archive platform despite the poorer economics of using disk in such a role.
To take advantage of the benefits of tiered storage, data must be classified according to the value at risk if it’s lost, and then placed on the appropriate storage tier to meet service level and availability requirements. Mission critical data deserves the highest levels of protection offered by storage systems including extra mirroring, replication, and careful management. Less-valuable data is far more abundant and doesn’t need the same level of protection.
Keep in mind that the value of data can change over time based on various circumstances. Today’s research into relatively inactive big storage could help discover tomorrow’s next super-hot product or medical breakthrough. In an optimized storage environment, the resources used to store and protect data are best aligned with its value by the data classification process.
The Data Classification Profile
Classifying data is a critical IT activity for implementing the optimal solution to store and protect data throughout its lifetime. Though you may de ne as many levels as you want, four de facto standard levels of classifying data are commonly used: mission-critical data, vital data, sensitive data and non-critical data. Determining criticality and retention levels also determine which data protection technology is best suited to meet the RTO requirements.
Defining policies to map application requirements to storage tiers has historically been time-consuming, but has improved considerably with the help of several advanced classification and HSM software management solutions from a variety of companies. When classifying data, keep in mind that data is not all created equal.
Mission-critical
Mission-critical data is defined as the most critical business processes, revenue generating or customer facing applications and can average 15% or more of all stored data. Mission-critical applications normally have a RTO requirement of a few minutes or less to resume business quickly after a disruption. Losing access to mission-critical data means a rapid loss of revenue, potential loss of customers and can place the survival of the business at risk in a relatively short period of time. Ideally, mission-critical data resides on highly functional, highly available enterprise tier 1 disk arrays or tier 0 SSDs and require multiple backup copies that are often stored at geographically separate locations to ensure security.
Vital
Vital data typically averages up to 20% of all stored data; however, vital data doesn’t require ‘instantaneous’ recovery for the business to remain in operation. Data recovery times, the RTO ranging from a few minutes to a few hours or more, are typically acceptable. Vital data is critical to the business and often resides on tier 1 or tier 2 disk arrays.
Sensitive
Sensitive data can average 25% of all data stored online and is important but doesn’t require immediate recovery capabilities. The RTO can take up to several hours without causing a significant operational impact. With sensitive data, alternative sources exist for accessing or reconstructing the data in case of permanent data loss. Sensitive data typically resides on lower-cost tier 2 disk arrays, tier 3 automated tape libraries, and active archive solutions.
Less-critical
Less-critical data often represents 40% or more of all digital data, making it the largest and the fastest growing data classification level. Lost, corrupted or damaged data can be reconstructed with less sophisticated recovery techniques requiring minimal effort, and acceptable recovery times can range from hours to days since this data is usually not critical for immediate business survival. Less-critical assets such as archives may suddenly become highly valuable – and more critical – based on unknown circumstances. E-mail archives, legal records, medical information, entertainment, unstructured data, historical data and scientific recordings often fit this profile, and this category typically provides much of the large-scale content driving big data analytics. Less-critical data is most cost-effectively stored on tier 3 tape. Remember that less-critical data doesn’t mean it isn’t valuable!
Improving Storage Efficiency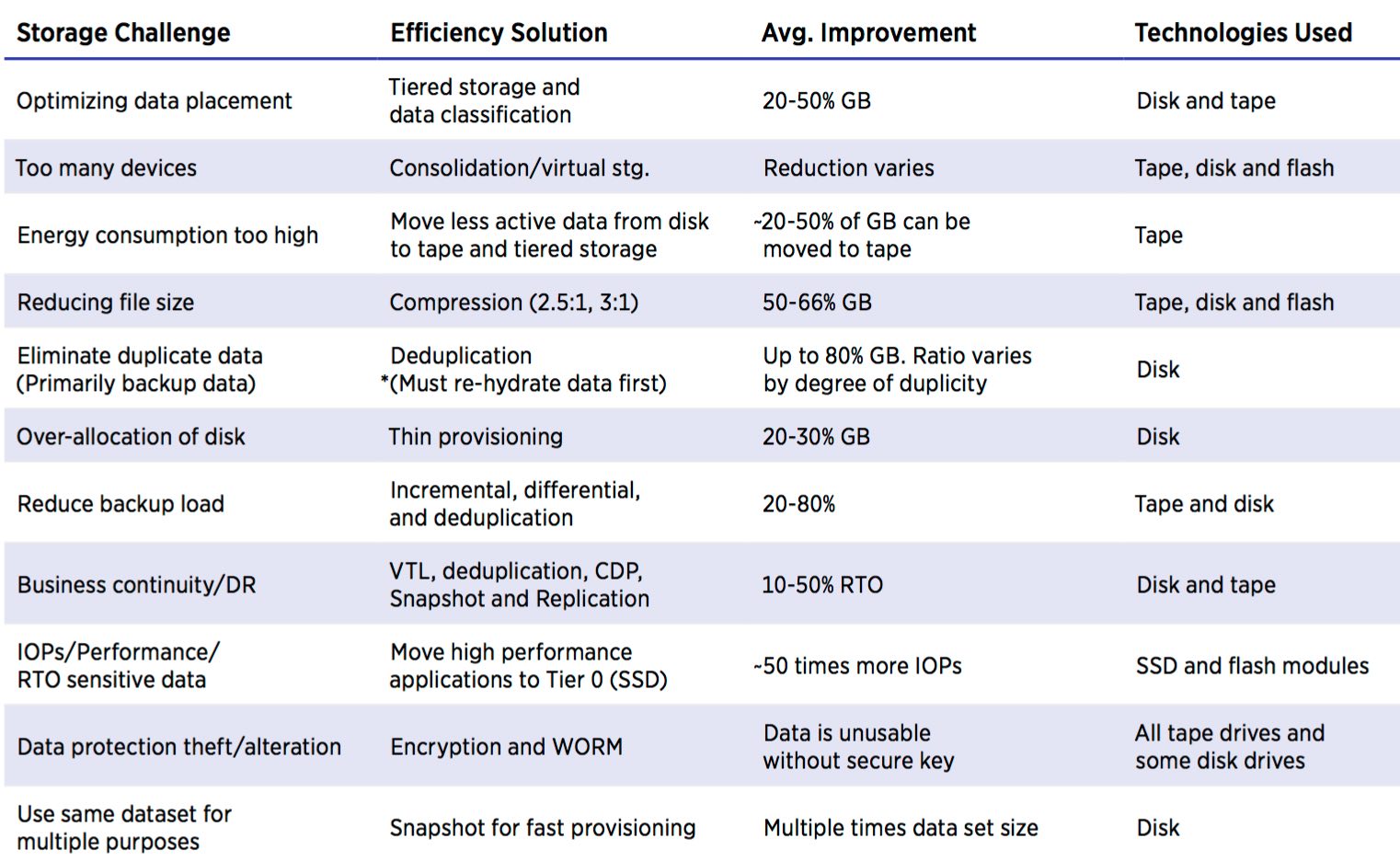
There are numerous technologies listed in the table above show solutions that storage administrators can implement to improve storage efficiency significantly. Storage efficiency is the ability to store and manage data that consumes the least amount of space with little to no impact on performance; resulting in a lower total operational cost. Storage efficiency addresses the real-world demands of managing costs, reducing complexity and limiting risk. The Storage Industry Networking Association (SNIA) defines storage efficiency in the SNIA Dictionary as follows: Storage efficiency=(effective capacity+free capacity)/raw capacity
The efficiency of an average open systems disk system is typically in the 60% range, depending on what combination of RAID, mirroring, and other data protection technologies are deployed, and is often lower for highly redundant remotely mirrored systems. As data is stored, technologies such as deduplication and compression store data at a greater than 1-to-1 data size-to-space consumed ratio and efficiency can rise to over 100% for primary data and even thousands of percent for backup data.
Thin provisioning allows administrators to virtually dedicate the amount of storage the application requires but allocates storage to the application only when it writes data, so it uses only the capacity it needs. The remaining storage is held in a pool for other purposes. Today’s most efficient storage systems integrate SSDs, HDDs, modern tape, compression, thin provisioning, load balancing, and deduplication with numerous software and virtualization capabilities to manage the data explosion and reduce complexity.
Average Petabytes Managed Per Storage Administrator
Survey by Oracle in 2015 of 49 customers
On average, how much storage does an administrator manage?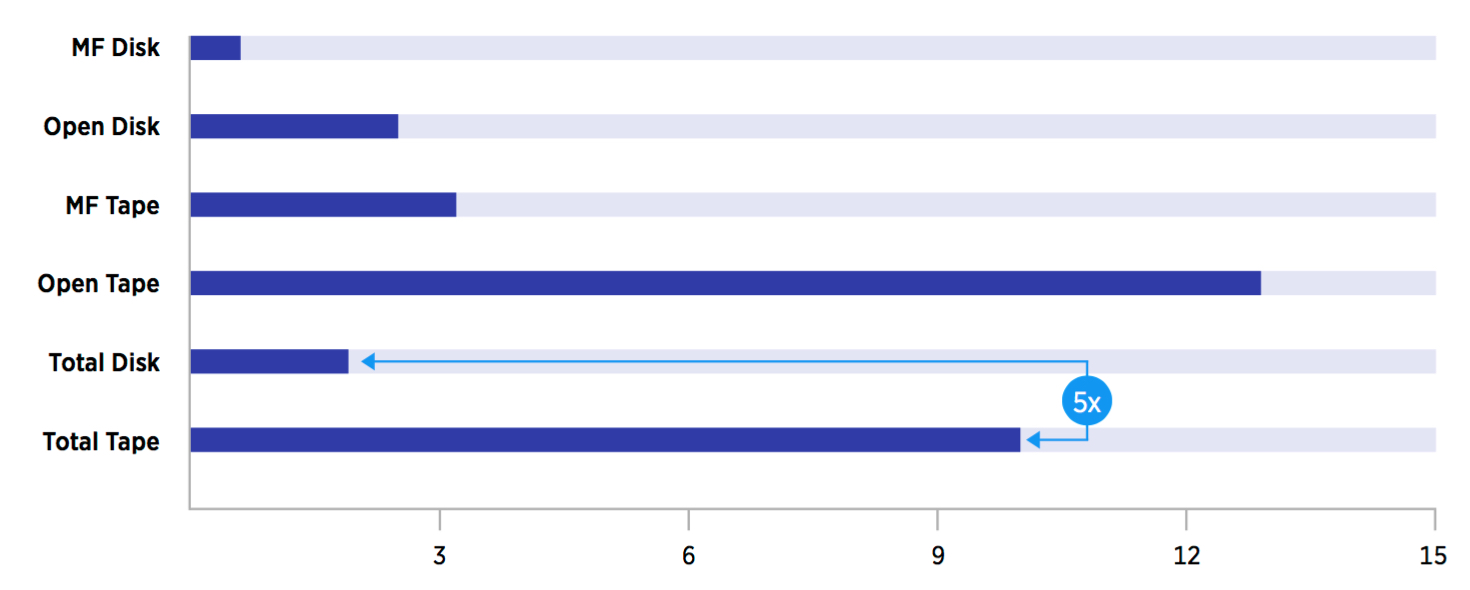
Determining the average number of petabytes that are managed by a storage administrator is difficult to determine and has been subject to discussion for many years. Oracle conducted a survey of 49 installations in 2015 that provided some further insight into this question. The survey was conducted for mainframe sites (15) and open system sites (34) to determine the average number of petabytes managed per storage administrator for disk and tape.
Though not a statistically large sample, the study revealed that tape administrators can manage about five times the storage capacity that disk administrators can manage for both the mainframe and open environments, making tape about five times more labor efficient. Labor costs can be a significant TCO component. The survey didn’t identify the differences for mainframe and open systems market. Clearly values vary by installation but in any case, the 21st-century storage administrator requires a very broad set of skills.
Key Storage Administrator Responsibilities
- Responsible for data integrity, security and systems performance.
- Manages availability of storage systems.
- Create, provision, LUN management, and add or remove storage.
- Create le systems from newly added storage and allocate them to the optimal storage tier.
- Install patches or upgrades to the storage hardware, firmware or software.
- Perform storage related troubleshooting tasks.
- Provide architecture as well as performance recommendations.
- Execute tests cross-site replication of significant DR processes.
- Tape administrators manage automated tape library contents, measure tape system performance, monitor media health, label cartridges for libraries, and handle physical tapes for import and export.
- Perform daily analysis of storage and backup infrastructure.
- Provide and analyze storage reports for end-users and internal management.
Storage Squeeze Play – HDD Caught in Middle
The Storage Landscape is Shifting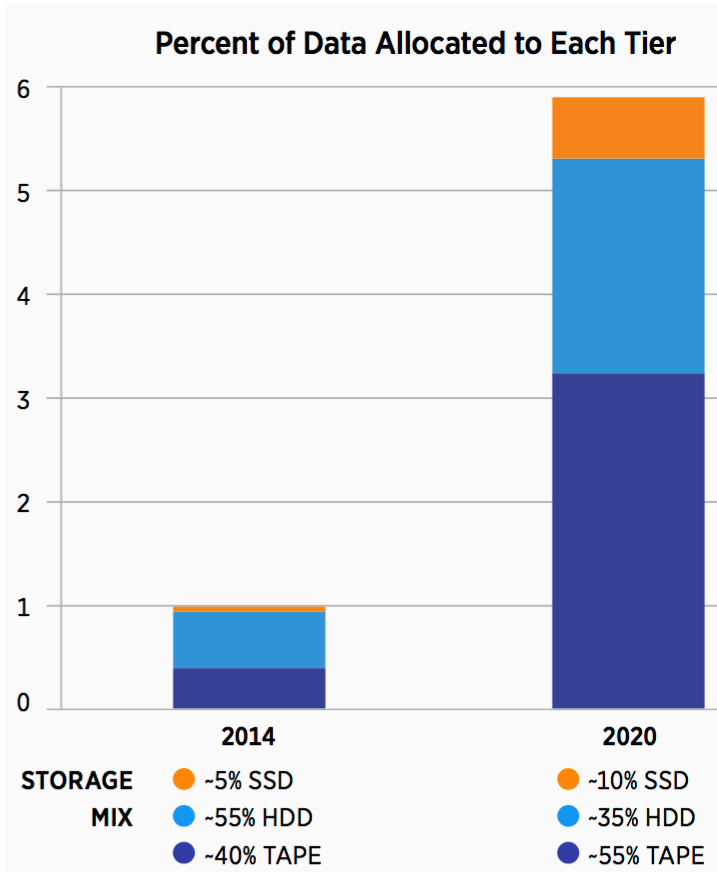
HDD Challenges Are Mounting
- Disk speed lagging server performance.
- Further disk performance gains minimal.
- Disk re-build times excessive (n days).
- Disk capacity gains facing limits.
- Disk adding platters to increase capacity.
- Disk TCO higher than tape (4-15 times).
- Poor utilization requires more HDDs.
- Disk data at rest main target for hackers.
- Tape reliability has surpassed disk.
- Tape capacity growing faster than disk.
- Tape is much greener than disk.
- LTFS enables ‘disk-like ’ access for tape.
- Tape media life now 30 years or more.
Old way: Keep adding more disk.
New way: Optimize using flash, disk and tape.
The shift in the traditional storage landscape is underway as high-performance data residing on HDDs finds its way onto flash SSD and lower activity, and archive HDD data migrate to modern tape. As a result, the amount of data stored on HDDs will continue to grow, but at a slower rate than in the past, facilitating a ‘storage squeeze play’ on HDDs. HDDs are increasing in capacity – but not in performance – as the IO/s capabilities for HDDs are not increasing.
This concern has fueled the rapid emergence of tier 0 SSD using flash memory to achieve higher performance levels. RAID rebuild times are becoming excessive as HDD capacities increase and now can take several days to rebuild a failed HDD. As HDD capacities continue to increase, the rebuilding process will eventually become prohibitive for most IT organizations forcing the HDD industry to implement new and more efficient data protection techniques such as erasure coding.
A common objective for many data centers today is that “if data is not used, it should not consume energy.” In response to this directive, the movement of lower activity archival data from energy consuming HDDs to more reliable, much more energy efficient and more cost-effective tape storage is well underway at the other end of the storage hierarchy. For the near term, HDDs will remain the home for primary storage, mission-critical data, OLTP, and databases.
Over the next five years, forecasts for capacity growth in the total amount of data stored on HDDs is expected to shift from 40-45% annually to 30%, below the 52% CAGR for tape and 71% CAGR for flash SSD. As a result, HDDs are caught in the middle as storage administrators strive to optimize their storage infrastructure by getting the right data in the right place – fortunately, the technologies are available to do so.
Data Protection and Security
Archive Retention Requirements
Signals Need for Advanced Long-term Archival Solutions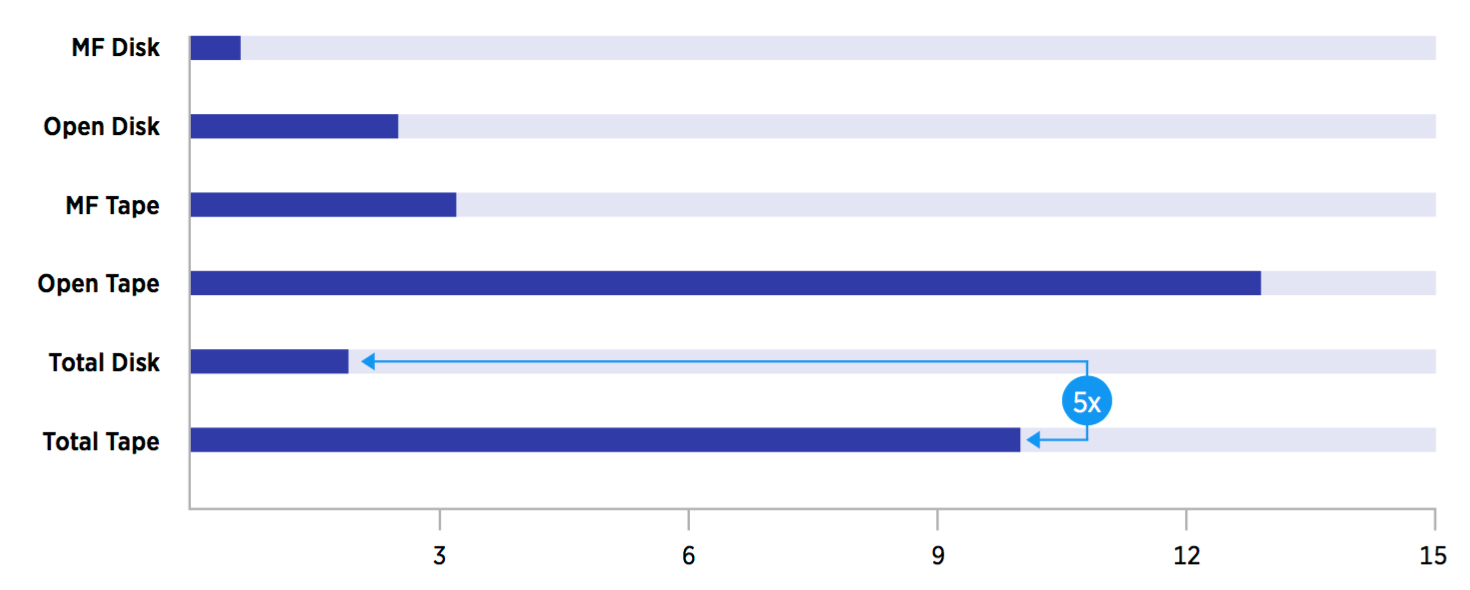
- Long-term archival storage requirements increasing.
- Greater than 20 years retention required by 70% of respondents.
- Greater than 50 years retention required by 57% of respondents.
Key Driving Factors
- Compliance
- Legal risk
- Business risk
- Security risk
Data archiving has become an essential practice for organizations. Data archiving is the process of moving data that is no longer actively used to a lower cost storage device for long-term retention. Archives contain primary source documents and older data that is still important to the organization and may be needed for future reference, as well as data that must be retained for extended periods of time for regulatory and compliance purposes.
The greatest benefits of archiving data are that it reduces the higher cost of storing lower activity data on primary storage and reducing the backup window by not backing unchanged archival data. Archive storage is optimally suited for tier 3 tape storage libraries, but low-cost HDDs are also used for archive data.
Data retention requirements can be highly variable, often determined on an application-by-application basis or by regulatory requirements and these may vary by industry or by each state. For example, organizations must manage the life of financial data – typically being retained for seven years at a minimum.
Medical data might be retained for the life of the patient plus seven years, and nuclear power data for 70 years. In the SNIA chart above, 38.8% of respondents cite data retention periods of over 100 years while 70% retain data for over 20 years. In reality, much of this data will seldom be accessed and never be deleted pushing up the storage requirements for tier 3 storage that must be managed, stored, protected and made available whenever it may be needed throughout its lifetime.
Benefits of Implementing an Archive Strategy
- Compliance: Preserving data to meet governmental requirements and avoid legal liability are fundamental reasons and requirements to implement a data archiving strategy.
- Improved Performance: By reducing the amount of data to manage, or by partitioning unused data from active data, organizations may see substantial improvement in system performance.
- Knowledge Retention: In an era of big data, organizations are learning the value of analyzing vast amounts of archived data. Here, the consideration isn’t cost, but the desire to gain a competitive edge in the marketplace by analyzing enormous and untapped data reserves.
- Less Media Conversion: By archiving to tape, the need to re-master large amounts of archive data to a new media format is less frequent than disk. Modern tape drives can read the current version and usually the two prior format versions making upgrades to a new tape technology less frequent and less labor intensive. The typical disk drive will last four-to-five years before replacement while the average tape drive will last eight years or more before replacement.
- Reduced Backup Window: Even with backup to disk using data compression and data deduplication, backup windows face constant pressure from data growth that often exceed a 40% CAGR. There’s no point in repeatedly backing up unchanged data. Archiving can remove terabytes or more of data from the backup set avoiding backing the same data repeatedly.
- Reduced Costs: Data archiving is largely an effort to preserve data securely and indefinitely while lowering costs – measured by a $/GB purchase price and TCO many vendors offer TCO analysis models. All models are expected to yield positive results, so the results are only meaningful if you agree with both the data input and the underlying premises of the TCO model.
When Does Data Reach Archival Status?
Most Archive Data is Worn – or Worse
WORN: Write Once, Read Never WORSE: Write Once, Read Seldom if Ever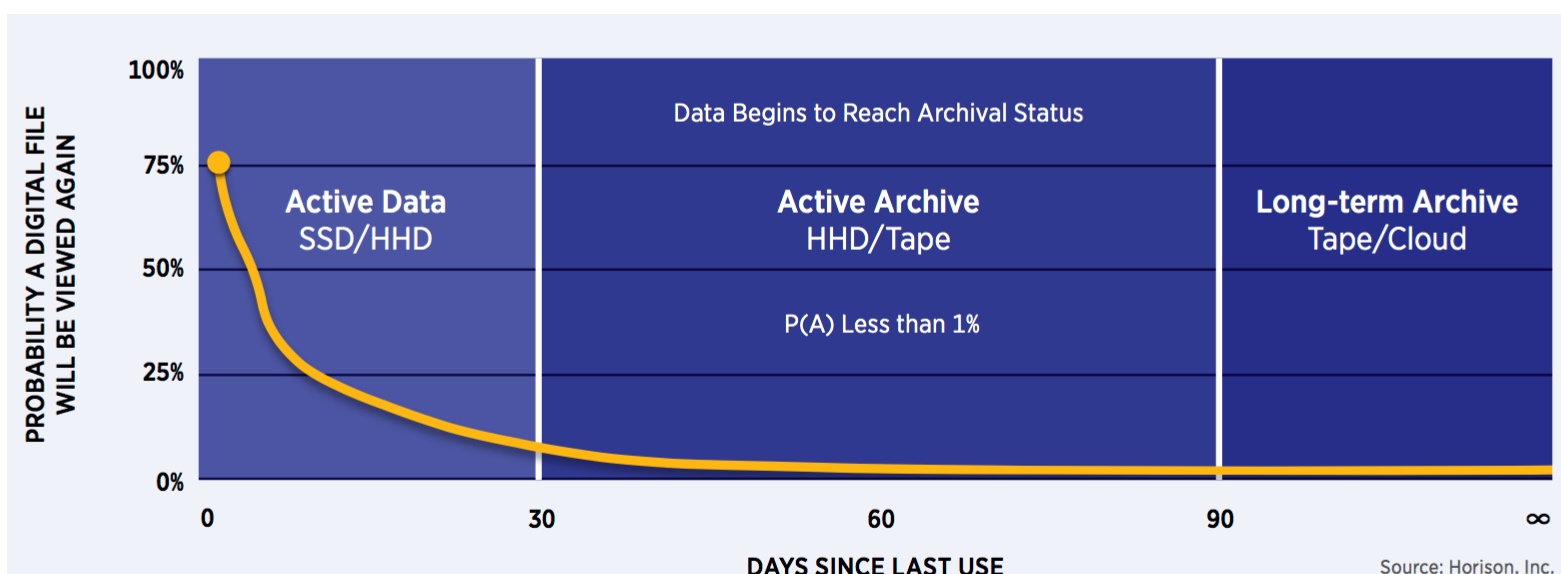
Many files begin to reach archival status after each file has aged for a month or more, or whenever the probability of access (PA) falls below 1%. The vast majority of data has reached the archival status in 60 days-or-less, and the archival data is accumulating even faster at over 50% compounded annually as many data types are kept indefinitely.
Archival data is commonly characterized by lower activity or reference levels with the requirement to preserve the data in its unaltered form, securely and indefinitely. Much of the data used for regulatory, scientific and big data analytics can be classified as archival until it is discovered and becomes more active as a result of the analytic process.
Organizations should establish the criteria for what types of data to archive based on internal policies, customer and business partner requirements, and rules for compliance. For most organizations, facing hundreds of terabytes or several petabytes of archive data for the first time can trigger a need to redesign their entire storage infrastructure and build a highly scalable and secure tier 3 strategy if one doesn’t exist.
Tape libraries and an ‘Archive Cloud’ provide today’s most cost-effective archive storage solutions. Archiving data is now a required storage discipline and is quickly becoming a critical ‘Best Practice’. Have you prepared to manage the tremendous growth of archival data that lies ahead?
The Active Archive
Redefining the Archive Experience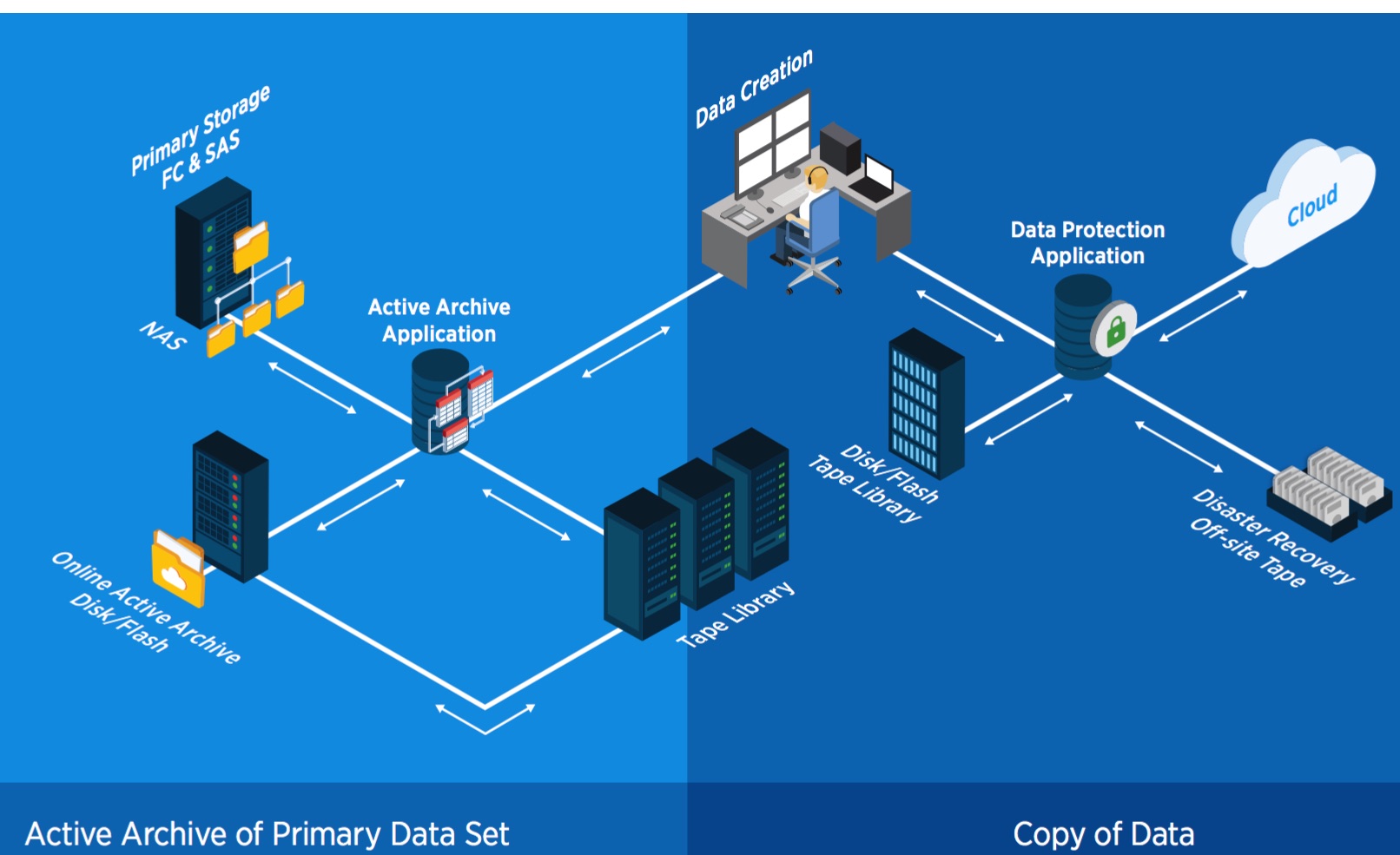
The active archive concept first appeared in the year 1997 for mainframe automated tape library systems and provided a performance improvement for tape-based archives. It combines disk serving as a cache with a tape library and HSM software providing faster online random access, search capability and easy retrieval of long-term data with higher activity levels stored on tape.
The active archive concept is gaining momentum as archival data is fueling rich data analytics and big data is making a lot of archival data ‘come alive’. Active archiving implementations can integrate your existing storage equipment to build an integrated hardware and software solution and can often incorporate enhanced tape file systems such as LTFS.
If you do not prefer to assemble your own active archive solution, some vendors are offering active archive solutions with preconfigured ‘NAS heads’ and support for LTFS or TAR for tape. These work in conjunction with any existing tape library back-end to provide archived data with index and search capabilities so files and parts of files can be easily located and retrieved.
Automating the data archiving process and using an active archive or purpose-built archive systems makes business systems run better, consume fewer resources, and reduces overall storage costs. Active archiving is an advanced storage architecture enabling enormous amounts of archive data to be transformed leading to a competitive advantage. Essentially, ‘an active archive simply makes an archive more active.’
Select Optimal Archive Storage Platform
Compare Archival Capabilities – Onsite and Cloud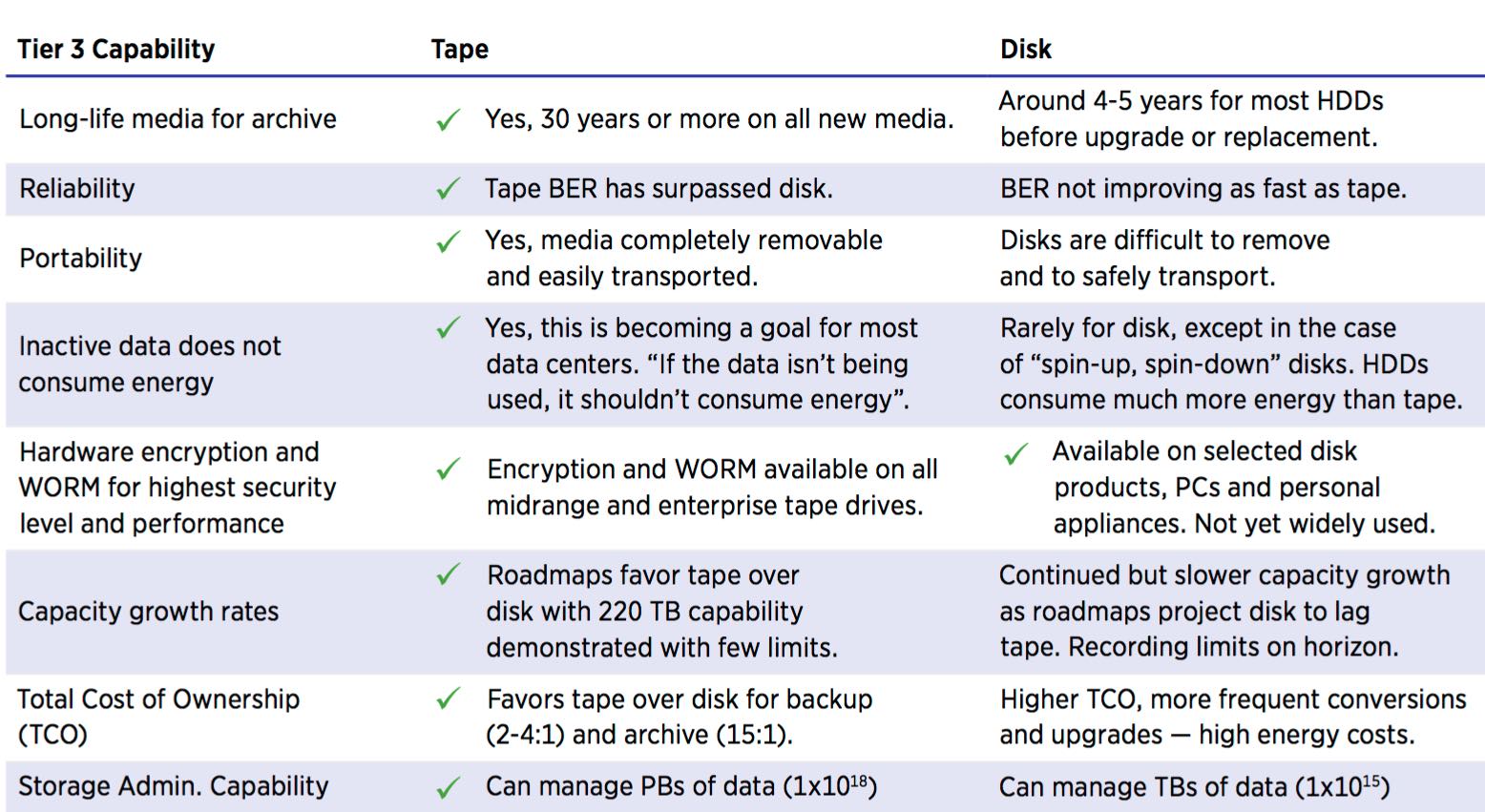
The numerous technological advances in the past decade have enabled tape to become the lowest cost and most reliable archive solution. The inherent consolidation of data into large-scale storage systems that cloud storage implies signals that another category of storage is emerging – tape in the cloud – which has the potential to significantly improve the economic model for cloud archival services.
Storing archival data on tape in the cloud represents a future growth opportunity for tape providers and a much lower cost, more secure archive alternative than disk for cloud providers. Disk can be used for archival storage and serves the active archive concept well; however, using disk by itself for long-term archives has become the costliest archive technology option.
To protect your archives against data loss, you should have multiple copies of the archived data. Some organizations create multiple copies of tape-based archives so that one tape can be stored on the premises while a duplicate tape resides safely off-site. The increasing value of data will push demand for more advanced active archiving solutions.
Many DR-as-a-Service (DRaaS) companies are offering archive services in addition to standard backup or replication services. Keep in mind that approximately 66% of the data stored on every HDD in a business is rarely re-referenced and never changed. It is the mix of inert, archive-candidate data, orphaned data, contraband data, and data that, if eliminated from disk and flash infrastructure, could enable a substantial amount of expensive production storage infrastructure to be returned to productive use.
This reshapes the storage capacity demand and cost curve. The savings from implementing an archive could well pay for the entire data protection and data preservation program.
Ensuring Authenticity and Integrity of Archival Data
- Data Integrity: Data integrity means maintaining and assuring the accuracy and consistency of data over its entire life cycle. Data integrity is the opposite of data corruption which a form of data loss.
- File Fixity: File fixity means the assurance that a digital file has remained unchanged and ‘fixed.’ It is accomplished by software and is a fundamental principle of digital preservation.
- Finding Data in Archives With Extensible Metadata: The Extensible Metadata Platform (XMP) is an ISO standard for the creation, processing and interchange of standardized and custom metadata searching for digital documents and data sets. XMP standardizes a data model and is a serialization format for the definition, searching and processing of extensible metadata and facilitates finding data in archives.
- Security Practices: Security practices include encryption to encode information so that only authorized parties can read it and WORM to prevent overwrite.
- Multiple Copies of Data (Online and Offline): Online copies are computer accessible and provide faster backup and recovery from local and geographically dispersed locations. Offline copies must be inserted into a storage system by a person before it can be accessed by a computer system, and are accessible when electrical outages and natural disasters prevent computer access to online copies.
- Maintaining Access to Data Over Time: Technology refresh means adopting newer technology to mitigate the risk of obsolescence of existing technology and migrating (re-mastering) data to the newer technology. Keeping out of date technology in place too long increases data integrity exposure.
Ensuring authenticity and data integrity of archival data is a required process in maintaining the complete accuracy and consistency of data over its entire lifecycle and is a critical aspect of the design, implementation, and usage of any archival system. Digital data can be assumed to be authentic if it can prove that it is not corrupt after its creation.
The term data integrity is broader in scope and can have widely different meanings depending on its particular context. The overall intent of any data integrity technique is to ensure that data is recorded exactly as intended and upon subsequent retrieval, ensures the data is the same as it was when it was originally recorded. Common causes of poor data integrity are listed below.
Cause of Poor data Authenticity and Integrity
Archival and Long-term Storage Strategies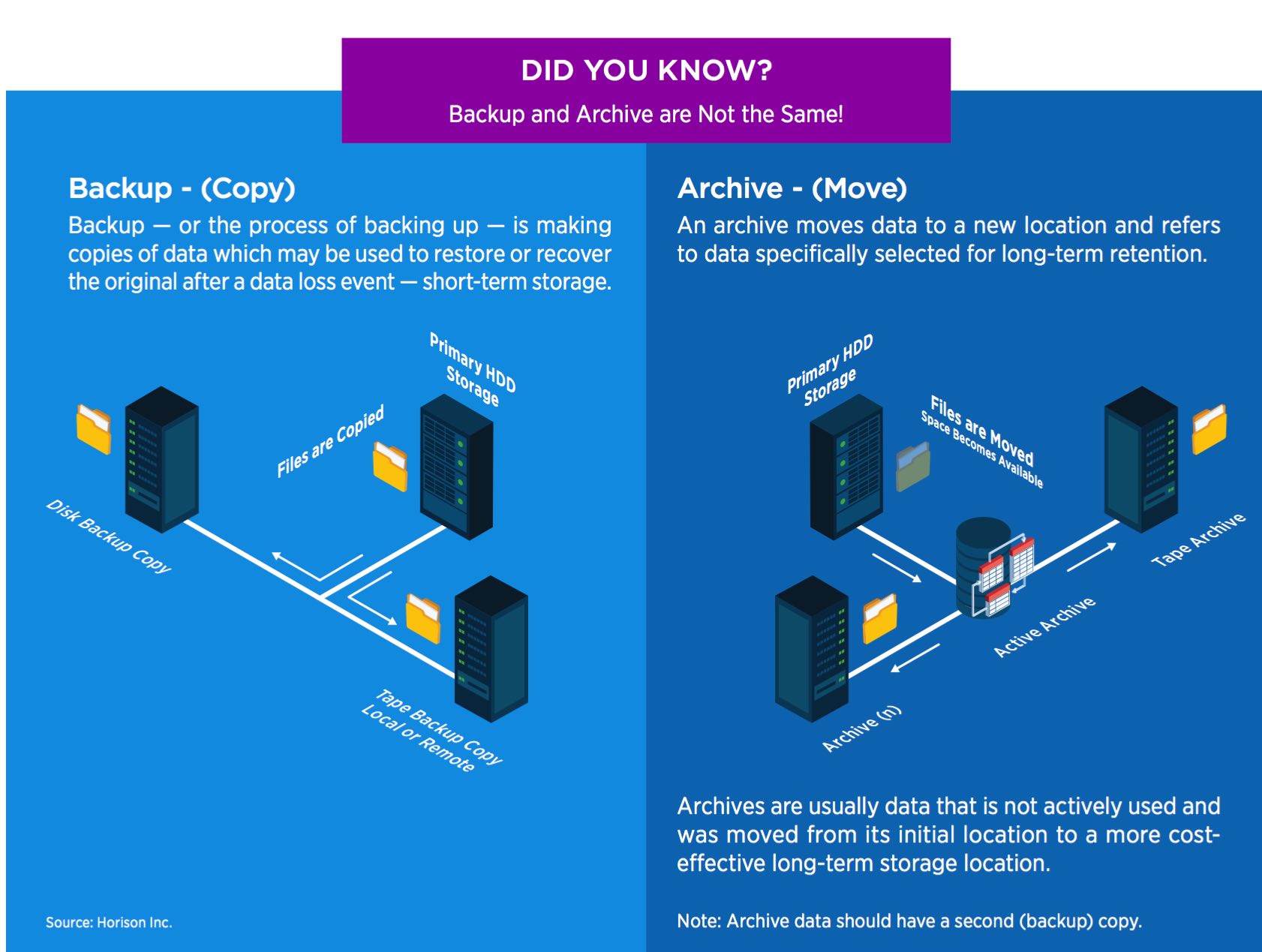
Backup has been the primary method for data protection and recovery since the IT industry began and today few businesses can survive for any period of time without their IT function. Implementing a cost-effective fail-proof backup and recovery capability enables an organization to minimize the impact from data loss and costly downtime that results from an outage.
Surprisingly, many organizations still don’t know the difference between backup and archive! Backup and archive have entirely different processes and objectives. Backup is best-served during an emergency when data needs to be quickly restored from prior copies of data that are kept to mitigate short-term risks. Archives are most efficient for compliance and long-term information retention.
Backup – Copy process: The backup process creates copies of data for recovery purposes which may be used to restore the original copy after a data loss or data corruption event. Backups are cycled and frequently updated to account for and protect the latest versions of important data assets. Remember – backup occurs on your time, recovery occurs on company time.
Archive – Move process: The process of archiving moves infrequently used data to a new location(s) and refers to data specifically selected for long-term retention. Ideally more than one copy of archive data should exist since having a single copy of any meaningful data presents an exposure should the only copy become inaccessible.
The Impact of Downtime and Data Loss
Causes of Unplanned Downtime
(Percent of All Downtime Events)
- Hardware, network or system malfunctions (44% of all downtime events).
- Human caused (32% of all downtime events).
- Software and corruption (14% of all downtime events).
- Computer viruses (7% of all downtime events).
- Natural disasters – A growing concern (3% of all downtime events with major impact).
- Off-site vaults, hot-site facilities, emergency power sources are growing to prevent maximum data and infrastructure damages.
