







Data Platform V2.5 From Splice Machine
OLAP engine adds columnar storage and in-memory caching to hybrid relational data platform, capabilities supercharge analytical workloads while powering transactional applications.
This is a Press Release edited by StorageNewsletter.com on December 7, 2016 at 3:14 pmSplice Machine, Inc. has announced at AWS re:Invent 2016 the version 2.5 of its data platform for intelligent applications.
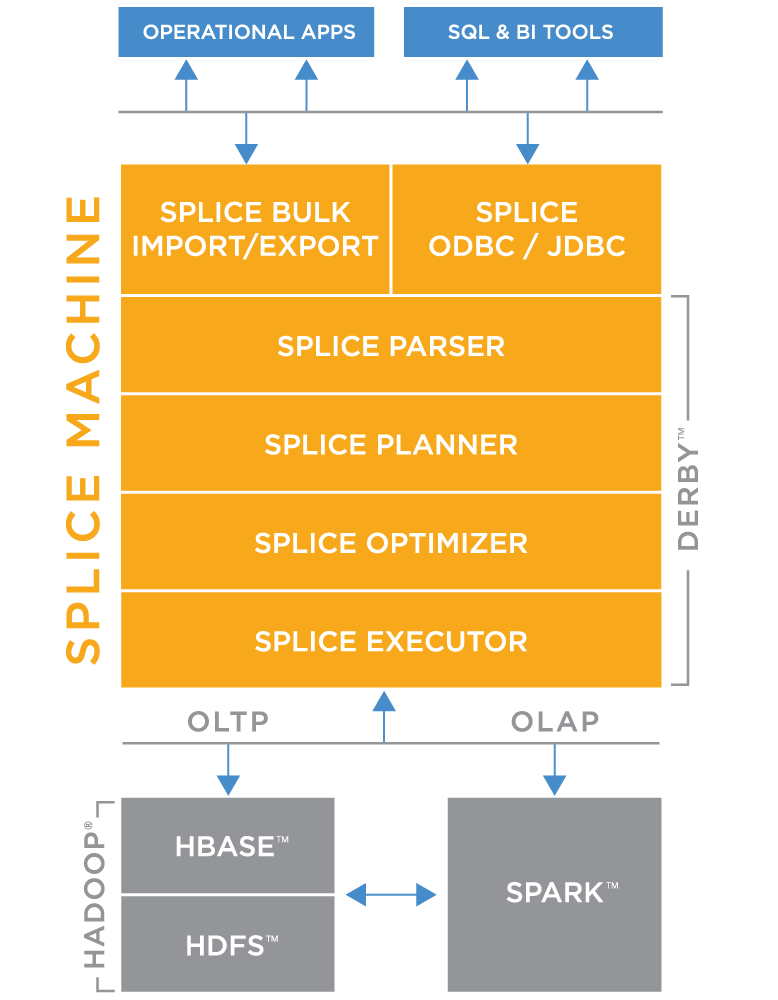
This version strengthens its ability to concurrently run enterprise-scale transactional and analytical workloads, frequently referred to as HTAP (Hybrid Transactional and Analytical Processing).
“The new capabilities further emphasize the benefits of Splice Machine’s hybrid architecture,” said Monte Zweben, co-founder and CEO, Splice Machine. “For modern applications that need to combine fast data ingestion, web-scale transactional and analytical workloads, and continuous machine learning, one storage model does not fit all. The Splice Machine SQL RDBMS tightly integrates multiple compute engines, with in-memory and persistent storage in both row-based and columnar formats. The cost-based optimizer uses new advanced statistics to find the optimal execution strategy across all these resources for OLTP and OLAP workloads.“
With firm’s hybrid architecture, companies can:
-
Simplify operational complexity – Users can avoid managing separate systems, tuning them individually for performance, and writing low-level code and batch programs to keep them in sync.
-
Eliminate need for special coding skills – Developers can use a single industry-standard SQL and JDBC/ODBC interface to work with the system.
-
Power concurrent applications – The ACID transaction implementation is designed for both analytical and operational workloads. This means that it supports high concurrency with thousands of users or devices updating the system at the same time. Its MVCC, using snapshot isolation, can handle fine-grained updates without locking reads.
-
Support machine learning – Modern applications adapt over time by continuously transforming operational data into aggregated features that train statistical machine learning models and deploy those models in real-time decision systems. The company enables the feature engineering, model selection, and deployment process to take place on one platform without significant data movement.
At AWS re:Invent 2016, the firm demonstrated how users benefit from these capabilities on AWS, by integrating multiple compute and storage engines into an elastically scalable database that can be a relational database and a data warehouse in one. An AWS Sandbox is available to companies that want to test these capabilities for themselves.
Click to enlarge
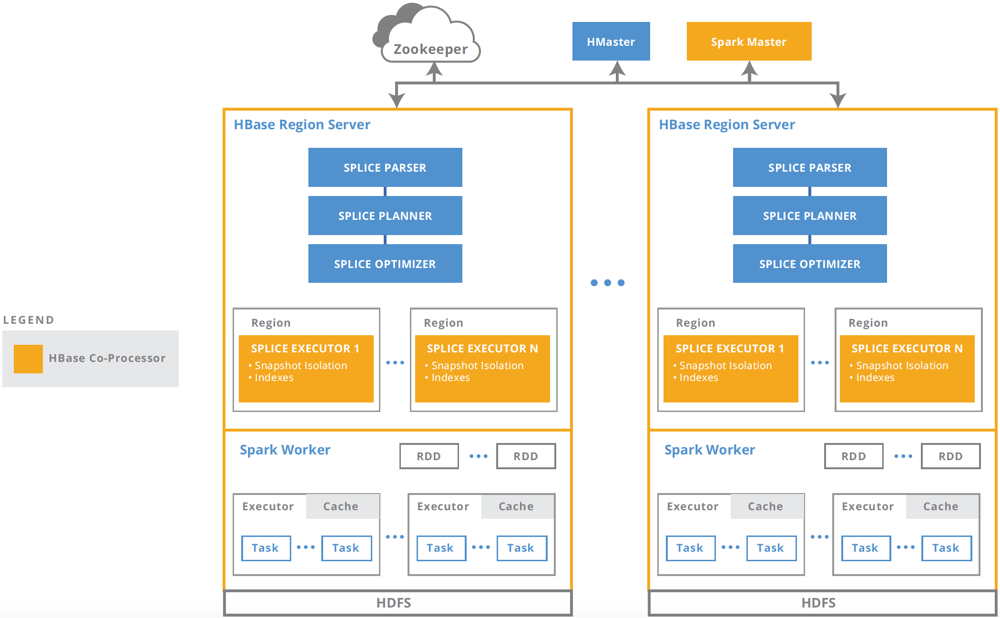
Version 2.5 introduces capabilities:
-
Columnar external tables enables hybrid columnar and row-based querying. They can be created in Apache Parquet, Apache ORC or text formats. Columnar Storage improves large table scans, large joins, aggregations or groupings while the native row-based storage is used for write-optimized ingestion, single-record lookups/updates and short scans.
-
In-memory caching via pinning gives the ability to move tables and columnar data files into memory for lightning-fast data access. It avoids multiple table scans or writes to high-latency file systems such as Amazon S3. The capability allows data to be stored on inexpensive storage while being performant in-memory when required in applications.
-
Statistics via sketching helps solve the age-old problem that cost-based optimizers are only as good as their statistics, but most statistics are poor because statistics computation is expensive. The company solution utilizes the sketching library created by Yahoo! to provide fast approximate analysis of big data statistics with bounded errors. Now with the power of sketches and histograms, the firm’s solution cost-based optimizer can choose indexes, join orders, and join algorithms with more accuracy.
-
Cost-optimized storage for AWS users. Data can be stored locally in ephemeral storage, on EBS, S3 and EFS. Depending on the workload and longevity of data, different data can be stored in different storage systems with different price/performance characteristics.




 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter
