






Primary Data Updates DataSphere
Data flow automation, performance improvements, new scale-out NAS support and cloud integration
This is a Press Release edited by StorageNewsletter.com on March 10, 2017 at 2:36 pmPrimary Data Inc. announced new features that transform its DataSphere software platform into a metadata engine that automates the flow of data to help enterprises meet evolving application demands at petabyte scale.
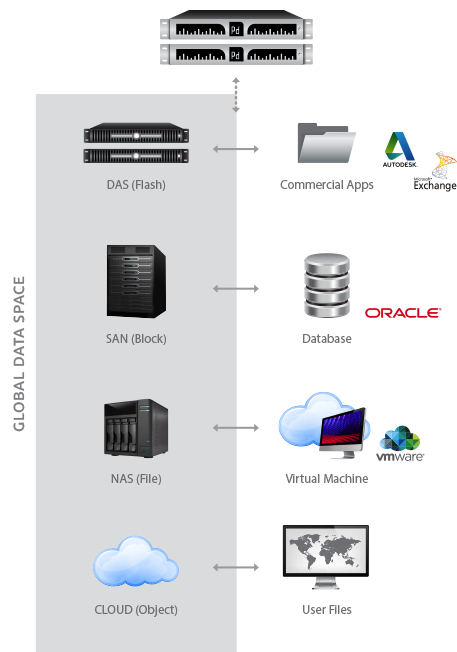
DataSphere 1.2 optimizes scale-out NAS for performance without bottlenecks, integrates easily with the cloud, automates data management, and provides client and file visibility with billions of files hosted across different storage systems.
“With DataSphere, customers are able to cut overprovisioning costs by up to 50%, and those savings easily run into the millions when you are managing petabytes of data,” said Lance Smith, Primary Data CEO. “In today’s 1.2 release, DataSphere has taken another step forward, automating the management of over a billion files as an enterprise metadata engine. With DataSphere, enterprises can significantly accelerate performance, overcome vendor lock-in, and easily leverage the cloud to maximize both savings and efficiency.”
New features in DataSphere 1.2 include:
- Automated management of billions of files enables enterprises to serve and manage data at petabyte scale
- Supercharge scale-out NAS performance for unstructured data and other NAS workloads with vendor-agnostic support for Dell EMC Isilon and NetApp ONTAP solutions
- Scale your cloud in parallel with direct interfaces for Amazon S3 and compatible cloud platforms; scale cloud uploads and downloads linearly while protecting namespace for application data access
- Offloaded cloning directly from clients preserves application performance and optimizes capacity usage
- Visibility into file and client performance with hot file visibility; real-time performance graphs across different storage resources visible on user dashboard
- Non-disruptive H/A failover and volume retrieval ensures rapid recovery without impact to ongoing I/O processing
- Faster performance with improved metadata algorithm intelligence and resource usage while continuing to maintain client I/O even while data is in flight
- Expanded support for Linux, Mac and Windows environments including Linux, macOS, and SMB support for Windows Server 2008/Windows 7 and later
“Automating the flow of enterprise data with a metadata engine like DataSphere is essential now that we create so much data every day,” said Steve Wozniak, Primary Data chief scientist. “Some data is hot and valuable, while other data quickly gets cold and needs to be kept somewhere that will keep costs low. DataSphere automatically makes sure the storage you have is always serving the right data, and makes it easy to add new resources like the cloud, even when you are managing billions of files. Simplicity like this isn’t easy to achieve, but once you find a better way, you wonder what you used to do without it.”
DataSphere enables enterprises to place the right data on the right storage at the right time across enterprise infrastructure and the cloud to automatically meet evolving application demands without interruption. The DataSphere software platform virtualizes data by splitting the control path from the data path, separating data from the underlying storage so that it can be managed independently of hardware.
By creating a global namespace that spans cloud, shared and local storage, DataSphere helps enterprises overcome performance bottlenecks without buying new hardware. Its powerful policy engine flows data to the ideal storage resource to automatically meet performance, price and protection requirements. In addition, it can monitor and move cold data to lower cost tiers like the cloud while maintaining accessibility. Moving files to fast flash resources accelerates performance and optimizes existing storage investments without disrupting applications.
Comments
Since the general availability of DataSphere a few months ago, the company continues its rapid product and market development with now large accounts with 5, 10PB or even more considering Primary Data as the data virtualization layer. This is a good sign.
This is clearly a new category, remember some times ago the industry spoke about Network File Management then Network File Virtualization, now a shift occurred to be more data-centric around the [network] data virtualization idea. And the company is obviously a key player in that new wave.
As Lance Smith told us recently: "We don't touch the data, we manage meta data", and this few words illustrate the magic DataSphere and the rest of components can do for you. This is their intelligence now able to super scale in term of number of files thanks to RocksDB for meta data store. Beyond pretty classic metrics such IO/s, BW..., for data intensive environment met adata ops/s is a key metric to observe and we invite to use this metric to compare the impressive numbers delivered by the firm with other offerings.
Beyond the management capabilities such data mobility, it's important to keep in mind this parallelism effect for files. In fact instead of storing one file on one file server, the file is itself chunked at the client level to be stored on different file servers boosting the response drastically.
So in addition to benchmarks about the effect of DataSphere, it would be good to imagine a very simple test with N files with one file server i.e without the product and N files sending to M file servers with DataSphere as the orchestrator of this file content distribution (distribution of files or distribution of chunks of files).
We think it would illustrate the Primary Data effect with full investment protection of the back-end.



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter


