






What’s Software-Defined Storage ? – SNIA White Paper
Can be element within a software-defined data center but also function as stand-alone technology.
This is a Press Release edited by StorageNewsletter.com on February 6, 2015 at 3:05 pmHere is a white paper published byy the Storage Networking Industry Association (SNIA)
Software Defined Storage
By Mark Carlson, Alan Yoder, Leah Schoeb, Don Deel, Carlos Pratt, Chris Lionetti, and Doug Voigt
January, 2015
Introduction
Software Defined Storage (SDS) has been proposed (ca. 2013) as a new category of storage software products. It can be an element within a Software Defined Data Center (SDDC) but can also function as a stand-alone technology. The term Software Defined Storage is a marketing ‘buzzword’ that is a followon to the term Software Defined Networking, which was first used to describe an approach in network technology that abstracts various elements of networking and creates an abstraction or virtualized layer in software. There is also work going on to define Software Defined Compute. The software defined approach abstracts and simplifies the management of networks into virtual services. In networking, the control plane and the data plane have been intertwined within the traditional switches that are deployed today, making abstraction and virtualization more difficult to manage in complex virtual environments. Network capabilities are now just catching up with capabilities that have been offered in the storage industry for over a decade. SDS does represent a new evolution for the storage industry for how storage will be managed and deployed in the future.
Attributes of SDS
- The following are attributes of SDS that are typically seen in the market:
- May allow customers to ‘build it themselves,’ providing their own commodity hardware to create a solution with the provided software.
- May work with either arbitrary hardware or may also enhance the existing functions of specialized hardware.
- Nearly always enables the scale-out of storage (not just the scale up typical of big storage boxes).
- Nearly always includes the pooling of storage and other resources.
- May allow for the building of the storage and data services ‘solution’ incrementally.
- Incorporates management automation.
- Includes a self service interface for users.
- Includes a form of service level management that allows for the tagging of metadata to drive the type of storage and data services applied. The granularity may be large to start, but is expected to move to a finer grained service level capability over time.
- Allows administrators to set policy for managing the storage and data services.
- May allow storage and data service owners to do cost recuperation via a chargeback model based on the authenticated storage consumer.
- Enables the dis-aggregation of storage and data services.
Some analysts and vendors contend that SDS must be hosted on heterogeneous block storage. This is not the SNIA’s position, which is platform-independent. The SNIA definition of SDS allows for both proprietary and heterogeneous platforms. What is necessary to meet the SNIA definition is that the platform offers a self-service interface for provisioning and managing virtual instances of itself.
Differentiation of SDS
The aspect of SDS that differentiates it from traditional storage is how SDS products are commonly deployed. Data Services can be executed either in servers or storage, or both, spanning the historical boundaries of where they execute. This has potential impacts on security and reliability, and may be an interesting revival for DAS in some cases.
While SDS builds on the virtualization of the Data Path, SDS is not virtualization alone. The Control Path is abstracted as a service as well. The storage service interface allows the data owner to express requirements on both the data and its desired service level requirements.
Necessary SDS Functionality
Since many storage offerings today have already been abstracted and virtualized, what capabilities should be offered to claim the title of Software Defined Storage?
SDS should include:
- Automation – Simplified management that reduces the cost of maintaining the storage infrastructure.
- Standard Interfaces – APIs for the management, provisioning and maintenance of storage devices and services.
- Virtualized Data Path – Block, file and object interfaces that support applications written to these interfaces.
- Scalability – Seamless ability to scale the storage infrastructure without disruption to the specified availability or performance (e.g. QoS and SLA settings).
- Transparency – The ability for storage consumers to monitor and manage their own storage consumption against available resources and costs.
Ideally, SDS offerings allow applications and data producers to manage the treatment of their data by the storage infrastructure without the need for intervention from storage administrators, without explicit provisioning operations, and with automatic service level management.
In addition, data services should be able to be deployed dynamically and policies should be used to maintain service levels and match the requirements with capabilities.
Metadata should be used to:
- Express Requirements
- Control the Data Services
- Express Service Level Capabilities
The User’s View of SDS
An application or storage user’s view of SDS includes both a data path and a control path. The data path consists of a combination of previously standardized block, file and object interfaces for which applications have been developed, but what about the control path?
Nearly all storage that is currently deployed requires a storage administrator to create virtual storage devices (block storage logical units, filesystem shares, object containers) for the application to use.
Behind the scenes, the storage administrator is deploying data services for the data that is stored on these devices. In the majority of cases, each data service requires its own administration interface. Changing those data services affects all the data stored on those virtual devices. Communication of the requirements for that data is usually out of band of any storage interface, and is made directly to the storage administrator, as is shown in the figure below:
Traditional, Manual Conveyance of Data Requirements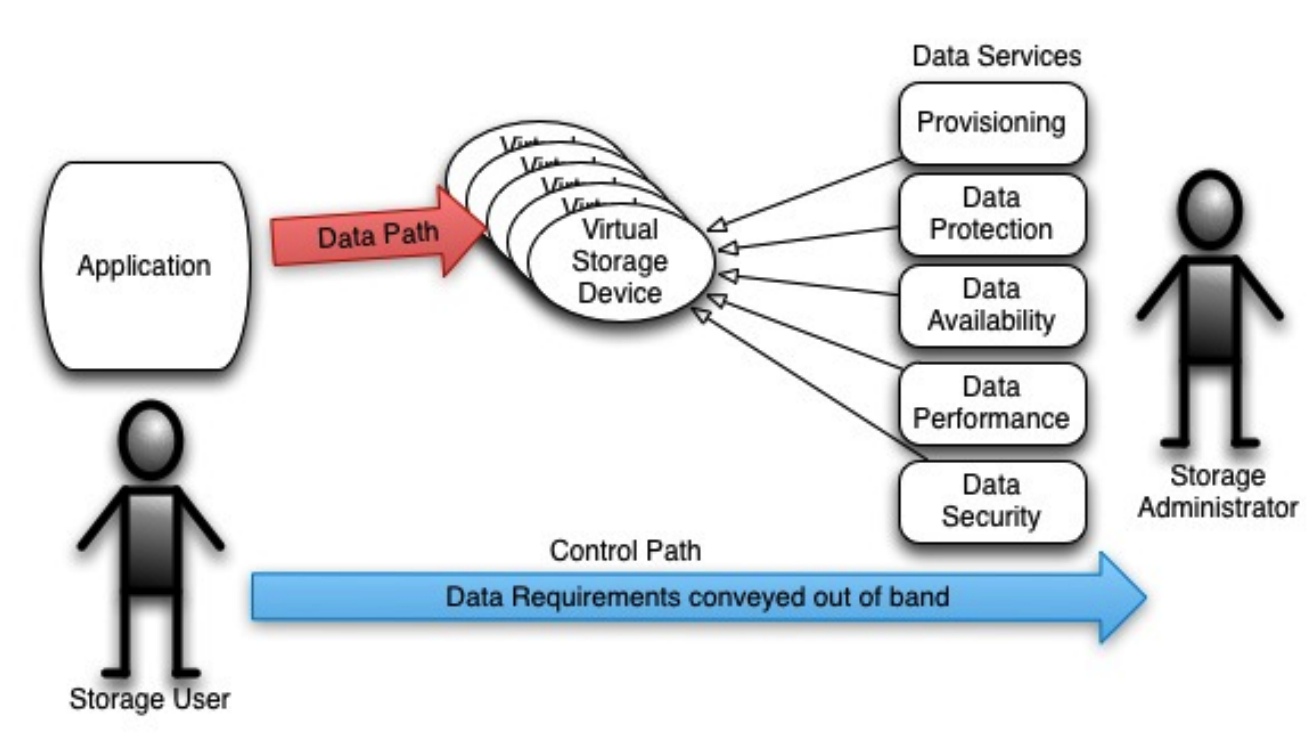
As can be seen in the above figure, this storage is not very ‘software defined’, but more ‘storage administrator’ defined and implemented. A problem with this approach is that when the process to request storage is onerous or time consuming, consumers tend to request excess resources to avoid re-engaging the storage team. This often means that once deployed, those excess resources are not returned to the storage team. This legacy method of deploying storage may lead to a high TCO for storage.
Role of Metadata
In order to introduce automation into the storage infrastructure and reduce the costs due to manual administration, there needs to be a way to convey the data requirements directly to the automationsoftware. The granularity of these requirements needs to at least be at the level of individual virtual storage devices as is common today. To prepare for future automation, however, each data object should be able to convey its own requirements independent of which virtual storage device it resides on. The objects should be grouped and abstracted to let the ‘user’ understand their choices, otherwise the user will need to be a storage expert.
In order to convey the requirements to the storage system, the application or user needs to mark each file or object with those requirements. Metadata, or ‘data’ about data, is the perfect mechanism for this purpose. By marking the data object with metadata, which documents the requirements, the storage system can address those requirements with the data services as show below:
Addition of Metadata for Conveyance of Data Requirements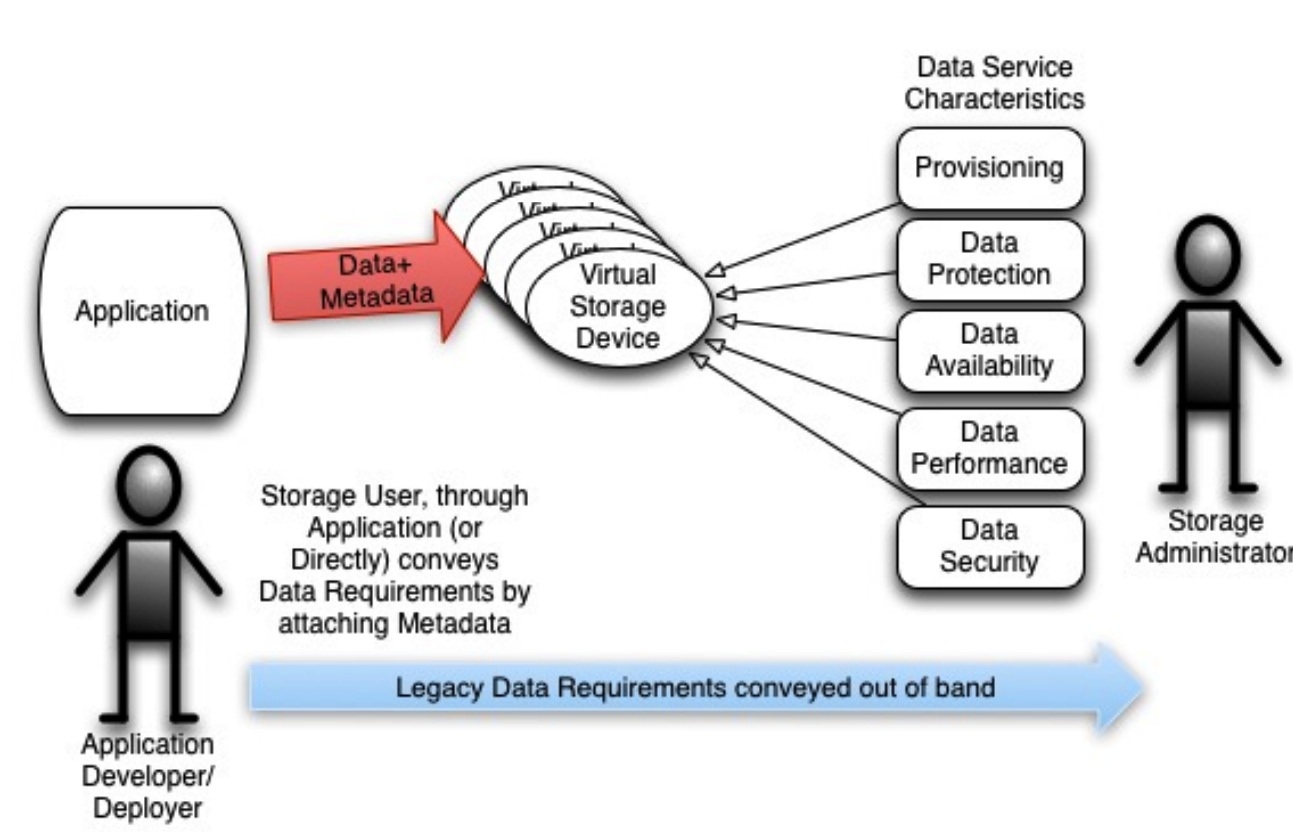
The requirements may still be conveyed out of band of the data path, but automation can eventually obviate this need. With SDS, the storage administrator can start to move to higher level tasks such as defining policies, rather than spending time fixing immediate problems that cause service levels to degrade.
SDS Big Picture
Putting it all together, the following diagram illustrates the concepts behind SDS:
Big Picture of SDS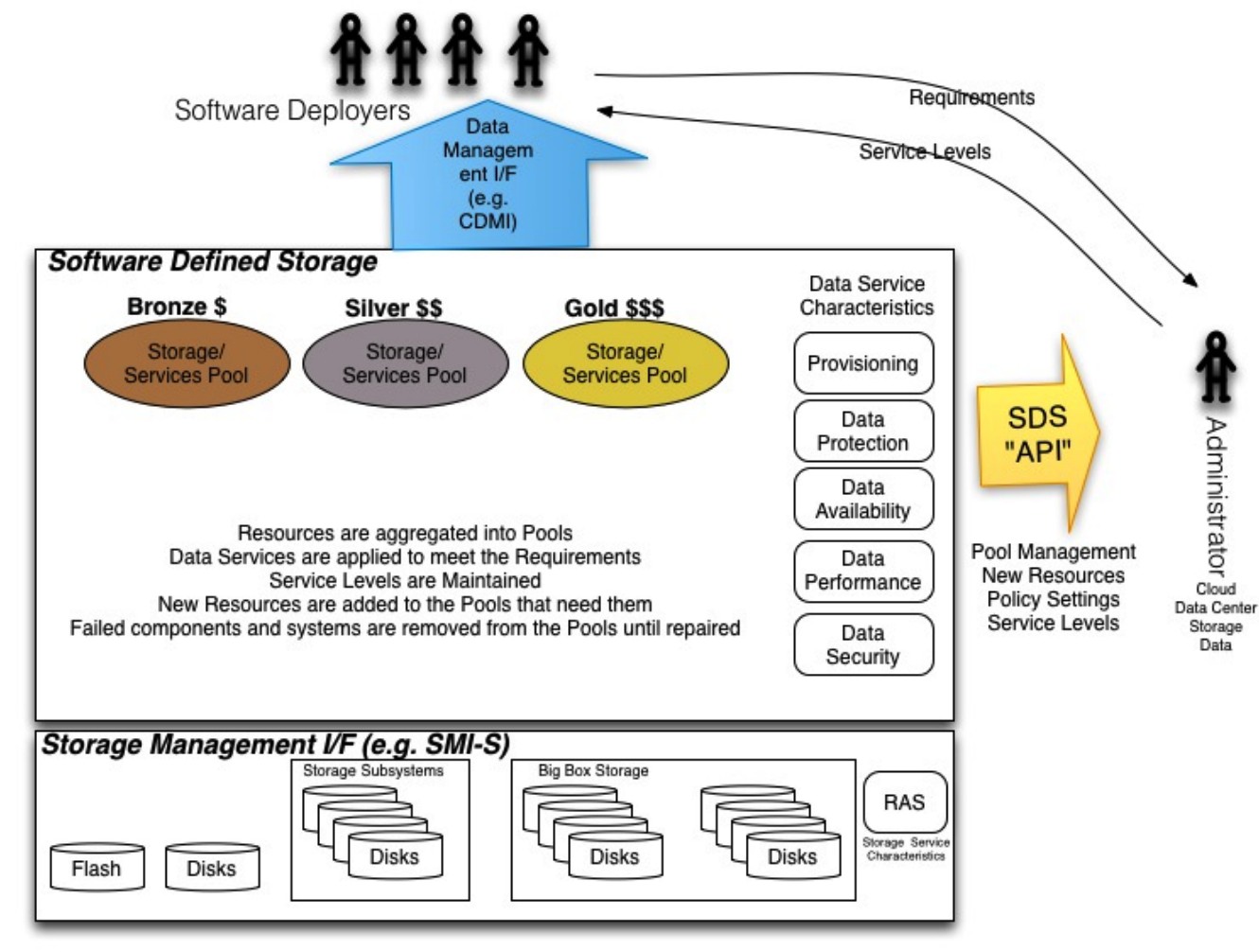
Software deployers work through a Data Management interface (such as CDMI) to convey their requirements for the data they own. They also receive the desired service levels through a combination of the SDS solution and the administrators.
For now, SDS aggregates the resources into pools. The data service characteristics are applied to the data in order to meet the service level requirements and are thus maintained. New resources are added to the Pools that need them and failed components and systems are removed from the pools until repaired.
SDS prefers a standardized storage management interface (such as SMI-S) in order to automate the management of the storage resources and discover their capabilities for use in various pools. However, legacy storage management interfaces are common today, and predicting their demise is premature. Additionally there are emerging open source APIs that are becoming a de facto storage management standard, an example is OpenStack Cinder.
Lastly, SDS enables the administrators to work with abstract interfaces that let them manage pools, assign new resources, set up policies and determine service levels.
Metadata in CDMI
The Cloud Data Management Interface (CDMI) uses many different types of metadata, including HTTP metadata, data system metadata, user metadata, and storage system metadata. To address the requirements of enterprise applications and the data managed by them, this use of metadata allows CDMI to deliver simplicity through a standard interface. CDMI leverages previous SNIA standards such as the eXtensible Access Method (XAM) for metadata on each data element. In particular, XAM has metadata that drives retention data services useful in compliance and eDiscovery.
CDMI’s use of metadata extends from individual data elements and can apply to containers of data, as well. Thus, any data placed into a container essentially inherits the data system metadata of the container into which it was placed. When creating a new container within an existing container, the new container would similarly inherit the metadata settings of its parent container. Of course, the data system metadata can be overridden at the container or individual data element level, as desired.
The extension of metadata to managing containers, not just data, enables a reduction in the number of paradigms for managing the components of storage – a significant cost savings. By supportingmetadata in a cloud storage interface standard and proscribing how the storage and data system metadata is interpreted to meet the requirements of the data, the simplicity required by the cloud storage paradigm is maintained, while still addressing the requirements of enterprise applications and
their data.
SDS as an integral component of the SDDC
A question that many systems administrators have is: Where does SDS fit in my data center? A simple answer is to look at the SDDC as the brain of the hardware infrastructure that inevitably is behind a cloud or part of a more traditional and older data center. From a high level view SDDC is comprised of three components as shown in the figure below.
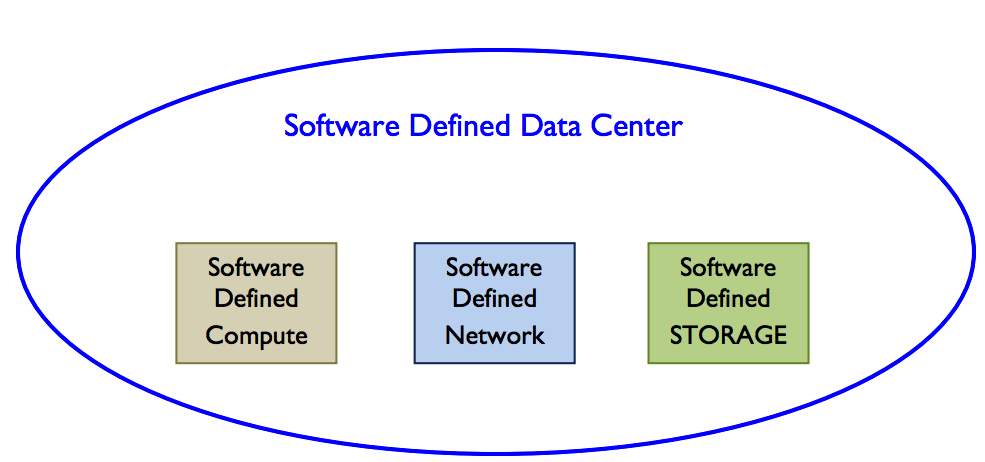
The Software Defined Compute is a virtualized computer environment that offers the processing layer of the SDDC. The Software Defined Network provides a less complex environment for its management. The SDS offers a less complex method of managing storage. All three are needed to have a well-tuned working software defined data center. In short it can be said that SDS is an integral part of SDDC.



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter


