







Preventing Performance Bottlenecks With Inline De-Dupe
Article written by Jered Floyd, CTO, Permabit
This is a Press Release edited by StorageNewsletter.com on May 13, 2014 at 2:53 pmThis article was written by Jered Floyd, CTO, Permabit Technology Corporation.
Preventing Performance Bottlenecks with Inline Deduplication
Implementing high performance in enterprise storage is a constant battle to find and eliminate the next system bottleneck. Normally this alternates between limits of the underlying media and the computational overhead of metadata management, but choosing the wrong approach to deduplication can introduce a third performance challenge that can be impossible to overcome. Storage that implements a multi-pass approach to data optimization, such as staged or post-process deduplication, becomes inherently at a disadvantage for both computational and media overhead.
Common Performance Bottlenecks
In a typical enterprise storage system the bottleneck to performance is in one of two places: media bandwidth or computational overhead.
For the storage system designer, media overhead is the simplest to address – add more or faster media. In a HDD-based storage system, this means adding faster drives, more drives, and larger drive sets. In a flash storage system bandwidth is increased by using SLC flash, adding more independent modules, allocating more over-provisioned space, and improving the flash translation layer.
Reducing computational overhead is a greater challenge. Once you have enough media bandwidth the problem becomes shuffling data to and from the storage initiators. Identifying the bottlenecks to performance here can be devilishly complex, as the designer must be concerned about matters such as system memory bandwidth, number of data copies and, especially in today’s multi-core world, synchronization between multiple requests. There’s no silver bullet here, so the only solution is having a very talented team of software engineers designing and optimizing the storage platform.
Adding deduplication introduces complexity directly into this most challenging area for performance improvement. Any deduplication implementation must interact directly with the storage metadata that is so critical to performance, since I/O requests are being redirected or eliminated based on the system’s knowledge of duplicate data. Unless the deduplication technology has been designed and implemented in an inline, multi-core scalable, and low memory overhead way, as Permabit has done, system architects often try to separate deduplication into a separate layer and a second pass through the data. This is a mistake that harms storage performance in a way that cannot be repaired.
Impossible Challenge of Multi-Pass Deduplication
This second pass through the data commonly occurs in two possible places, on the final storage media, or when transferring data from a staging area to the final storage media.
The first case is always called post-process deduplication. Data are written to their resting media location and a separate process later reads them back, as time and bandwidth allow, determining if any portions are duplicate. If there are duplicates then storage metadata is updated to note this and space is freed for reuse. I’ve written extensively in the past about the risks of post-process deduplication; since it always requires additional media bandwidth and computational overhead it severely harms performance, and since there are no guarantees about when deduplication will occur it does not meet the requirements for high-change-rate use cases such as VDI.
Post-Process Deduplication
The second case, where data is deduplicated as it is being moved from a staging location to a final media location, is often erroneously called inline – as it is inline with that destaging process – but is really just a modified form of post-process deduplication. As with conventional post-process deduplication another round of data read and processing must occur. Additionally, now both the staging media and final media must provide the full system level of performance or either can become the bottleneck.
For example, some flash storage systems stage all data to a small arena of SLC flash prior to deduplication. This design doubles the number of possible performance bottlenecks in the architecture: performance writing to the staging area, front-end data ingestion, final media storage performance, and the deduplication and de-staging process itself. This sort of multi-pass deduplication process retains all of the negative performance aspects of a traditional post-process implementation.
Staged Post-Process Deduplication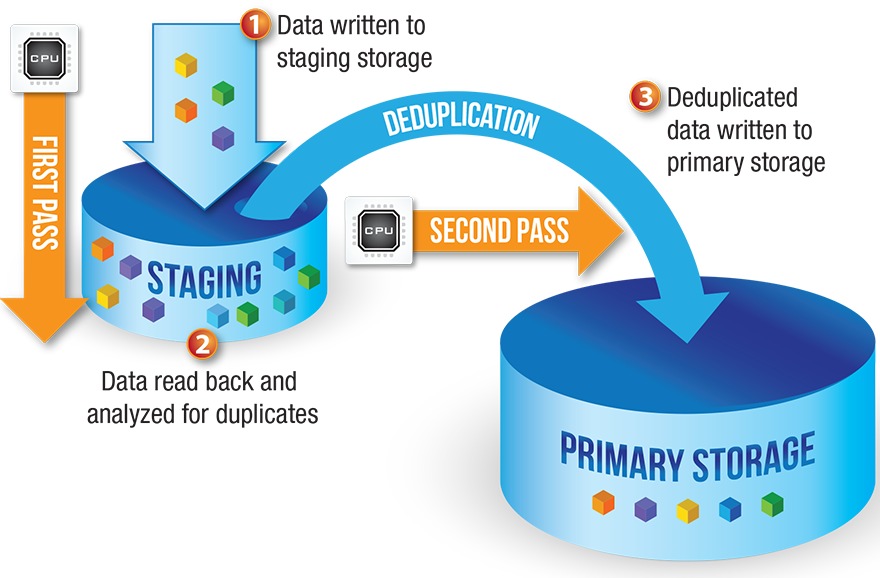
High Performance Requires Inline Deduplication
Any form of multi-pass deduplication introduces new bottlenecks that prevent an enterprise storage system from delivering the highest levels of performance. Post-process deduplication, whether on the final media or during a destaging process, creates additional overhead in both media access and data processing. For flash storage platforms requiring the highest levels of performance, only tightly-integrated inline deduplication can meet all system requirements.




 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter
