







Sector Roadmap: Object Storage for Enterprise Capacity-Driven Workloads – Gigaom Research
Disrupting vendors: HDS, Scality, EMC, Caringo, DDN, NetApp, RH Ceph, Cloudian, SwiftStack
This is a Press Release edited by StorageNewsletter.com on June 13, 2017 at 2:23 pm This report was written by Enrico Signoretti, analyst, advisor and blogger, founder of Juku Consulting and head of product strategy at OpenIO Italy for Gigaom, a technology research and analysis firm.
This report was written by Enrico Signoretti, analyst, advisor and blogger, founder of Juku Consulting and head of product strategy at OpenIO Italy for Gigaom, a technology research and analysis firm.
Sector Roadmap: Object storage for enterprise capacity-driven workloads
Summary
During the first decade of this century, we shifted fairly quickly from a relatively simple set of storage technologies and implementations to a very large spectrum of options, with vendors proposing solutions for all kinds of data and applications. They are responding to an increasing demand for storage specialization, introduced by the necessity for overall efficiency, cost reduction, and today’s large capacities.
In such an evolved scenario, the Swiss army knife approach no longer works. Cloud, IoT, big data analytics, virtualization, containers, active archives as well as laws, regulations, security concerns, and policies are the driving forces which lead to reconsidering all aspects of data and how it is saved. Furthermore, each single application has different workload characteristics and must be addressed accordingly in order to stay competitive and respond quickly and adequately to new challenges. Data is now accessed locally as well as remotely, adding another layer of complexity when the same piece of information needs to be shared quickly and safely to a multitude of devices distributed across the globe.
A two-tier storage strategy is essential now for covering both latency-sensitive and capacity- driven workloads in an appropriate way.
This sector roadmap examines an expanding segment of the market-object storage for secondary and capacity-driven workloads in the enterprise by reviewing major vendors, forward-looking solutions, and outsiders along with the primary use cases.
This document covers Scality, SwiftStack, EMC ECS, RedHat Ceph, HDS HCP, NetApp StorageGRID Webscale, Cloudian, Caringo, DDN, HGST, and will give additional information on products from OpenIO, NooBaa, IBM Cleversafe, and Minio.
The final goal is to provide the reader with the tools to understand the benefits of object storage and how it can be implemented to solve specific business needs and technical challenges. This report will also aid a better understanding of how the market is evolving, and offer support for developing a long-term strategy for existing and future storage infrastructures.
Key findings in our analysis :
• Amazon S3 API is the de facto standard. The level of compatibility is not the same for all products, but it is becoming less of a differentiator, with some vendors showing a very high level of compatibility and others quickly catching up.
• In traditional enterprise organizations, scalability is not considered a major issue but scale-out is important. In fact, most enterprises initially adopt object storage for a single use case and for less than 200TB. Over time it is deployed for more use cases, increasing the capacity. Multi-petabyte environments are becoming more common but are still a very small fraction of the overall installed base.
• Cloud tiering capability is considered a benefit but in practice it is used only to manage temporary capacity bursts.
• End-to-end integrated solutions are favored by enterprises and end users who prefer ease of use as opposed to best-of-breed.
• End users like the idea of pre-integrated appliances but are now much more confident than in the past with the storage-only approach.
• Lately, most of the basic features (data protection, availability, API compatibility, UI) are taken for granted and the $/GB metric is considered a major ‘feature,’ especially if the primary use case for the object store is to be a back-end repository for a third party application (i.e. Backup).
• NFS and Server Message Block (SMB) access protocols, via native connectors or gateways, are now a key feature for all those end users who are planning to deliver traditional file services and want to access data via different methods.
Click to enlarge
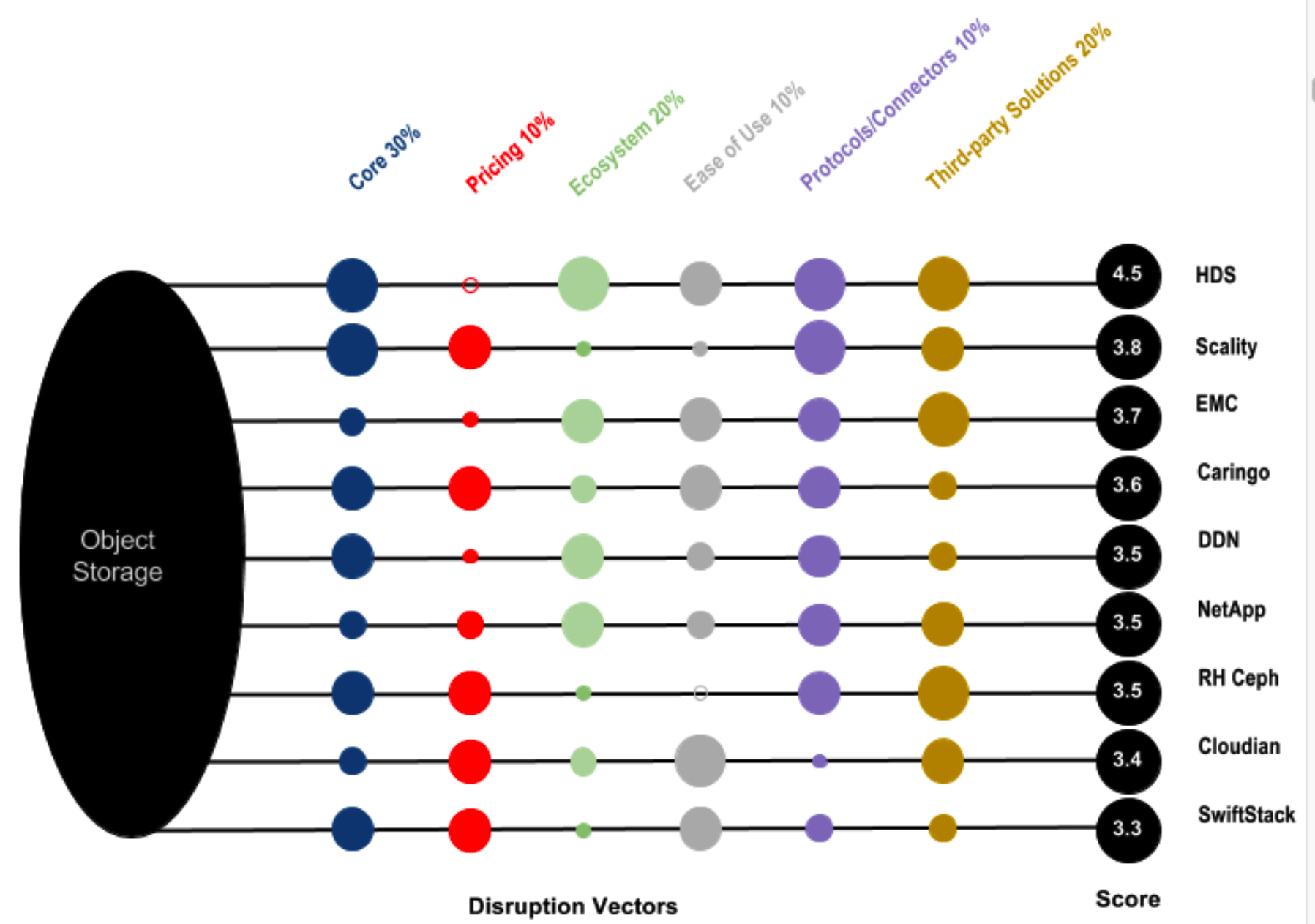
Key:
• Number indicates company’s relative strength across all vectors
• Size of ball indicates company’s relative strength along individual vector
Introduction and Methodology
The major challenge facing most organizations today is that traditional storage infrastructures no longer suffice to cope with high demanding workloads imposed by the huge amounts of data being stored and the low latency required for frequently accessed data. It is estimated that 80% of data is unstructured (mostly files), while the rest is structured. These numbers are growing exponentially and quickly verging towards an even greater percentage of unstructured data. Finding solutions that can meet capacity-driven or latency-sensitive workloads becomes crucial.
Data mobility is another significant consideration. It is fundamental for building a sustainable infrastructure that can seamlessly handle the right data placement in relation to the application, its age, access frequency, the device accessing it, and its location.
Basic storage features like data protection or replication, for example, are now taken for granted and seen as the minimum table stake, as are data services, which are no longer considered a differentiator. On the other hand, especially for primary storage, storage analytics and automation are currently playing an important role, with new innovative features becoming appealing for enterprises looking at a hybrid cloud model as a reference for their architecture.
End users are looking for efficient storage infrastructures that are easy to manage with minimal effort and plenty of automation. Moreover, with containers starting to be considered part of the game as a viable computing model for the future, there are two important aspects to consider: first, in the vast majority of cases, containers are now deployed only for software distribution; second, in the long term, stateful containers will need persistent storage. Block access is a solution, but many developers are also looking favorably at object stores because it allows them to have better data mobility and can be accessed via APIs.
Object storage allows consolidation of a large number of local and remote data repositories in a single larger one, which is more reliable, available, and easier to protect. Most object storage platforms available in the market have embedded geo-replication and advanced data protection mechanisms, enabling a multi-datacenter/region configuration with minimal effort. On-premises object storage is also the right back-end for private cloud storage services, especially in European countries where laws and regulations are strict in terms of data locality.
Methodology
For our analysis we have identified and assessed the relative importance of six Disruption Vectors. These are the key technologies used by players who strive to gain advantage in the sector. Tech buyers can also use the Disruption Vector analysis to aid them in picking products that best suit their own situation.
The Disruption Vectors section of this report features a visualization of the relative importance of each of the key Disruption Vectors that Gigaom Research has identified for the enterprise object storage marketplace. We have weighted the Disruption Vectors in terms of their relative importance to one another.
Gigaom’s Research analysis process also assigns a score from 1-5 to each company for each vector. The combination of these scores and the relative weighting and importance of the vectors drives the company index across all vectors. The outcome is the Sector Roadmap chart found in the company analysis section.
Usage Scenarios
For this report, Gigaom Research has found three different common use cases that particularly interest end users adopting enterprise object storage, and three other key areas to look at in the near future. In most cases end users start with only one application or use case but over time, the same infrastructure is leveraged to cover all of the common use cases and more.
File Services consolidation
The TCO of traditional file storage systems is becoming unsustainable as distributed organizations want to cut costs and have more control over data. At the same time, with data accessed anytime from everywhere, organizations need to improve service levels and RTO/RPO in case of disaster, and increase the security level as well.
Most object storage vendors now offer virtual or physical gateways for remote offices, maintaining the same user experience but with tremendously improved security, DR and overall costs. A local cache provides the required performance, while all data is sent to the back-end object store. The gateway is stateless and does not need backup and/or DR plans.
Enterprise collaboration
The vast majority of end users work on mobile devices now and want to be productive on any device, at anytime, anywhere. Enterprise Sync & Share, integrated with Microsoft Active Directory, gives the user the same experience as consumer services like Dropbox, but with enterprise grade security and compliance with company policies.
Some object storage vendors have end-to-end solutions, which are preferable in smaller installations. On the other hand, third-party solutions are usually more sophisticated and offer additional features, but can also be more complex to manage.
Backup repository
Traditional virtual taple libraries (VTLs) do not scale enough and are expensive, with a $/GB that is usually higher than public or private object stores. More and more data, especially unstructured data, is now saved in compressed and/or encrypted formats, a situation in which further compression and deduplication do not improve space utilization. Large organizations still rely on tape for long term backup and archive, which has drastically lower costs than any other storage media, and stable reliability in the long term. As a result, S3 protocol is very common among backup software products and VTLs can also have a S3 compatible interface.
This use case is becoming more common in large enterprises. With object storage systems that can now interface directly with tape libraries and take advantage of their tiering mechanisms, data movements are seamless and transparent to the backup application. $/GB is extremely low and requires less management efforts.
IoT – Big Data Lake Foundation
Enterprises are collecting data and starting to build data lakes. In some cases, their big data analytics strategy is not clearly outlined yet; they are only saving data for future use. In other cases, different departments use different tools but some of the data can be shared. IoT initiatives are set to produce even more data at an incredible pace.
Object storage is becoming more common among these customers, who are adopting it for the low $/GB, high manageability of large repositories, and unmatched scalability.
Some object storage vendors have Hadoop Distributed File System (HDFS) interfaces that allow compatibility with Hadoop/HDFS clusters, but S3 is now also well-supported by some Hadoop distributions. Again, the winning factor is $/GB – although the high throughput that object storage can achieve in large configurations are not to be underestimated.
For example, log analytics is a specific use case in big data analytics, and it is true that large datacenters are trying to consolidate all logs in single large repositories, using specific tools to get real time monitoring and security insight, as well as useful trends for resource capacity planning. These logs are sometimes stored for long periods of time for future auditing or just compliancy.
Primary and secondary storage integration
Many primary storage vendors are working on solutions to transparently off-load unused data to object storage (long-term retentions, snapshots, clones, etc.). This can be seen as an instant backup/recovery option and as a way to save money on precious all-flash storage. Alternatively, in other cases, data replication is implemented, and this data movement mechanism can be used to move data to and from the cloud or as a DR option.
Advanced data services
Metadata search is a valuable feature that is becoming more of interest; enterprises are looking at it to build easy-to-use self-service portals in several areas like e-discovery, auditing, security and so on.
With the serverless computing paradigm experiencing some success in the public cloud, enterprises could take advantage of a similar approach with their on-premises infrastructure. Operations on objects can trigger functions (micro-services) which can offload data-intensive tasks directly onto the object storage infrastructure, with the positive outcome of improving the overall efficiency by offloading some application logic to the object storage system.
This is not an exhaustive list of all object storage use cases, of course, but are those that are getting most of the attention from end users.
