






Turbocharging Hybrid Storage With Data Efficiency
By Louis Imershein, director product strategy, Permabit
This is a Press Release edited by StorageNewsletter.com on October 7, 2014 at 2:51 pmTurbocharging Hybrid Storage With Data Efficiency
This article was written by Louis Imershein, director product strategy, Permabit Technology Corp. Prior to joining Permabit, he was senior product marketing manager for the Sun Microsystems data management group.
Flash memory is faster than disk. DRAM is faster than flash memory. These two precepts are all the background you need to understand how a storage cache works.
Why have hybrid arrays at all? Why not just store data in DRAM all the time? There are two reasons, first is money – DRAM is 35x more expensive than flash, and over 400x more expensive than disk. The second is volatility – because DRAM doesn’t maintain state, like disk or flash, data is only as safe as the DRAM power source. Any storage system using DRAM for a write cache must have the ability to get the data off that media in the event of power failure. This is why DRAM is considered a volatile cache and also why vendors turn to flash for caching, because it offers a good compromise in terms of performance and reliability.
Price/GB for Storage Types as of Sept 2014
- SDRAM: $16.50
- Flash SSD: $0.48
- HDD: $0.04
So why not use flash all the time? Again, it has to do with cost. Pop over to Best Buy, and you’ll see flash units at 12x the cost of HDDs. For a brief period, flash-based storage devices were dropping in price faster than HDDs. However, today, with flash fabrication facilities challenged by demand and HDD vendors moving toward volume shipments of 8TB devices, most industry analysts anticipate that the cost difference between the two types of devices for enterprise applications will stabilize.
All flash arrays absolutely have their place in IT environments where consistent high random I/O performance with low latency is required. For 90% of application workloads out there today, they represent an added expense without significant benefit. For those workloads, a hybrid array (consisting of a mix of HDDs with both DRAM and flash-based cache) can deliver equivalent performance and greater capacity at a much lower cost.
We’ve talked about performance, and we’ve talked about cost. The basic purpose of a cache is to accelerate performance for the most frequently performed types of storage access. It does this by storing data that will be accessed more than once on a faster tier of storage.
To better understand, you can break storage access into four types of I/O operations: random reads, sequential reads, random writes, and sequential writes. If your cache understands the workload you’re faced with, then you can optimize for that workload by moving data to a faster tier of storage in the most efficient fashion.
For example, an application might have a workload where random reads dominate, with the occasional massive sequential write pattern used to ingest data. This is the typical ‘Data Warehousing’ workload requiring vast amounts of random read cache. Knowing the IO size associated with those reads and the proximity of IOs being read in, can help to determine how to best size the read cache to improve performance in this scenario.
At the same time, a separate application could very well have a 50/50 mix of random reads and writes – a workload typical for VDI. This second pattern would benefit from a more balanced use of cache for both reads and writes, and it’s pretty dependent on the most commonly accessed data having some locality in the storage (for example, many reads of an OS image at boot time).
Understanding these types of utilization patterns allows storage vendors to design efficient caching strategies for these workloads.
In the read case, data is read into cache the first time it is accessed. At that point, the data is available for fast access from the cache. Eventually, it will be displaced by other data. Two factors influence when the data will be displaced: how frequently the data is accessed, and the space remaining available in cache.
In the write case, data is written to cache and the write is acknowledged before the data is committed to a slower tier. Write cache offers no benefit for most sustained sequential write workloads because the cache simply fills up. Fortunately, this is also a workload that HDDs excel at handling at a low cost, so no cache is really required here. It’s only when we see bursts of data that write cache becomes truly valuable. For that case, write caching can improve performance by an order of magnitude.
As you can see from both examples discussed above, to maximize the benefit from caching you have to have enough cache. For many applications, the bigger the cache, the greater the potential performance benefit. The best way to get a bigger cache, without having to buy more flash or DRAM, is through data efficiency technologies like data deduplication and compression.
Deduplication is a technique for reducing the consumption of storage resources by eliminating multiple copies of duplicate data. Instead of writing the same data more than once, each duplicate block is detected and recorded as a reference to the original block. Deduplication is distinct from compression in that it operates at a much larger granularity and across much larger datasets than compression. Compression operates at a “micro” level, removing duplicate information within a file. When combined, the benefits of the two technologies yield greater potential savings than either technology on its own.
The efficiency benefits of deduplication and compression are additive and yield typically 6:1 data reduction rates across shared storage environments.
For caching, inline is a much more effective technique because new data coming into cache is always reduced, offering the highest possible effective capacity for the cache.
So what kind of impact might this have on cache? Well, it depends on the use case, but for a moment, let’s assume a 6x expansion of effective cache improves an application’s typical 80% cache hit rate to 95%.
There are in fact several use cases where that can lead to the 400% increase in random IO performance as seen below. In fact, what we see is that the increase in performance is not linear as cache rates increase, it’s exponential. The reason for this is that cache media is so much faster at satisfying requests than disk.
Data Efficiency Benefits for Cache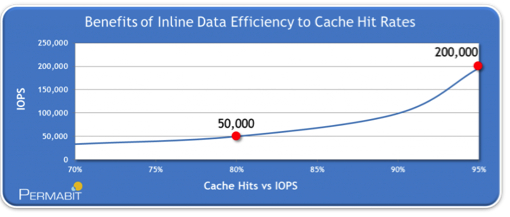
Back in 2009, VMware looked into how data efficiency, specifically deduplication, might benefit virtual environments. They published the following results in a USENIX paper titled, Decentralized Deduplication in SAN Cluster File Systems. To demonstrate the benefits of deduplication to caching, they picked a common, critical time limited scenario: booting many VMs concurrently. As they note, “VDI boot storms can happen as part of a nightly cycle of shutting down VMs and their hosts to conserve power, from patching guest OSs en masse, from cluster failover, or for a myriad of other reasons.”
They compared the average time required to boot from one to twenty VMs both with and without deduplication applied with the following results: 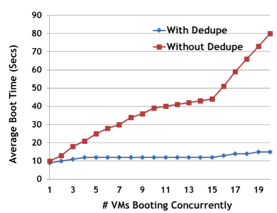
The results showed a dramatic improvement of deduplication versus full copies, owing to the decrease in cache footprint.
In summary, hybrid arrays use cache to deliver the best value in terms performance and scalability across a wide range of general purpose application workloads. When data efficiency technologies such as deduplication and compression are applied to hybrid arrays, the performance of a hybrid array can be dramatically improved. As mentioned above, these improvements can be as high as 400% taking a 256MB cache to an effective cache size of 1.5PB. The resulting performance will be greatly increased and can take a hybrid array into the performance range of all flash arrays, but without the additional cost. Looks like a win-win from here.



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