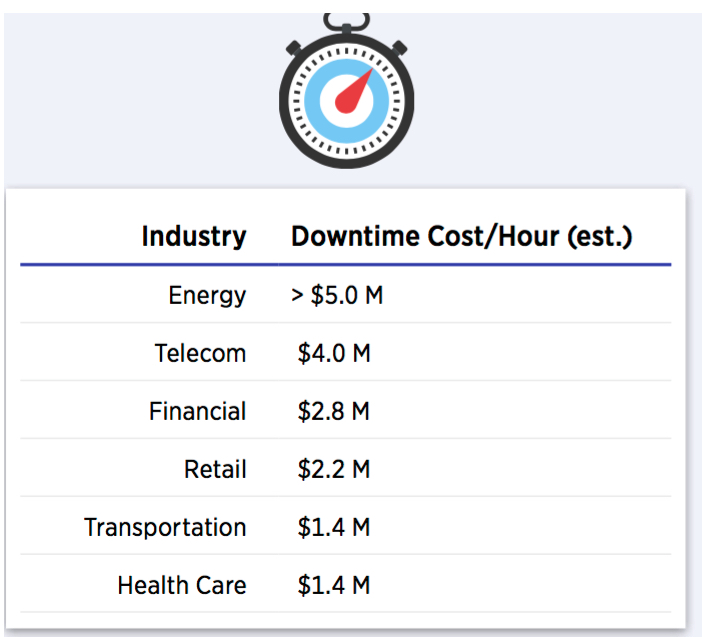
Downtime costs vary significantly within industry segments, especially due to conditions like the size of business, seasonal revenues, time of day, type of outage, and which clients are impacted. A failure of a critical application can lead to the loss of the application service and data, both of which can have significant and potentially permanent legal and financial impact.
The majority of system and data unavailability is the result of planned downtime that occurs due to installing new infrastructure components or applying required software maintenance. Unplanned downtime, by its nature, is a surprise and can have numerous causes including hardware failures, software errors, human errors, computer viruses, and natural disasters as shown in the chart above.
Unplanned downtime typically accounts for about 10% of all computer downtime, but it’s completely unexpected nature means that any single downtime event will most likely be the most difficult to recover from and far more damaging to the enterprise than planned downtime. Understanding your organization’s cost of downtime is a critical metric in either case, and this cost should be determined to understand the impact of an outage.
Downtime usually requires some type of recovery event to occur and typically involves restoring the most current image copy or version from disk or tape, then applying any applicable log data to get to the most valid recovery point.
The recovery process can depend on the cause of the outage. That’s why performing detection and analysis to determine the cause and scope of the failure is critical to ensure a successful and swift recovery. For example, a software program failure could result in either one record being impacted or multiple corrupted databases whereas an HDD failure could lead to the loss of many les.
The Data Recovery Profile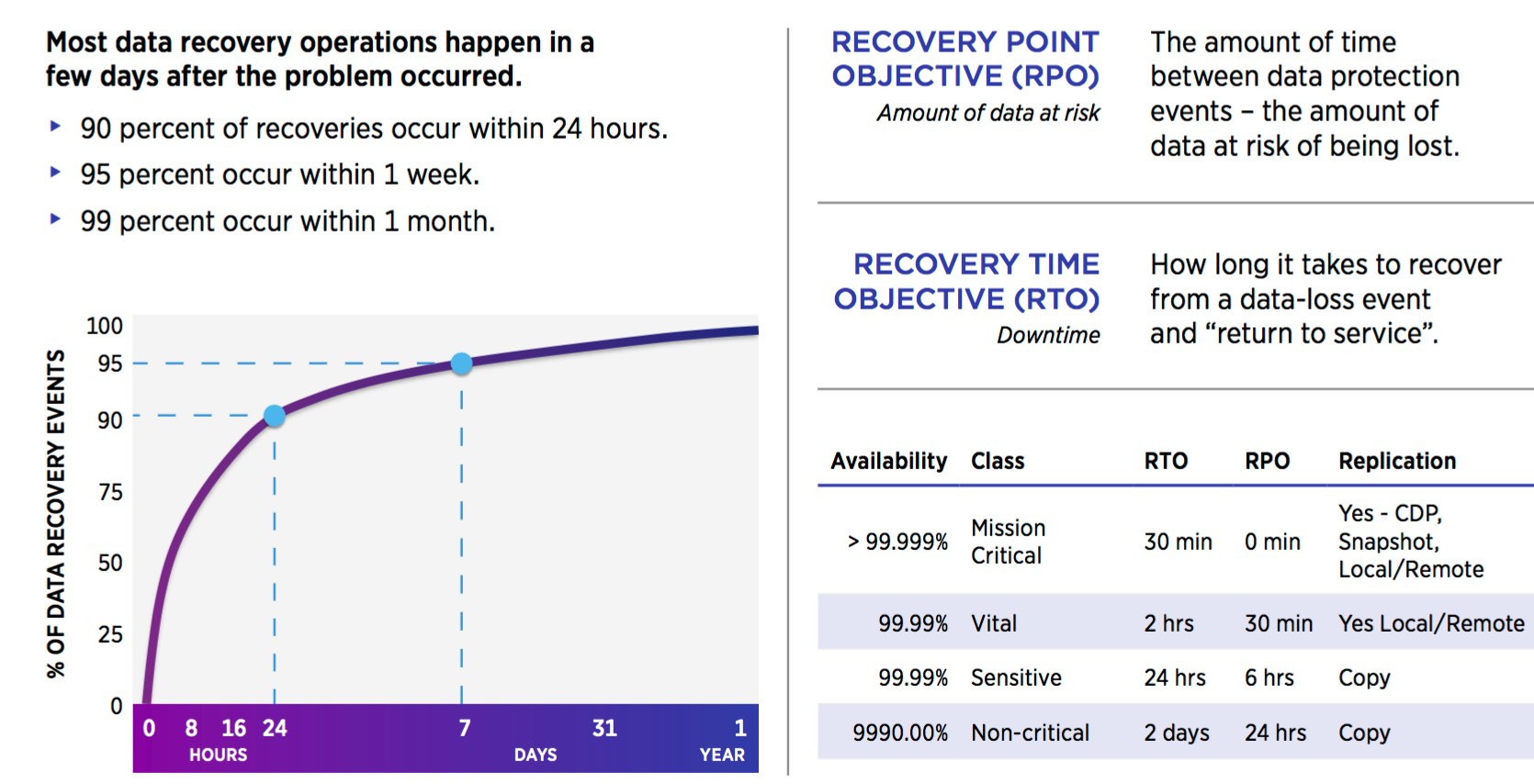
Approximately 90% of computing problems or failures are problem occurred and began data recovery operations. About 95% of problems are identified and begin recovery within one week. Around 99% of the problems have been detected and start recovery after one month. The probability of referencing a backup data after one month becomes minimal and backup copies that are seldom referenced after 31 days can be moved to lower cost storage or off-site.
Keep in mind that RTO – how long can businesses successfully operate without this data, and RPO – the desired amount of time between data protection events – are user defined policies based on the criticality or business value of the data being protected. An RTO should be established for all critical applications and files, and it can be different for certain databases or applications, depending on business needs.
While the user doesn’t usually have much control over how long it takes for the problem to be discovered, they do have control over what means (technology solution) from which to recover. Technologies that have traditionally been managed separately are increasingly becoming integrated into the backup process.
Two of these technologies, snapshot and CDP, have been growing in popularity for many reasons and are being included as options with various backup software products.
BC and DR
It’s important to distinguish between BC and DR as they are different processes. The optimum data protection solutions enable both BC and DR by taking advantage of the strengths of both disk and tape technology.
BC refers to those activities performed daily to maintain the QoS, consistency, and recoverability rather than a process implemented at the time of a disaster. These activities can include many daily activities such as file and database backups, project management, change control, or help desk services.
BC is used to provide a local copy of data to be used, should an application or infrastructure component fail or data become corrupted. For BC, fast access and recovery time is critical. Therefore, disk is the preferred choice of smaller system and user files, emails, and for incremental backups while tape with its faster-streaming data rate, is preferable for restoring larger files.
DR provides a copy of data that is maintained off-site and which can be restored from that geographic location, should the primary data center facility no longer be available due to an actual disaster. DR is the process, policies, and procedures that are related to preparing for recovery which is vital to an organization after a natural or human-induced disaster that may impact the entire data center rather than specific files.
For DR, fast data transfer time and HA are critical often making tape the optimal choice, enabling faster backup and restore of larger files, large databases, servers, VMs, or even entire data centers. While BC involves planning for keeping all aspects of a business functioning in the midst of disruptive events, DR focuses on the critical IT or technology systems that support business functions.
Advanced Technology and Architectures
Storage Reliability Levels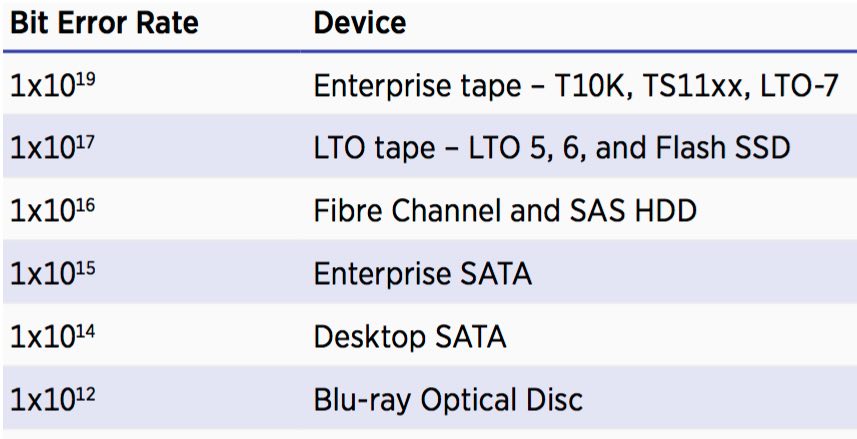
- Published Values for BER – Bit Error Rate.
- BER Metric for HDD, SSD – Number of Sectors in Error per Total Bits Read.
- BER Metric for Tape – Number of Bits in Error per Total Bits Read.
Magnetic disk and tape have both made significant reliability progress in the past ten years with tape reliability surpassing disk in that time frame. Bit error rate (BER) has become the de facto standard measure for storage device reliability and is stated as the number of bits in error per the total number of transferred bits during a particular time interval.
The BER for both enterprise tape and LTO-7 tape is rated at 1×10**19 (1 bit-in-error per 1019 bits transferred or 1-in-10 quintillion) making the top rated tapes 1,000 times more reliable than the top rated HDDs at 1×10**16 Partial Response Maximum Likelihood (PRML) is currently the most effective error detection scheme and is widely used in modern disk and tape drives. PRML attempts to correctly interpret even the smallest changes in the recorded analog signal.
Because PRML can properly decode a weaker signal, it has helped tape to surpass disk in reliability. In layman’s terms, the odds of a meteor landing on your house is 1-in-182 trillion (1-in-1012), and the odds of winning Powerball are 1-in-292 million. In any case, the BER for today’s magnetic storage products – tape, in particular, are most impressive – expect tape to achieve even higher levels of reliability going forward as a BER of 1×10**20 is on the horizon.
Storage Device Areal Density Growth Favors Tape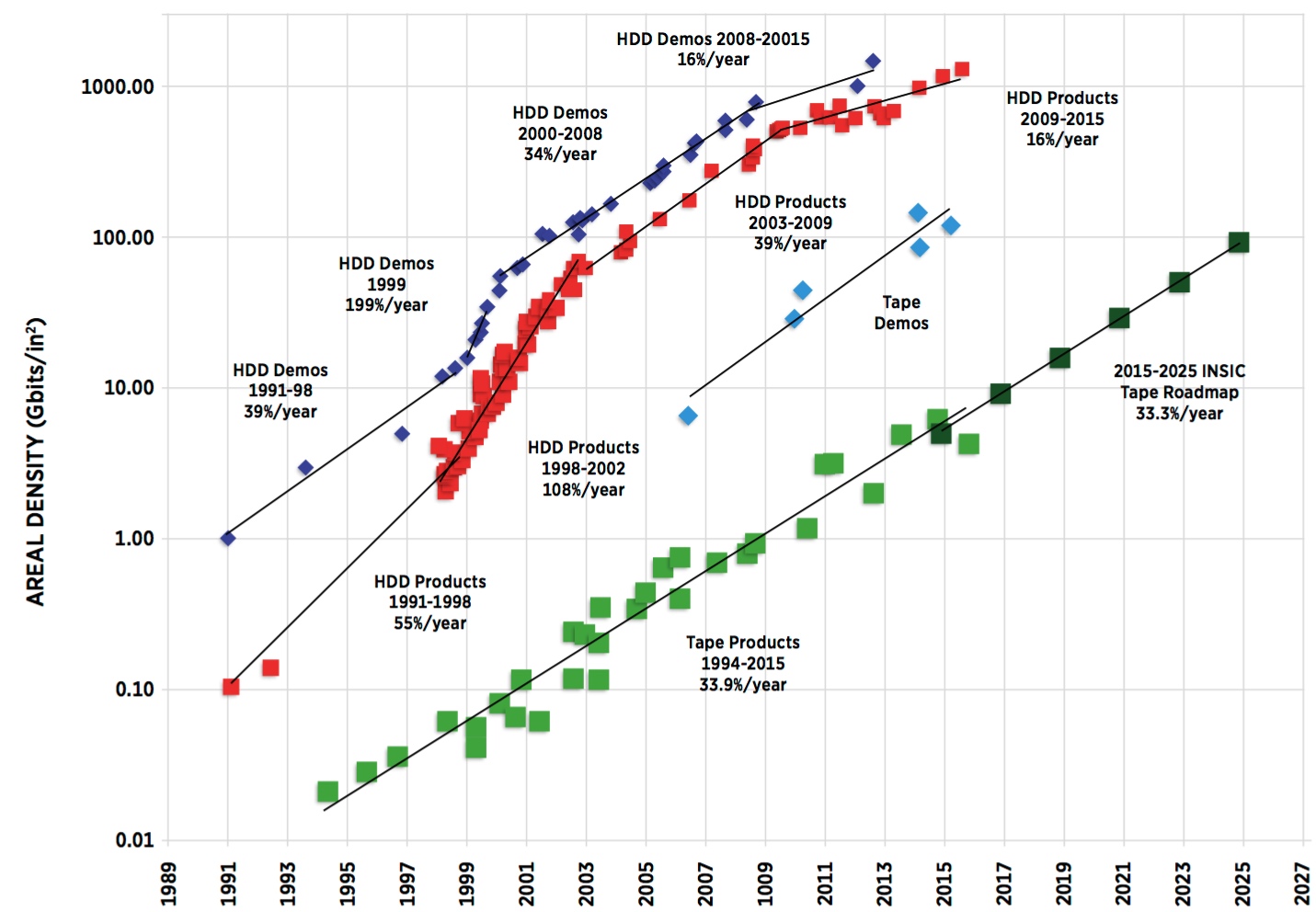
(Information Storage Industry Consortium – All Rights Reserved International Magnetic Tape Storage Roadmap Nov. 2015)
- Older hard disk technology uses longitudinal recording with a limit of 100-200GB/in2????
- Most current hard disk technology uses perpendicular recording. Perpendicular recording is predicted to allow information densities of up to around 1TB/in2???? or 1024GB/in2????).
- Future hard disk technology may be based on HAMR), which use materials that are stable at much smaller sizes. They require heating before the magnetic orientation of a bit can be changed.
Areal density is the key indicator for the growth of future recording technologies. Areal density is a measure of the quantity of bits that can be stored in a given length of track, area of surface, or in a given volume of a computer storage medium. A single megabyte today takes up 11 billion times less physical space than a megabyte did in the late 50’s! The chart above indicates the areal density growth for HDD has tracked at about 16% per year during the past decade.
Due to challenges in overcoming the super-paramagnetic effect from recording bits very close together, there is uncertainty over the timing of the introduction of follow-on technologies needed to maintain that growth rate. The above scenarios for tape suggest that the annual tape areal density growth rates will either continue the traditional 33% values or exceed traditional growth rates and could approach 80% in the foreseeable future. Tape has a much larger surface area to use than HDDs and therefore cartridge capacities are expected to remain ahead of HDD capacity for the foreseeable future.
Unfortunately, neither traditional nor HDD, memory chips, or even tape can continue to shrink forever. Superparamagnetism sets a limit on the storage density of HDDs due to the minimum size of particles that can be used. To varying degrees, it always confronts the next iteration of storage devices.
Managing Data Center Energy Expense
- IT and data centers use ~2% of U.S. electrical supply.
- ata center use 150 watts/sq. ft. ~$700-950/sq. ft.
- Office Buildings use 3-5 watts/sq. ft. ~$60-90/sq. ft.
What Can the Data Center Do?
- Virtualize servers/reduce server count.
- Optimize/implement tiered storage.
- Retire old technology.
- More efficient floor layout and efficient lighting.
- More efficient power/AC equipment and water.
- Use energy consulting group.
- Switch utility providers.
What Can the Electrical Utility Do?
- Encourage off peak programs.
- Offer fixed price/block and index agreements.
- Encourage rebates for efficiency and savings.
- Alternative energy sources.
Average Data Center Power Distribution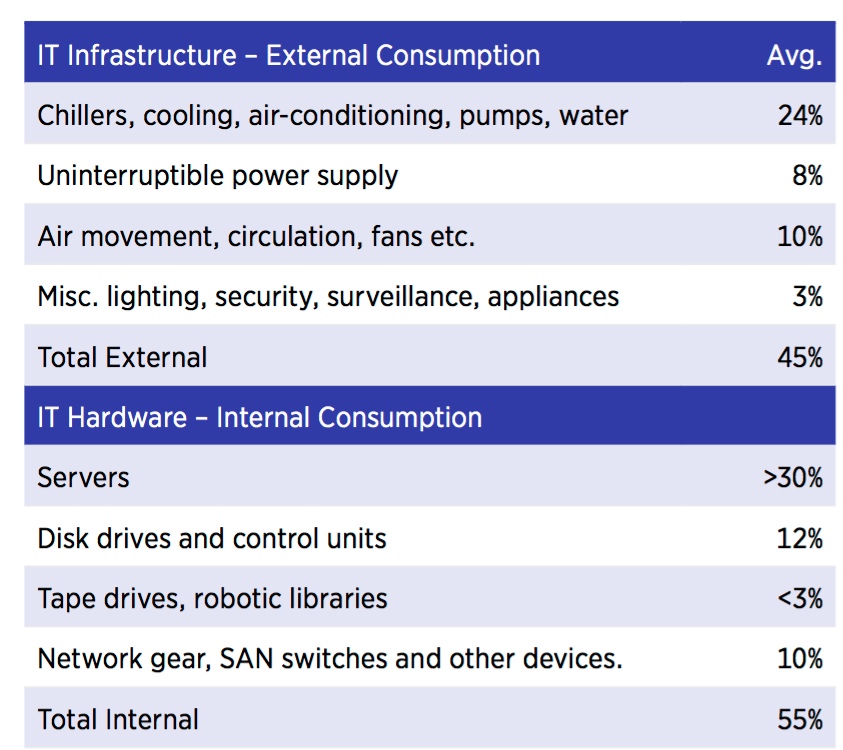
(Source: Numerous Industry Surveys, Horison, Inc.)
Data centers have become the backbone of the global economy from the server rooms that power small organizations to the large enterprise data centers hosting the enormous server farms. The vast majority of data center energy is consumed in small, medium, and large corporate data centers as the hyper-scale cloud centers are relatively few in number and represent only a small fraction of all data center energy consumption in the United States. Unfortunately, traditional large data centers have made less progress in energy management than their hyperscale cloud counterparts.
The explosion of digital content has made data centers of all sizes one of the fastest-growing consumers of electricity in developed countries, and this has become one of the key factors in the construction of new power plants. Energy consumption is one of the largest operating expenses for data centers and can account for nearly 50% of total operating expenses. Energy is being generated by various sources, and each carries their own rate structure.
Approximately one-third of electricity in the U.S. today is produced using natural gas. Another one-third is coal, and the last one-third comprises of all other (nuclear, renewable, etc.). Natural gas rates in the U.S. are currently less than half that of other parts of the world but continue to rise. Coal-fired power plants are being retired creating a growing demand for natural gas and making it the fuel of choice for electricity generation.
By implementing aggressive off-peak and load-balancing management strategies, the typical data center can save 10-20% or more of its annual energy consumption. However, the largest opportunities for IT energy consumption savings are linked to the under-utilization of data center equipment, especially servers, and HDDs. The average server is about 30% busy, and the average HDD allocates about 60% of its total capacity.
Keep in mind that the energy provider or utility company energy rates steadily increase making net energy expense reduction di cult. If you reduce your consumption 15% and the rates go up 15%, you don’t reduce your energy bill – you essentially end up paying more for less energy consumption.
HPC Moves Exascale Architecture Into the Enterprise
HPC currently at petascale compute and storage levels.
- Exascale computing – HPC computing systems capable of at least one exaFLOPS.
- Perform as many calculation as 50million laptops or 1 quintillion operations/s.
- Exascale storage – systems that scale over one exabyte capacity (250,000 4TB HDDs).
- Exascale throughput – data transfer capability of 100TB/s.
- Storage I/O is now the biggest bottleneck suggesting that compute is no longer the main HPC challenge.
- Faster tier 0 memory class storage needed.
- Data availability surpassing 99.999%.
- TCO – Power, cooling, facilities, security.
- The borderline is fading between the HPC domain and enterprise data centers.
Exascale requirements will arrive – regardless of the technology capabilities available.
HPC refers to the practice of aggregating computing power in a way that delivers much higher performance than can be obtained from typical desktop computers to solve large-scale problems in science, engineering, or business. The term HPC especially applies to systems that function above a teraflop or 10**12 floating-point operations-per-second.
Today’s fastest supercomputers operate in the petaflop range delivering 10**15 floating-point operations-per-second. Technologies from the HPC industry are replacing traditional large-scale enterprise IT infrastructures at a more rapid pace and the lines between HPC and enterprise computing are blurring.
Exascale computing is the next milestone for the most powerful HPC supercomputers and is focused on developing a supercomputer capable of performing one million trillion (10**18) floating-point opeations-per-second (1 exaflops). Exascale systems can scale beyond one exabyte in storage capacity, have data transfer capabilities of at least 100TB/s and will push data availability requirements above the 99.999% (five-nines) level.
The enormous push for big data analytics is creating a new set of HPC demands and opportunities, in which storage, by definition, is a major component. To achieve exascale, the need for denser stacked memory and faster, more energy-efficient interconnects will drive tier 0 storage class memory to achieve much higher IO/s levels as the performance capabilities of traditional HDDs show little future growth.
Today’s fastest petascale supercomputers currently offer less than 30% of the capability of an exascale machine. Exascale computers are not here yet, but they are coming. What comes after exascale? One day we can look forward to zettascale (10**21) and yottascale (10**24) computing but at that point, we may have run out of prefixes.
Future Technology Possibilities
Hybrid Memory Cube (HMC)
- HMC – Achieve compute speeds 15 times faster than today’s technology – 15 times higher bandwidth and 70% percent lower energy than DRAM.
- HMC to enable exascale CPU system performance growth for next generation HPC systems.
- HMC uses 10% of the footprint of conventional memory.
- A stack of individual DRAM chips connected by vertical pipelines or ‘vias.’
- he HMC Specification 2.0 is now available for review.
Phase-change Memory (PCM)
- 2D NAND flash is projected to be replaced by either 3D NAND or a new form of nonvolatile class of memory called PCM.
- PCM applies heat to change the electrical conductivity of the media and does not need an erase cycle like flash.
- PCM drives are faster than NAND flash, and can withstand multiple times the number of read/write cycles as NAND.
Quantum Computing
- Quantum computers are designed to harness the power of atoms and molecules to perform memory and processing tasks.
- Quantum computers have the potential to perform certain calculations significantly faster than any silicon-based computer.
- The development of actual quantum computers is still in its infancy.
- Experiments have been carried out in which quantum computational operations were executed on a very small number of quantum bits.
DNA
- DNA is a universal and fundamental data storage mechanism in biology and may be used to store other kinds of data.
- DNA potentially offers unprecedented storage density, ~2.2PB per gram.
- DNA is ideal for long-term storage having an indefinite life.
- DNA needs to be sequenced in order to retrieve the data.
- Ultimately intended for uses with a low access rate such as long term and infinite archival of large amounts of scientific data.
Summary
To keep pace with the increasing demands of business, cloud, mobile, social, big data analytics and advanced security technologies, and to capitalize on their convergence, the storage infrastructure must continue to advance without constraint. Servers, storage, networks and data center facilities can’t be viewed for much longer as separate entities, tightly linked to specific applications and managed in silos using yesterday’s automation tools. The same goes for clouds as they can not function as isolated entities if they are to operate seamlessly with the rest of the data ecosystems.
The shift is underway toward using intelligent devices at the edge of a network in order to enable filtering which intelligently reduces the volume of incoming data. Keep in mind that the entire storage universe, however, virtual and distributed it may be, must be capable of operating as a single integrated system. These are critical prerequisites for the nearly instantaneous services demanded of tomorrow’s storage solutions.
The storage industry is reaching an in inflection point in the use of HDDs. Switching performance sensitive applications to flash-based SSDs as the price falls has fueled growing usage of SSDs and SSD adoption will intensify as it addresses more applications. Expect the price of SSDs, HDDs, and tape to remain differentiated though the price of flash SSD is closing the gap with HDDs. Flash is evolving towards a 3D design setting the stage for its next iteration.
HDD areal density growth is slowing, and new technologies are being developed to overcome several challenges. Tape areal density growth appears to continue unabated at current rates or greater for the foreseeable future. All storage technologies are in some type of flux, and they all offer more functionality than ever before.
With the growing number of highly cost-effective storage solutions in each tier today, it makes good sense to initiate the process of classifying your data in order to optimize storage infrastructure expenses with the understanding the greater the amount of storage to manage, the greater the benefits from this process. The data classification process can be basic or use advanced software to determine the value of data or an application and to identify characteristics of the optimal type of storage subsystem to meet those requirements.
Data is growing at an astonishing rate, and current storage systems will constantly be stressed to keep up with demand, resulting in increasing complexity, higher costs, and increasing security issues. With persistent economic pressures, a limited supply of skilled storage personnel, and the era of big data fully underway, managing data growth ranks at or near the top of today’s most critical IT priorities and will for the foreseeable future.
For those businesses that have yet to seriously tackle this issue, carefully evaluating these technologies and solutions before the growing amount of data becomes completely unmanageable will yield an enormous payback.
Storage Outlook is intended to be a helpful tool to better anticipate, understand, evaluate, and prepare for some of the most pressing storage challenges and opportunities that lie ahead.
Good luck and much success!
Fred Moore





 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

