






Benchmarks Show Diablo Technologies’ Memory1 Doubles Speed of Apache Spark Graph Processing
Users can get more work done with existing resources, minimize server sprawl, and improve TCO.
This is a Press Release edited by StorageNewsletter.com on February 10, 2017 at 2:46 pmDiablo Technologies, Inc. and Inspur Systems Inc. announced benchmark data showcasing the benefits of the Memory1 solution for Apache Spark workloads.
 By increasing the cluster memory size with Memory1, the companies were able to cut processing times for graph analytics by half or more.
By increasing the cluster memory size with Memory1, the companies were able to cut processing times for graph analytics by half or more.

Apache Spark’s open-source platform enables high-speed data processing for large and complex datasets. The joint benchmarking used the k-core decomposition algorithm of Spark’s GraphX analytics engine, a particularly stressful series of memory-intensive tests. Previous joint collaboration demonstrated the advantages of Memory1 for Apache Spark Streaming.
The graph testing on Memory1 highlights that users can achieve more work per server and reduce the time needed to process increasingly larger datasets than servers with DRAM alone. As a result, users can get more work done with existing resources, minimize server sprawl, and improve TCO.
Inspur NF5180M4

Behind tests
The companies tested Apache Spark (version 1.5.2) k-core decomposition performance on the same cluster of five servers (Inspur NF5180M4, two Xeon CPU E5-2683 v3 processors, 28 cores each, 256GB DRAM, 1TB NVME drive). The servers were first configured to use only the installed DRAM to process multiple datasets. Next, the cluster was set up to run the tests on the same datasets with 2TB of Memory1 per server.
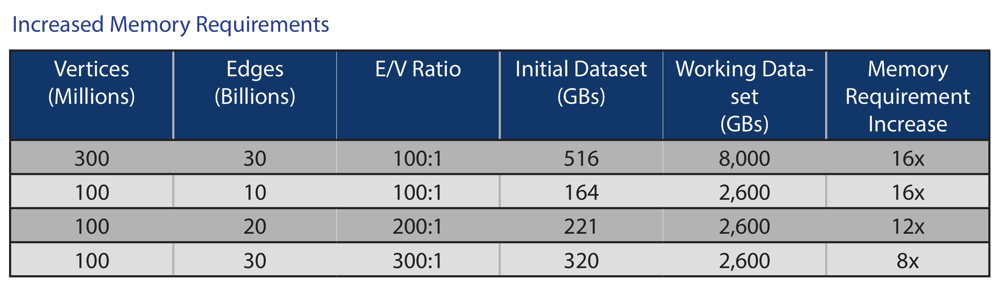
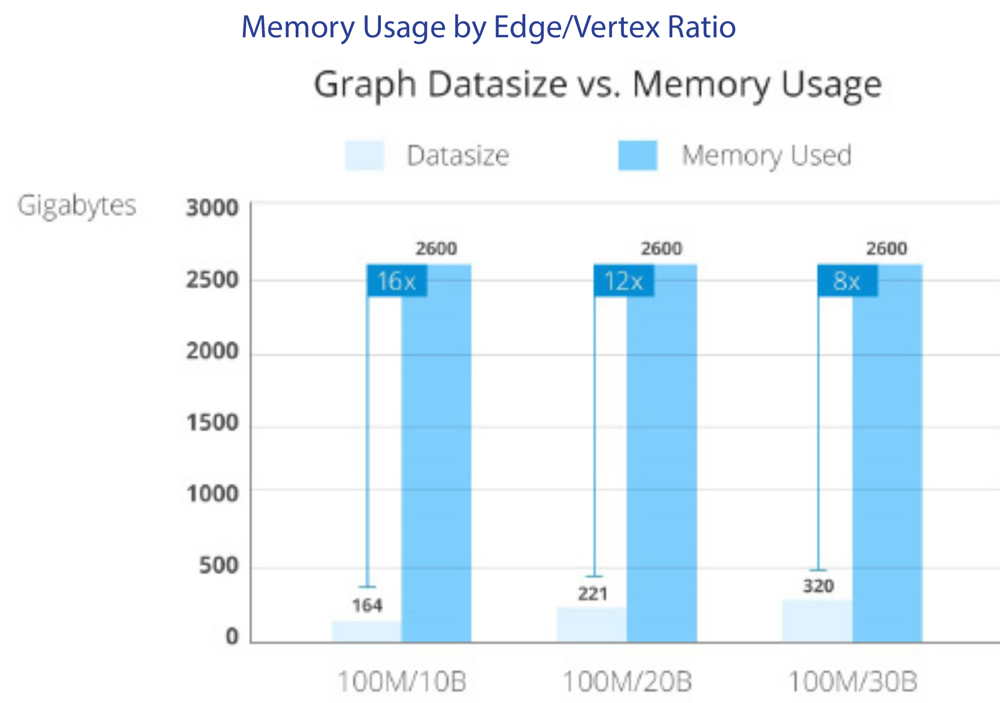
k-core algorithm in Apache Spark was run against three graph datasets of varying sizes:
-
164GB set of 100 million vertices with 10 billion edges
-
340GB set of 200 million vertices with 20 billion edges
-
516GB set of 300 million vertices with 30 billion edges
Results
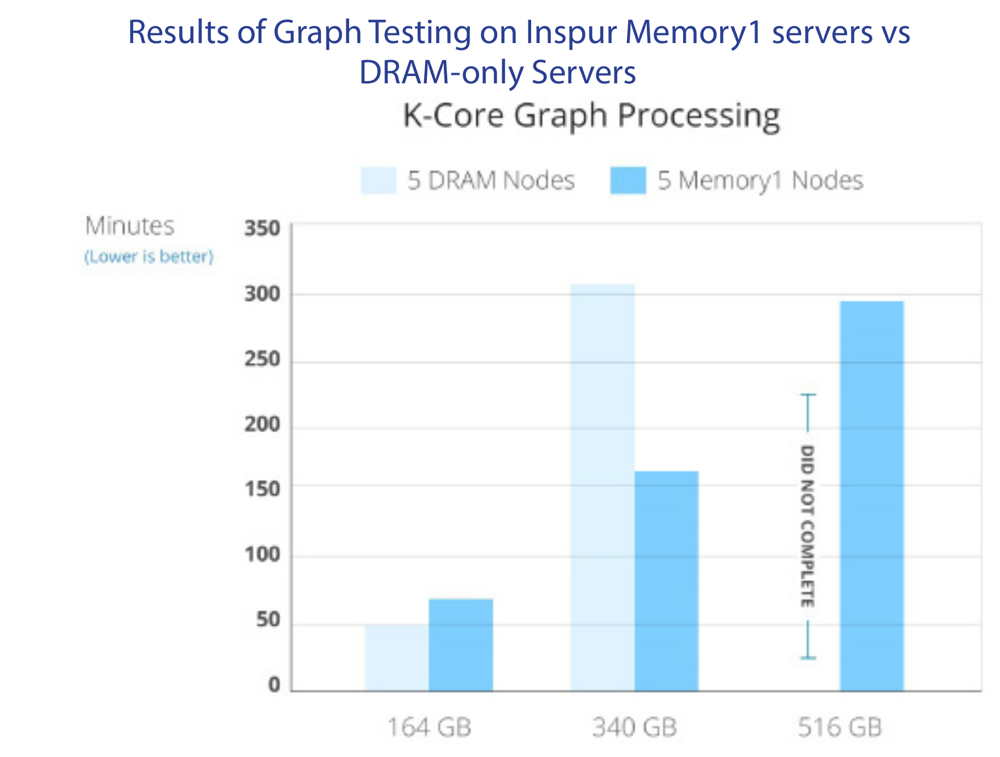
As illustrated in the chart above, completion times for the smallest sets were comparable. However, the medium-sized sets using Memory1 completed twice as fast as the traditional DRAM configuration (156 minutes versus 306 minutes). On the large sets, the Memory1 servers completed the job in 290 minutes, while the DRAM servers were unable to complete due to lack of memory space. As the data set grew, Memory1 results were several factors beyond what DRAM could do alone.
Click to enlarge
“While we anticipated a substantial performance improvement with Memory1, what’s notable is that as the dataset scaled, the cluster without Memory1 failed,” said Maher Amer, CTO, Diablo. “This clearly illustrates the complexity and risk of analytics on big data workloads. Graph processing is the latest use case that shows the benefits of expanded memory in addition to SQL queries, machine learning, and streaming.“
“Inspur Memory1 Servers have shown that they are the best solution on the market to complete analytics processing of big data tasks and are a necessary infrastructure for Apache Spark,” said Alfie Lew, solutions architect, Inspur. “These results are exciting for the big data world, and we look forward to demonstrating more impressive results on additional memory-intensive applications.“
Click to enlarge
Inspur Memory1 servers use Diablo’s high-capacity flash-as-memory DIMMs and memory management software to enable more work per server. Memory1 scales up memory resources, delivering up to 40TB of application memory in a single rack. More efficient and resource dense servers means improved real-time analytics, faster business decisions, and more transactions completed in a shorter amount of time. The net result provides users with the flexibility to address evolving business needs and technologies at a lower TCO.
Resources:
Memory1 Server



 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter

