







iguazio Unveils Virtualized Data Services Architecture
Making data services and big data tools consumable for mainstream enterprises
This is a Press Release edited by StorageNewsletter.com on June 13, 2016 at 2:58 pmiguaz.io, the company challenging the status quo for big data, the IoT and cloud-native applications, unveiled its vision and architecture for data services for both private and public clouds.
This new architecture makes data services and big data tools consumable for mainstream enterprises that have been unable to harness them because of their complexity and internal IT skills gaps.
Data today is stored and moved between data silos optimized for specific applications or access patterns. The results include complex and difficult-to-maintain data lakes, constant data movement, redundant copies, the burdens of ETL (extract/transform/load), and ineffective security.
While popular cloud services like Amazon’s AWS and Microsoft’s Azure Data Lake introduce some level of simplicity and elasticity, under the hood they still move data between different data stores, lock customers in through proprietary APIs and onerous pricing schemes, and, at times, provide unpredictable performance.
Data is proliferating at an unprecedented pace – analyst firm Wikibon predicts the big data market will grow to $92.2 billion by 2026 – requiring a new paradigm for building and managing a growing and complex environment.
With its first-ever high-performance virtualized data-services architecture, iguaz.io is taking a fresh approach to big data’s challenges.
iguaz.io architecture:
- consolidates data into a high-volume, real-time data repository that virtualizes and presents it as streams, messages, files, objects or data records;
- stores al data types consistently on different memory or storage tiers;
seamlessly accelerates popular application frameworks including Spark, Hadoop, ELK, or Docker containers; - offers enterprises a 10x-to-100x improvement in time-to-insights at lower costs;
- provides best-in-class data security based on a real time classification engine, a critical need for data sharing among users and business units.
With experience in high-performance storage, networking and security, iguaz.io’s founders drew upon their combined backgrounds in designing their data stack from the ground up. They leveraged the latest technologies, bypassing traditional OSs, network, and storage bottlenecks.
“The current data pipeline, comprised of many silos and tools, is extremely complex and inefficient, resulting in long deployment cycles and slow time to insights,” said George Gilbert, lead analyst, data and analytics, Wikibon. “What will benefit the market most is a new approach that delivers multipurpose and easy-to-use data solutions rather than single-purpose tools. This will be a key factor in accelerating the adoption of big data in the enterprise.“
“Enterprises have been sharing with us their pain points and challenges around adopting big data and new analytics in their businesses,” said Asaf Somekh, co-founder and CEO, iguaz.io. “We designed our solution from the ground up to address these challenges and allow our customers to focus on their applications and business.“
Read also:
Israeli Stealthy Start-Up Iguaz.io Raises $15 Million in Series A
In data management and storage solutions for big data, IoT and cloud applications software
2015.12.11 | Press Release | [with our comments]
Comments
 Here is a comment published on June 7, 2016 on the blog of Philippe Nicolas who worked at SGI, Veritas, Symantec, Brocade and Scality, and is currently advisor for OpenIO, Infinit, Rozo Systems, Guardtime, and Solix Technologies.
Here is a comment published on June 7, 2016 on the blog of Philippe Nicolas who worked at SGI, Veritas, Symantec, Brocade and Scality, and is currently advisor for OpenIO, Infinit, Rozo Systems, Guardtime, and Solix Technologies.
Big Data Services Reinvented
Iguaz.io takes advantage of the Spark Summit in San Francisco, CA to unveil the result of active development effort for at least two years.
I had the privilege to discuss with Asaf Somekh, founder and CEO, and Yaron Haviv, founder and CTO, here about their mission and solution approach.
First a few informations about the company. Iguaz.io was founded in 2014 in Tel-Aviv, Israel, and raised so far $15 million in series A from Magma Venture partners and Jerusalem Venture Partners.
Today the company has 40+ employees all with strong background in fast networks and storage with experience at XIV, Voltaire and Mellanox to name a few.
And for the name, think about the Iguazu falls and you get the idea about the data deluge challenge the company wishes to address and solve.
The founders of the company having worked in demanding environment have realized that big data services suffer from lack of simplicity, always based on classic layers not optimized for big data processing for a complex data pipeline outcome.
Data and data tools are siloed as users and vendors finally just unified and glued without rethinking the I/O stack and think about a radical new approach to remove performance barriers and bottleneck at various points in the architecture.
Iguaz.io took this challenge super seriously to design, build and develop a new approach, perfectly aligned with big data challenges and able to be integrated with all famous big data processing tools and products.
In fact, some users have started to manage this challenge internally with lots of difficulties especially in people skills and some others refuse to deal with all this horizontal complexity of integration of data pipelining solutions (data movement, several copies, ETL and security).
So 2 solutions finally exist and of course the obvious first one is to consider Amazon AWS or Microsoft Azure approach, everything is externalized, but still complex, with unpredictable performance, not optimized with multiple copies that impact timing and above all very expensive.
The second approach is Iguaz.io who redefines all layers with only one copy, super fast pipelining capability with cost optimization in mind. The start-up realized that many computers related aspects have made significant progress over last decade but the storage software stack is still based on things linked to the HDD world. And above all, at different layers, you find piece of software doing pretty similar things, consuming lots of CPU cycles.
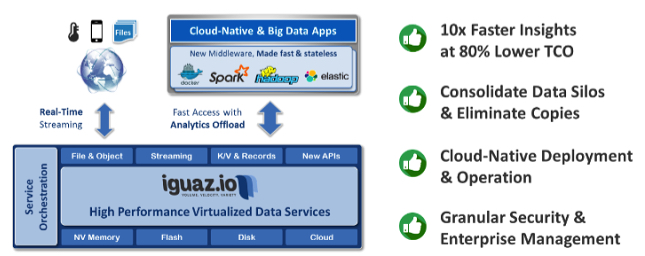
First Iguaz.io defines a common data repository with a set of data services that sit above this data lake. The solution is fully storage agnostic and provides multiple data access methods (file, objects, streams, HDFS, KV, Records, new APIs, etc.) to be integrated to now classic big data products such Hadoop, Spark or ElasticSearch. You can see the Iguaz.io product as a super fast, scalable, universal and hyper resilient access and data layer between consumers (big data applications and users) and back-end storage.
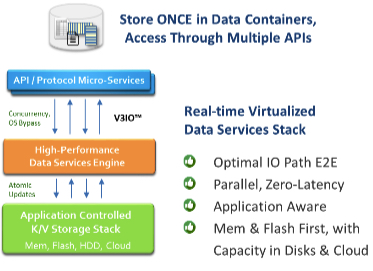
This what Iguaz.io named a 3 layered architecture with Application and APIs, Data Services, and Media:
The Applications and APIs layer is stateless, so failure resistance is delivered by nature, model is extensible and elastic, and it commits all updates to a zero-latency and concurrent storage. It is responsible to map and virtualize standard files, objects, streams, or NoSQL APIs to the common data services. Also, key in Iguaz.io approach and in big data world, changes are immediately visible in a consistent fashion.
The second step provides key data processing with inspection, indexation, compression and storage with a intelligent and efficient way on low-latency non-volatile memory or fast NVMe flash drives. Then data can be moved to the appropriate storage tier. Iguaz.io has introduced a data container notion to store objects that provides consistency, durability and availability.
The last service is the Media one with Iguaz.io K/V application-aware API mapped directly to different types of storage, including NV memory, flash, block, file, or cloud.
In term of adoption model, Iguaz.io promotes a self service approach that allows rapid deployment and production-ready systems. The company has made a significant industry progress and takes an immediate leadership in that segment without real competition.




 Subscribe to our free daily newsletter
Subscribe to our free daily newsletter