Disruption Vectors
Object storage is clearly experiencing a positive trend in enterprise adoption after years of success in web-scale and vertical market segments. The key features in enterprise environments, however, are slightly different from what we have seen in the past for service providers and large scale applications. Enterprise users are still at the beginning of a transitional phase towards API-accessed storage. Most of the applications in use are still based on legacy protocols and API access is mostly used by third-party gateways or applications. A very limited number of end users have developed, or are in the process of developing, applications which are able to access object storage directly via APIs. This is why we have worked on a set of specific disruption vectors that reflect this situation.
The six vectors we have identified are:
• Core architecture
• Pricing model
• Ecosystem
• Ease of use
• Additional protocols and connectors
• Third-party support
Core architecture
Most of the basic features are common to all object storage systems, but the back-end architecture is fundamental when it comes to overall performance and scalability. Some products available in the market have a better scalability record and show more flexibility than others when it comes to configuration topology, flexibility of data protection schemes, tiering capabilities, multi-tenancy, metadata handling, and resource management. Some of these characteristics are not very relevant to enterprise use cases, especially when the size of the infrastructure is less than 1PB in capacity or built out of a few nodes. However, in the long term, every infrastructure is expected to grow and serve more applications and workload types.
Core architecture choices are not only important for scalability or performance. With better overall design, it is easier for the vendor to implement additional features aimed at improving the platform and thus the user experience as well.
Pricing model
In this report we have considered software-only solutions. Some vendors also provide a hardware version of the product but the price of pre-packaged appliances is usually higher than the sum of the components. It is less flexible from both the configuration and financial point of view, and usually relies on expensive support services which drive up the TCO of the infrastructure.
All-inclusive pricing models are usually more interesting and cost effective than having a base price plus options. Capacity-based licenses are preferable in enterprise environments as customers do not usually need very high dense nodes. Open source solutions generally adopt a yearly subscription fee for support services, which means shifting costs to OPEX, a shift seen favorably by most customers.
Ecosystem
Historically, enterprise customers prefer end-to-end solutions. In this report we have favored vendors who can provide integrated solutions, especially in the field of file services and collaboration tools like Sync & Share.
At the same time, especially when it comes to primary vendors, it is important to note that some of them have integrations with other products in their portfolio, facilitating data movements from primary to secondary storage.
Ease of use
Contrary to what happens with large service providers, who usually prefer API-based management, enterprises are still more confident with GUIs, and this is also true when it comes to the installation and deployment of new nodes: the easier, the better. The limited number of nodes taking part in a cluster do not usually justify a heavy scripting activity, and the skills available are not always sufficient to manage orchestration and configuration management tools.
Protocols and connectors
Nowadays, the most important protocol for object storage is Amazon S3. This is the de facto standard and the most widely used. Unfortunately Amazon is not very collaborative with other vendors, and the compatibility of some products is still scarce. This could make it difficult for end users to get the object storage infrastructure certified and working with all the third-party solutions available. However, vendors are improving this aspect and in the medium/long term, the level of S3 compatibility should become less of an issue. Most vendors also provide additional proprietary APIs and compatibility with Swift, even if there is little interest from end users and third parties in their adoption.
NFS and SMB connectors or gateways are becoming more and more popular, but the implementations are very different. In some cases, traditional file access is a way of giving the end user visibility of the same data concurrently as files and objects, which is very useful when the end user wants to maintain access from legacy and modern applications at the same time. In other cases file access is provided to leverage the characteristics of reliability and the economics of object storage back-end for file services consolidation or scale-out NAS applications.
Third-party support
Thanks to the success of object storage in the public cloud, now there are many ready-to-use services, applications, and gateways that can also be adopted in on-premises environments. Unfortunately, not all vendors have the same number of partnerships with third parties regarding certified solutions and best practices to make two products work together seamlessly. Even for the largest single vendor ecosystem, third-party solutions can be more capable and cost effective, depending on the use case, the number of users, and specific features. Ultimately, freedom of choice remains one of the most important aspects for a platform that can easily become a hub for all secondary storage needs.
Company Analysis
We have chosen ten vendors that represent a variety of viable approaches for delivering on- premises object storage systems to enterprises. Each one of these vendors offers a strong set of features and recently, much more focus on enterprises than in the past. Despite different architecture and scalability characteristics or market segment positioning, they all offer similar basic features which make them suitable for several of the use cases described earlier in this report.
Caringo Swarm
Caringo is a US-based start-up founded in 2005, with more than 600 customers, which makes them one of the sector leaders in terms of number of installations. The average size of their customers is fairly small; however, this is to be expected because while they have a number of web-scale customers, the majority are in the enterprise space or specific verticals.
The product, into its 9th generation, is available as either software-only or appliance. The appliance is sourced through Dell OEM and Dell is also a reseller of the appliance and software. Minimum configuration is three physical nodes but some customers have installations of hundreds of nodes and several petabytes in capacity. The licensing model is on a capacity basis plus support, which is offered through perpetual or service-based models.
The web user interface is quite simple to use and generally customers have reported dedicating little time to cluster maintenance, even when the product is used as a back-end for file services consolidation in large distributed environments. The Swarm ecosystem includes a smart file service gateway FileFly, which can be installed on remote Windows servers or connected to NetApp filers, offering a seamless integration between file services and object storage back-end, and Swarm NFS, an efficient connector that converts files to objects enabling multi-protocol editing and access functionality as well as automated content distribution. SDKs are available but unfortunately the company does not provide any other enterprise-ready tools. Their good partner ecosystem helps when it comes to Sync & Share and backup solutions.
Caringo Swarm also includes metadata search capabilities through the integration of Elasticsearch and an HDFS interface as well as S3 and Swift APIs support, but lacks cloud tiering capabilities (which will be added in 2017).
Cloudian HyperStore
Cloudian has built its reputation around S3 compatibility, which is still one of the best in the market. The back-end architecture does not have a particularly intriguing design, with a NoSQL engine managing all metadata, while objects are saved externally. That said: the product front-end and the feature set are solid, used by more than 100 customers in production with several clusters in the multi-petabyte range. The user interface is well designed and simple to use with good analytics tools.
Multi-tenancy and QoS features, alongside an integrated billing/chargeback mechanism, make this product ideal for enterprises and service providers that want to consolidate multiple services on a single platform. A cloud tiering option is available for customers wanting to implement a hybrid solution.
Cloudian does not offer a good solution ecosystem, with file services (NFS and SMB) provided through an OEM product. On the other hand, thanks to the top-notch S3 compatibility, HyperStore is certified with a very large number of third-party solutions. On a positive note, support services are highly rated by end users. HDFS, metadata indexing, and search capabilities contribute to making HyperStore an ideal companion for big data infrastructures.
The product is available as hardware appliance as well as software-only, with a long list of certified hardware vendors. Licenses are available on a capacity-basis model plus support, starting at 10TB, and a trial license is also available.
DDN WOS 360
WOS 360 is to be considered as a high-end solution. It is aligned with the rest of DDN’s products in terms of positioning (HPC and big data applications), performance, and scalability. The level of integration with other storage systems in the product line-up is remarkable and the architecture is very well designed.
Additional software options offered by DDN allow connecting WOS 360 to NAS systems of primary vendors for policy-based tiering, data migrations, and archiving.
All major protocols are supported and a new S3 connector with improved compatibility was added at the beginning of the year. WOS 360 also has an easy-to-use UI with real-time analytics dashboards to monitor the state of the cluster as well as multiple metrics regarding its utilization.
DDN does not offer native enterprise-ready solutions like Sync & Share or remote NAS capabilities, but it does have a good number of certified partners to cover these kinds of requests.
WOS 360 is available as software-only or pre-packaged appliance. It is licensed on a per node basis which makes the product very competitive when it comes to very large installations based on large server nodes, but makes it too costly for small infrastructures. Despite this licensing limitation, the product has performed very well with more than 180 installations.
HDS HCP
The HCP (Hitachi Content Platform) is one of the most successful enterprise object storage platforms in the market. It has more than 1,700 customers, with an average cluster capacity between 200 and 300TB.
The back-end architecture of the product is rather old and not very scalable, but HDS has been able to build a well-conceived ecosystem around the core product, making this limitation less relevant. In fact, the ecosystem is built out of hardware and software solutions, with S10 and S30 S3-compatible Ethernet-attached economy storage nodes that can easily drive up storage capacity.
This approach is made possible by advanced tiering mechanisms available in the system, which can also move data to other S3, Google, and Microsoft-compatible object stores. Alongside the hardware ecosystem, HDI (remote NAS gateway) and HCP Anywhere (Sync & Share) stand out for the quality of their integration and feature set. Third-party certified solutions and a large number of best practices to leverage HCP in many use cases complete the picture. HCP can also be used as a near-line storage back-end for other HDS products such as HNAS (Hitachi Networked Attached Storage). Tiering to tape is also supported, as is indexing and analytics functionalities.
The product is available as software or hardware. However, the software version is distributed via pre-installed VM templates, limiting its use cases and scalability and impacting the overall $/GB. Licensing is quite complex, and generally the price is not all that competitive. On the other hand, end users choosing HDS HCP are usually more interested in the overall quality of the solution in terms of features and proven enterprise support rather than in $/GB.
EMC Elastic Cloud Storage
Elastic Cloud Storage (ECS) is the latest of a long series of attempts on EMC’s part to have a successful product in this space. It is offered as both a pre-packaged appliance or a software-only version. It is actually impressive on paper but feedback from the field is not always as positive. Despite the aggressive sales policy, which inevitably increases the number of licenses sold, the number of active customers is around 250 (still impressive though, considering the age of the product).
The S3 connector has been improved in terms of compatibility in latest releases of the product, but NFS still shows instabilities and scalability issues. Integration with the rest of the product line-up is in the makings and end-to-end solutions (CloudArray remote NAS gateway, for example) and advanced data services (like metadata indexing, searching, and analytics) are on par with the competition. EMC still resells Simplicity (an enterprise Sync & Share solution) but even though the relationship between the two companies is very close, Simplicity has to be considered a third-party solution.
Partner ecosystem is very comprehensive, including a large set of ISVs and front-end gateways.
The user interface is quite effective, displaying a modern graphic design and dashboards that display all the important information about the cluster at a glance.
NetApp StorageGRID Webscale
NetApp has drastically changed its overall strategy in the last couple of years and is now focusing its efforts on a much more open-minded approach toward platform diversification and data mobility than in the past. StorageGRID Webscale is part of this strategy (called Data Fabric) that in general, also includes public cloud object storage and SaaS services.
After a few years of stagnation, StorageGRID Webscale has seen major improvements in the last eighteen months. The core product architecture design is oldish and less appealing compared to more modern products currently available on the market, but does not present scalability and performance issues, and the average cluster size in enterprise environments is generally lower than for service providers and web companies. A new sophisticated policy engine utterly simplifies data and back-end Information Life-cycle Management (ILM).
New product versions are released every six months and the ecosystem is growing as well. In fact, Storage GRID Webscale is compatible with a large range of NetApp products such as AltaVault (Cloud Backup gateway) and SolidFire for snapshots offload; others are planned to be released soon such as FAS ONTAP tiering, Snapmirror (remote replication from primary storage), and so on. Furthermore, the product includes a free remote NAS gateway that is distributed in the form of VMs for moving files into an object store.
Common interface protocols are supported. The GUI, far from being the best in the market, is now improving. The installation process has been simplified and vastly improved in the current version of the product, as has its performance (especially visible in smaller clusters). S3 compatibility is another aspect that has been given particular attention in the latest version.
StorageGRID Webscale is available as a pre-packaged appliance as well as software-only. As it usually happens for primary vendors, $/GB is not the best of the lot but the all-included licensing model, per one TB increments, could be very attractive in some circumstances and for most enterprise customers, the focus is more on front-end functionalities than on other aspects.
Red Hat Ceph Storage
After the acquisition of InkTank (in 2014), Red Hat has become the most important contributor of Ceph, an open source project for delivering a unified storage system. In fact, Ceph is an object storage platform with integrated file and block interfaces.
Ceph can count on a vibrant and active community, with installations ranging from a few terabytes up to hundreds of petabytes. The product is very sophisticated and adaptable to several use cases (for example, recent surveys show that around 57% of OpenStack clusters are based on Ceph) but at the same time, it is complex to tune and manage, requiring higher-level skills for its administration. In previous versions it also suffered from performance issues due to the layered file system architecture but the latest major release has introduced components that can lead to higher performance. Red Hat has released a user interface (Red Hat Storage Console) to minimize the management efforts; although still limited, Red Hat is planning to increase its functionality over time.
Red Hat does not have its own solution ecosystem and leverages a long list of third-party solutions covering every possible application.
Native APIs are available alongside Swift and S3 gateways; the latter has been greatly improved in terms of compatibility but still not on par with the best solutions in the market in terms of performance.
Some hardware vendors provide pre-packaged appliances with Red Hat offering support subscriptions.
Scality RING and S3 Server
Scality, a start-up founded in 2009, has been registering top track records with large multi-petabyte installations. Many of its customers are in the range of 20+PB, but its key product (RING) has been designed for large scale deployments and not for scale down to small environments. Minimum configuration is a 6-node cluster (minimum is 200TB, but more likely between 300 and 600TB raw), which makes it challenging for small installations to adopt. Scality, in the attempt to partially solve this issue, has recently released an open source product (S3 Server) that is a much simpler, single-instance object store. S3 Server lacks the durability, availability, and reliability characteristics currently found in RING. The company’s pricing strategy for this product, however, is very good (annual subscription per node) and it has the potential to become a simple and compelling entry-level product.
The code base of S3 Server is also the same that can be found in RING, bringing one of the best levels of S3 compatibility to the market. It is noteworthy to point out that RING has a very flexible architecture that can handle objects of any size with a high number of transactions or throughput. The native scale-out NFS (and SMB) connector has also seen considerable improvement in the latest versions, a feature that is adopted by 50% of Scality customers.
Scality’s ecosystem of add-on solutions is poor but the company has been able to develop a strong network of partnerships, including hardware vendors like HP, Dell, and Cisco, as well as major software companies that can leverage object store back-ends for storing data.
RING has a comprehensive set of management APIs, but the web-based GUI is still minimal and needs improvement under every aspect. This is not a major issue in very large installations but again, it limits the usability of the product for smaller organizations. Customers generally consider their support and consulting services as favorable and responsive.
RING characteristics make the product suitable for large enterprises looking for strong back-end architecture, scalability, performance, with good internal skills for managing it all. Even though the minimum cluster could theoretically start in the order of 200-300TB, it is difficult to think customers would adopt the product for installations that are less than 600TB.
SwiftStack
SwiftStack 4.0 is a commercial product based on OpenStack Swift. The user base, although growing quickly, is still fairly limited compared to other solutions on the market, most likely due to delays in the introduction of a good S3 connector as well as NFS and SMB gateways. Swift APIs are present also but as with other vendors, not many customers are adopting it in production outside OpenStack environments. The development team is making steady progress and a scale-out NAS option should soon be included.
The product internal design shows different types of specialized nodes that can scale accordingly to user needs and can also be collapsed to a few physical nodes for smaller configurations.
SwiftStack has an extremely poor ecosystem of companion solutions with a very limited set of options, and a limited list of software partners for building enterprise ready-to-go solutions. However, there are some interesting options available: CloudSync (a tool that allows selected objects/buckets to be synced with Amazon S3), and metadata search capabilities are fairly appealing features for some use cases. It is also interesting to note that the product has been chosen by a couple of OEMs as part of the back-end for their products (Avere Systems, VMware VIO).
Even though the back-end architecture is complex, the licensing model is based on an annual subscription fee for support and the list price, on a per-capacity basis, is competitive. Another obvious benefit of the product is that it is freely downloadable, making it very easy to install and deploy in test and pre-production environments, thanks also to good documentation and an easy-to-use web UI.
Additional Vendors
We have decided to add a few more notable vendors to this research. Some of them are relevant to the market but due to the shift in their sales model or the hardware-only approach, we could not give an acceptable rating using the Disruption Vector previously identified. Others are too small and new in the market for us to come to any conclusion, but they have very innovative products that could be of interest in a relatively short period of time.
IBM Cleversafe
Cleversafe was acquired by IBM in November 2015, and it is now part of the IBM cloud division as IBM Cloud Object Storage. The product is still available; however, the IBM cloud strategy is much more focused on selling services rather than products and this has also changed the product roadmap accordingly. In fact, it is now often positioned as a competitor of Amazon AWS S3 (with Swift API support in the roadmap).
Due to the internal architecture, the minimal configuration is quite large (in the range of 500TB/1PB) and the product is designed for scale in capacity more than anything else. When the product is sold as-a-service it can start at a much smaller capacity and a free tier is avaialable for testing purposes. IBM Cloud Object Storage is improving the product in all its aspects (multi- tenancy, security, and other enterprise-focused features) but is abandoning other interfaces in favor of S3. However, there are plenty of certified third party solutions like remote NAS gateways, Sync & Share, and integration with backup systems.
The product is sold primarily as-a-service now but software licenses and pre-packaged clusters are still available. The list of customers is limited, approximately 100, but some of them are very large (hundreds of petabytes).
HGST Active Archive
The HGST Active Archive system is sold as a pre-packaged system (hardware, software, management, networking) solution and is the reason why it was not included in the Disruptive Vectors charts (where software-only solutions have been favored first).
Active Archive has one of the best erasure code implementations of the market but its rigid configuration scheme, starting at 672TB, is not appealing for SME.
The $/GB, especially in full rack (5.8PB) configurations, can be very competitive and with a very good and predictable throughput even with failed disks or nodes; it can scale-out to over 35PB.
The list of protocols and additional connectors is limited but third party solutions cover the majority of use cases.
In November 2016, HGST announced the ActiveScale P100 System, a modular object store that has a more attractive entry price. It can scale from 720TB of storage to over 19PB and runs the next generation of OS, ActiveScale OS 5.0 with increased user control and flexibility.
Minio
Minio Server is a minimalist open source S3-compatible system that has a very large and growing developer community. The product can be deployed as a single instance or in a distributed fashion; the former lacks many of the scalability and resiliency characteristics usually found in other products, but the latter is much more flexible and has the resiliency and durability of other similar products in the market. This is an ideal product for very small installations, developers, and lab testing but can be deployed and orchestrated through Containers on MesoSphere or Kubernetes, which is a very innovative way to deploy storage in cloud environments.
Noteworthy features of the product are the SDK and the set of tools for operating in S3 environments. The company has recently added AWS Lambda functionalities to the product as well as SNS/SQS-compatible event notification features.
The roadmap shows interesting evolution of the product for object content analysis through deep learning tools.
NooBaa
NooBaa is a new start-up focusing on an innovative approach for providing S3-compatible storage. In practice, it can re-use unutilized storage resources already available in the infrastructure, dedicated storage nodes as well as public cloud resources from Amazon or Google cloud services. The product separates the data plane (storage nodes and cloud resources) from the control plane; a VM controls load balancing, lod balancing, access, and security aspets.
TCO figures are very compelling and it could become a very efficient way of managing secondary storage needs, driving up efficiency of existing infrastructure while adding new services. A free evaluation license (up to 20TB) is available.
OpenIO
OpenIO is a new start-up, launched in 2015, with a solution that has been under development for nearly ten years now.
It can start very small-three nodes-and grow from there to reach multi-petabyte configurations. The back-end architecture is particularly clever with a very strong load balancing mechanism that allows the infrastructure to grow fairly quickly without the drawbacks of traditional object storage systems (like, for example, hash table rebuilds after adding new nodes).
The architecture has also allowed the company to develop Grid for Apps, a new serverless technology that can be leveraged to run specific workloads directly on the storage system.
The product is open source and offers a very attractive capacity-based subscription fee. An appliance with a very interesting ARM-based architecture and very low $/GB is also available.
OpenIO is also developing specific product add-ons for vertical markets and enterprise storage consolidation while building a partner ecosystem to provide additional solutions like Sync & Share.
Outlook and Key Takeaways
HDS comes out as the leader in terms of ecosystem and enterprise ready features but $/GB is not the best in its class. It also proposes its economy storage nodes but again, if the end user wants to build a large sustainable infrastructure for all kinds of data and workloads, this could limit freedom and agility. The solution is more suitable for relatively small environments focused on private cloud storage applications. NetApp is building a similar ecosystem and even though the solution is still not on par in terms of UI and features aimed at collaboration, it already reveals an interesting ecosystem and roadmap. It makes for a good competitor against HDS and has the potential to be more sustainable in the long term, especially for NetApp customers who can now integrate primary and secondary storage.
At the moment, Scality is the most credible solution if customers are looking for the best-of- breed in terms of scalability and high-end features. Unfortunately, the back-end architecture and lack of ease of use/deployment make the solution difficult to adopt below the 300TB range. The company has recently released a new S3 Server, a single node object storage system. This is an appealing product which can help to partially cover some enterprise use cases in the 100-300TB range but it lacks HA and resiliency features at the moment. DDN could be an alternative if high performance and scalability is the goal but the company is still very focused on HPC and a few other vertical markets, with limited partner ecosystem.
Other worthy alternatives for SMEs can be found in Cloudian and Caringo. Usability is very high, products are easy to install and manage, and they both come as software- only or pre-integrated appliances. They can start small and grow as needed, and both have a good set of certified third-party solutions. Caringo, with its FileFly and Swarm NFS solutions, can greatly ease the migration process from file-based to object-based file services. These products can be considered a suitable solution for mid-sized environments.
Open Source solutions (Ceph) are interesting in terms of total cost of acquisition (TCA) but TCO could become an issue in the long term. It is not unusual to find Ceph clusters without any form of support, for example, even though the licensing model (usually a service subscription) is reasonable when the cluster goes into production. Performance tuning can be an issue, and even though Red Hat has implemented a much-needed UI, this solution requires a wider set of skills, which are not always available.
There is no ‘one size fits all’ for object storage. But as a rule of thumb, the right platform to choose depends on the size of the end user, the amount of data to manage (also considering potential consolidation and growth), and the available skills. Looking at what usually happens in the field, we can divide the market into three segments:
• Small capacity (under 300TB): end users look for ease of use and end-to-end solutions;
• mid-size capacity(300TB-1PB): the focus is on the feature set, ease of use comes second, integration with third parties is an important factor;
• Large-size capacity (1PB+): $/GB, scalability, performance, overall efficiency, API are all at the top of the evaluation criteria.
Software-only solutions are always preferable, giving more freedom to the end user and enabling hardware and software updates to be performed separately when needed. This approach gives the end user the best solution, both from the technical and financial point of views.
Security, usually delivered through the upper layers (gateways and applications) in the past, is becoming a core component of some object storage systems and for second generation customers, it is becoming one of the most important aspects, especially when the object store is accessed natively via APIs or integrated through existing identity management systems.




 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter
