






Alluxio/Tachyon Virtualizes Distributed Storage From Big Data for Petabyte Scale Computing
At in-memory speed
This is a Press Release edited by StorageNewsletter.com on February 26, 2016 at 2:42 pmAlluxio, Inc. (formerly known as Tachyon), a memory-centric virtual distributed storage system, announced its open source version 1.0 release.
The company aims to become the de-facto storage unification layer for big data and other scale-out application environments in the same manner that Apache Spark became the standard computation layer.
Alluxio’s memory-centric architecture allows developers to interact with a single storage layer API without worrying about the configurations and complexities of the underlying storage and file systems.
Co-created by Haoyuan Li, CEO, Alluxio, and a founding committer of Spark, Alluxio ushers in the next generation of storage virtualization for petabyte scale computing.
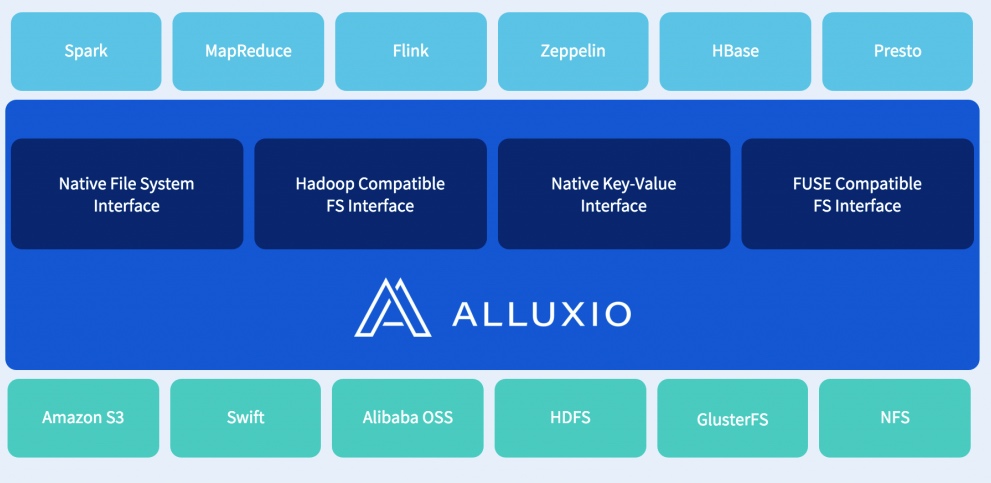
Alluxio provides virtual distributed storage that bridges computation frameworks and underlying storage systems. It delivers data at memory speed to any target framework from any storage system orders of magnitudes faster than existing solutions. Historically, memory has been viewed as ‘cache-only.’ Alluxio’s technology is its separation of the functional and persistent storage layers which provides applications memory centric, storage agnostic data access while maintaining the guarantee of data persistence and consistency.
Organizations can run any computation framework (Apache Spark, Apache MapReduce, Apache Flink, Impala, etc.) with any storage system or file system underneath (Alibaba OSS, Amazon S3, EMC, Google cloud Storage, NetApp, OpenStack Swift, Red Hat GlusterFS, and more), leveraging any storage media (DRAM, SSD, HDD, etc.).
Three years in existence, Alluxio has gained industry support as an open source project. With more than 200 contributors (surpassing other hugely popular AMPLab projects at the same milestone: Spark had less than 100 contributors, HDFS had less than 50 contributors, Hive had less than 20 contributors), more than 12,000 commits, and over 50 commercial organizations contributing, Alluxio runs in production at some of the largest cloud providers for petabyte scale workloads, in financial services to meet government regulations, for research by leading universities, and at technology vendors globally.
Intel Corp. recently published its findings on the diverse range of big storage challenges that Alluxio can address.
“Big data analytics is driving new requirements for distributed memory across clusters for real-time streaming, interactive queries, analytics and graph processing,” said Michael Greene, Intel VP, software and services group and GM of system technologies and optimization. “We are excited to work with developer communities on Alluxio and to optimize Alluxio solutions on Intel platforms. Ultimately, this helps our customers create more innovative and high performance cloud and big data solutions.”
In financial services, Alluxio brings advantages. It helps banks make faster and better trading decisions through performance improvements and also helps satisfy regulatory requirements. Barclays, the financial services firm with 48 million customers and clients, recently published a report about how it uses Alluxio to boost big data analytics performance without duplicating confidential customer information to disk.
Last summer, IBM Research published a blog about using Tachyon for “ultra-fast big data processing” to overcome “critical bottlenecks for system workloads.”
For some of the world’s cloud computing giants, Alluxio is allowing analysts to discover insights interactively by analyzing petabytes of data in near real-time to improve customer experience.
“As one of the largest Internet company in the world, Baidu constantly faces the challenges of managing data at multi-petabyte scale. By adopting innovative technologies like Alluxio we are able to help our users extract meaningful and useful data almost instantly,” said James Peng, chief architect, Baidu. “Our deployment of Alluxio cluster has already reached 1,000 workers, which is one of the largest Alluxio clusters in the world. The tiered storage of Alluxio has provided us great flexibility in managing data in large-scale. We are seeing an average 10-fold, and up to 30-fold performance improvement in supporting interactive query system and other types of workloads. This greatly improved the speed in making important business decisions.”
“As the cloud computing business for Alibaba Group, the world’s leading e-commerce business, Alibaba manages many of the world’s largest data centers, including the largest big data cluster ever built in China,” said Wensong Zhang, CTO and senior research fellow, AliCloud, founder of Linux Virtual Server. “With Alluxio combined with AliCloud OSS as well as other AliCloud cloud service products, our customers can leverage the technology trends of hardware to run important jobs at the fastest performance. We have been contributing to the Alluxio open source community and believe that Alluxio will play a critical role in the future of big data infrastructure.“
As a PhD candidate at UC Berkeley, Li saw Spark adoption driving the requirements for more developer-friendly methods for how big data frameworks access persistent data at in-memory speeds. Formerly known as Tachyon, the Alluxio system gained prominence in use cases that required in-memory storage speeds for Spark computation and received early backing from enterprise software and storage leaders, including EMC Corp. and Pivotal Software, Inc. Where storage and file systems have historically required high customization and tuning, Alluxio brings a unified interface that’s intuitive for developers, easy for operators, and delivers speeds for data access to support a broad range of big data use cases such as machine learning, real-time analytics and streaming data.
“As a layer that abstracts away the differences of existing storage systems from the cluster computing frameworks such as Apache Spark and Hadoop MR, Alluxio can enable the rapid evolution of the big storage, similarly to the way the IP has enabled the evolution of the Internet,” said Prof. Ion Stoica, co-author of Spark, co-founder and executive chairman of DataBricks, co-director of UC Berkeley AMPLab and Ph.D. co-advisor to Li.
“Enterprise storage has been long overdue for the next-generation storage interface that simplifies the interaction between today’s big data applications and frameworks with storage systems,” said Li co-creator of Alluxio and founding CEO, Alluxio. “Alluxio has enabled this innovation in storage by separating the function layer from the persistent storage layer. Our community has leveraged the power of memory-centric architecture to enable any framework to access any data, from any storage.”
“AMPLab has created some of the most important open source technologies in the new big data stack, including Apache Spark,” said Michael Franklin, professor of computer science and director of the AMPLab, UC Berkeley. “Alluxio is the next project with roots in the AMPLab to have major impact. We see it playing a huge disruptive role in the evolution of the storage layer to handle the expanding range of big data use cases.”
To protect the project from potential trademark litigation and to preserve the IP of the open source software community contributions internationally, the community changed the project name from Tachyon to Alluxio. A newly-created Alluxio Open Foundation will be the steward of the project.
In 2015, Andreessen Horowitz invested $7.5 million in Alluxio, which has since assembled a team of some of the world’s leading distributed computing experts from Carnegie Mellon University, Google, Palantir, UC Berkeley AMPLab and VMWare to foster the adoption of Alluxio and support large-scale production enterprise users.
With the release of open source version 1.0, Alluxio added many new features to simplify developing new distributed applications for big data that can bring in-memory performance speeds to any file or storage system.



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

