







MapR Introduces Auto-Provisioning Templates
To speed deployment of Hadoop clusters
This is a Press Release edited by StorageNewsletter.com on June 19, 2015 at 2:34 pmMapR Technologies, Inc. announced a software module to accelerate the provisioning and deployment of big data solutions.
Click to enlarge
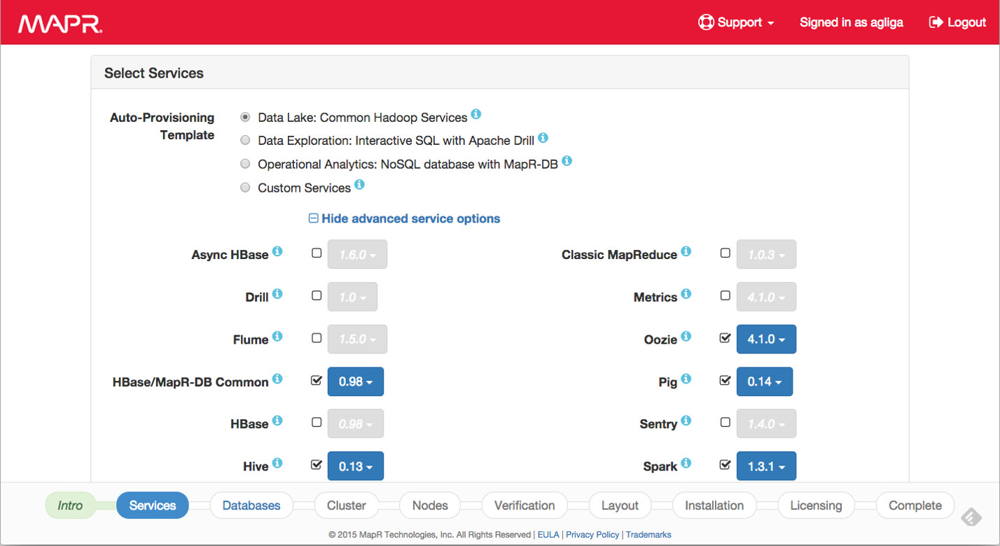
The Auto-organisation Templates apply software-defined concepts that will enable organizations to quickly deploy a cluster with appliance-like convenience and with the flexibility and choice of building a custom, enterprise-grade data platform.
Auto-Provisioning Templates provide organizations with flexibility to deploy purpose-built big data solutions on their hardware infrastructure of choice, whether it be directly on hardware servers from a variety of vendors, a virtualized private cloud, or a public cloud provider. The Auto-Provisioning Templates provide the simplicity of appliances yet also support the efficiency and hardware diversity that production Hadoop clusters typically require. The Auto-Provisioning Templates also let customers expand their deployment at increments they define and need, rather than at the homogeneous ‘stair-step’ increments that a rack-based appliance requires.
“The MapR Auto-Provisioning Templates leverage software-defined concepts to create a new kind of appliance for modern, real-time Hadoop applications,” said Anil Gadre, SVP, product management, MapR. “Customers are asking for software-defined abilities to address many of their business and IT objectives. We’ve simplified that process and enable organizations to choose the components they want to meet their big data infrastructure needs.“
Auto-Provisioning Templates define the software, network and hardware attributes of a single node, as well as support diverse definitions required across many nodes. Auto-Provisioning Templates support the deployment of the following configurations:
-
Data Lake: common Hadoop services – Includes common services deployed in an Apache Hadoop cluster, including YARN, MapReduce, Spark, and Hive-all on top of the big and fast MapR Data Platform for getting started with a Hadoop data lake.
-
Data exploration: Interactive SQL with Apache Drill – Provides services needed for users to perform schema-free interactive exploration of their data, including Apache Drill.
-
Operational analytics: NoSQL database with MapR-DB – Deploys the MapR distributed NoSQL database, enabling both operational HBase applications to read and write data at high rates, and analytic applications to perform in-situ data processing.
Users deploy Auto-Provisioning Templates via the MapR Installer, which further simplifies the deployment of company’s software by providing:
-
Auto-layout – Hides the complexity of deciding how to best distribute Hadoop and other services across servers, selecting the optimal layout for the services selected and hardware provided
-
Rack awareness – Automatically distributes critical services across failure domains
-
Health checks – Executes a suite of tests on all servers to ensure they will perform optimally after installation, and warns users of potential issues




 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter
